Макрос перекодировки (изменения кодировки) текста и файлов
Содержание:
- Установка кодировки в интерфейсе Блокнота
- Инструкция по восстановлению кодировки
- Способ 1: 2cyr
- Сохранение с указанием кодировки
- Кодирование текстовой информации и таблицы кодировок
- Как определить кодировку на сайте
- Как поменять кодировку в Word. Способ первый
- Изменение кодировки в программе «Notepad ++»
- Перекодировка текста
- Почему до сих пор используется 1251
- Как сменить кодировку в консоли windows?
- Закодированные тексты на ваших сайтах
- Особенности с которыми я столкнулся
- Скалярные значения Юникода
- Что представляет собой кодировка и от чего она зависит?
- Кодирование текстовой информации и компьютеры
- Выбор кодировки при сохранении файла
Установка кодировки в интерфейсе Блокнота
Тем юзерам, кому необходимо пользоваться стандартным приложением «Блокнот» , будет полезно знать о том, что изменить кодировку можно следующим образом:
-
Открыть текстовый документ и повторно сохранить его, нажав «Файл» и затем «Сохранить как».
-
В появившемся окне помимо директории следует выбрать и кодировку, найдя необходимый формат, нажать «Сохранить».
После этого без труда можно открывать необходимый текст в нужной кодировке.
Благодаря правильно подобранной и установленной кодировке пользователь может избежать неприятностей при отправке файла другим юзерам. Все, что для этого требуется, – это выставлять перед началом работы необходимое значение.
Инструкция по восстановлению кодировки
Ситуация, когда в командной строке присутствуют непонятные символы, вопросительные знаки или иероглифы довольна распространенная.
Однако исправить положение возможно самостоятельно, не прибегая к помощи специалистов.
Сразу стоит отметить, что это первый признак того, что в седьмом Windows слетела кодировка 1251.
С восьмой версии активно используют UTF-8.
Для того, чтобы решить задачу максимально быстро, возможно использование команды CHCP 866, но это только временная мера и в полной мере проблему она не решит.
Как правило, реестр используется для основательного решения проблемы:
Способ 1: 2cyr
Онлайн-сервис 2cyr поддерживает практически все популярные кодировки, а также позволяет исправить запись разными способами в зависимости от известной о кодировке информации. Для преобразования текста в читабельный вид при помощи данного сайта осуществите следующие действия:
- Воспользуйтесь ссылкой выше, чтобы открыть главную страницу сайта 2cyr. Кликните по соответствующему полю для его активации.
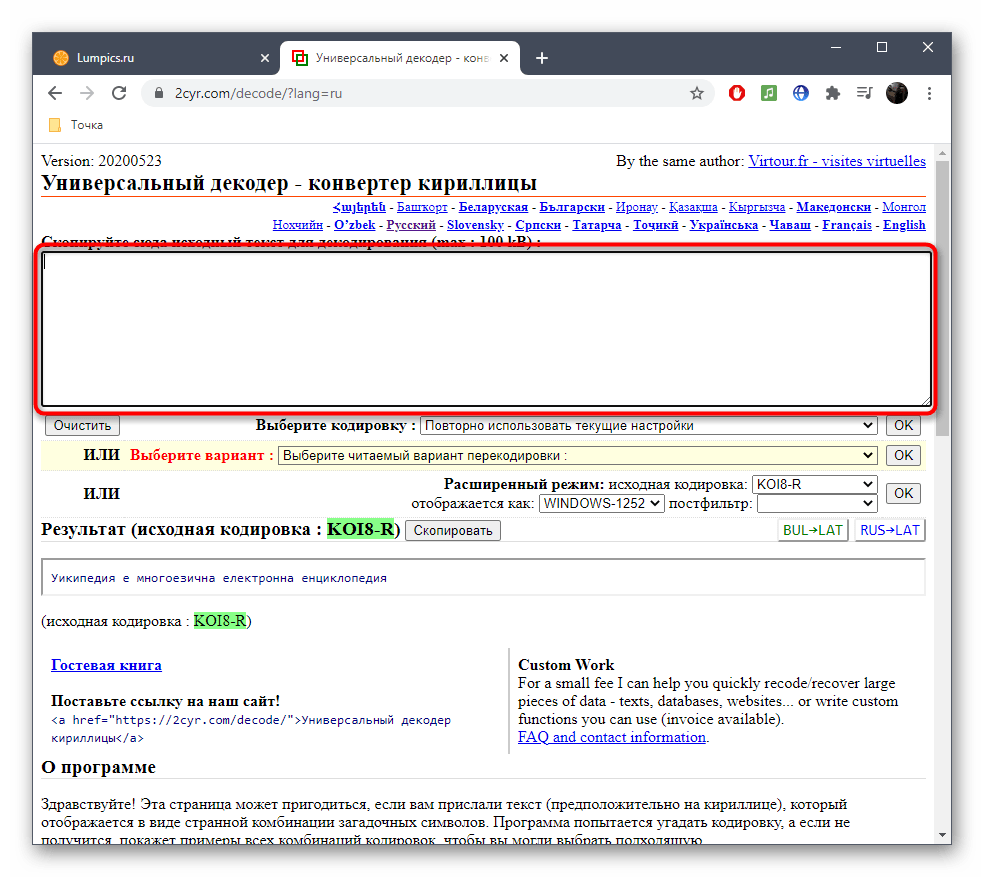
Скопируйте текст в неверной кодировке и вставьте его в данное поле. Для этого можно использовать стандартные сочетания клавиш Ctrl + C и Ctrl + V.
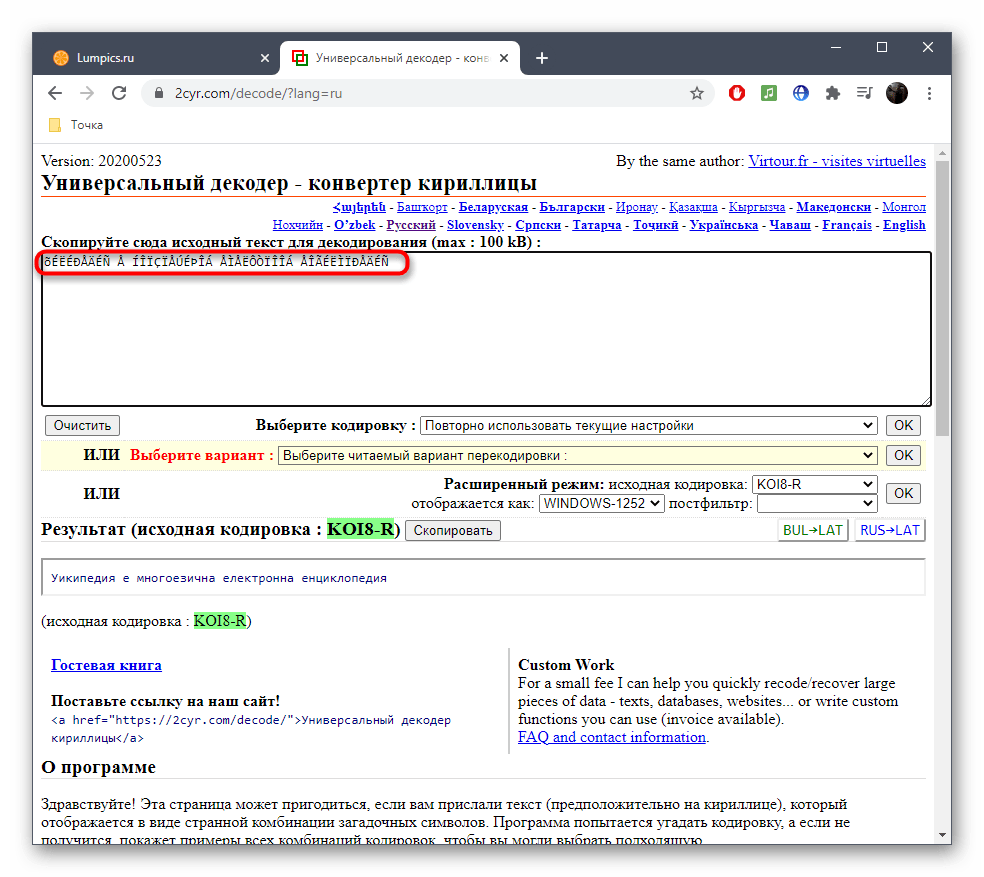
Если известен формат поврежденной кодировки, его можно сразу же выбрать в отдельном меню, чтобы получить правильное исправление.
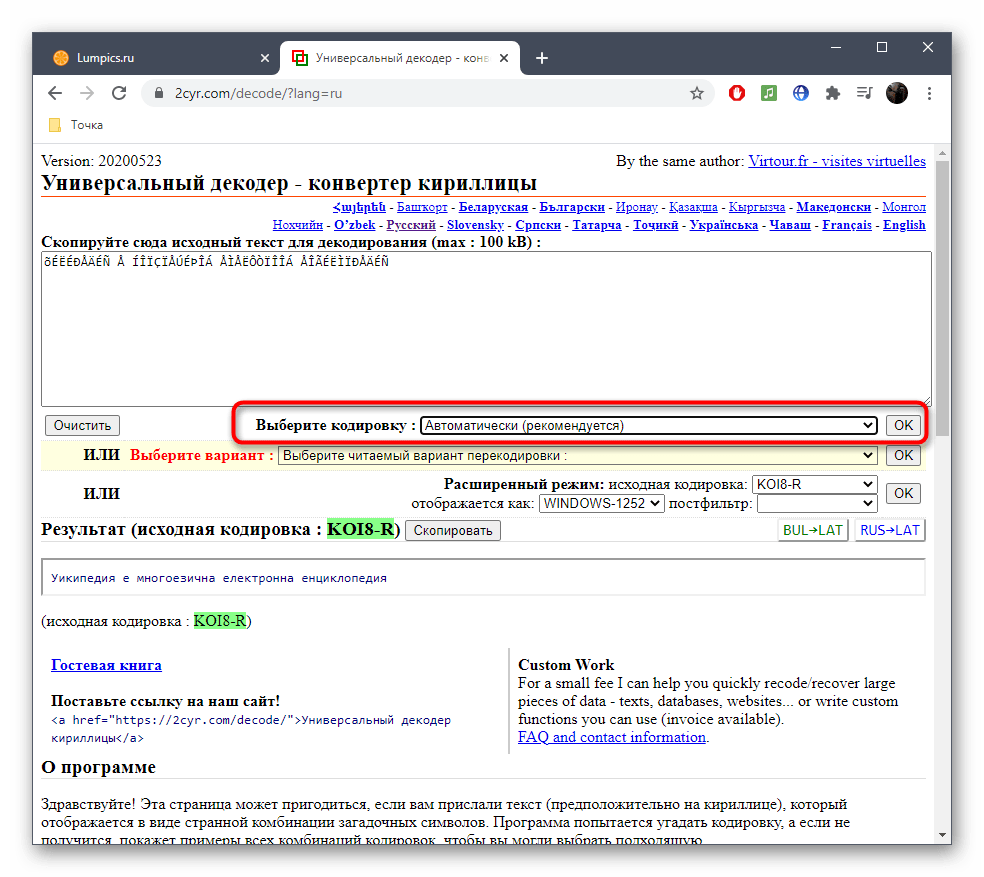
Второй вариант декодирования подразумевает просмотр результата на всех присутствующих в онлайн-сервисе кодировках. Для этого надо развернуть выпадающее меню и найти там читаемый вариант.
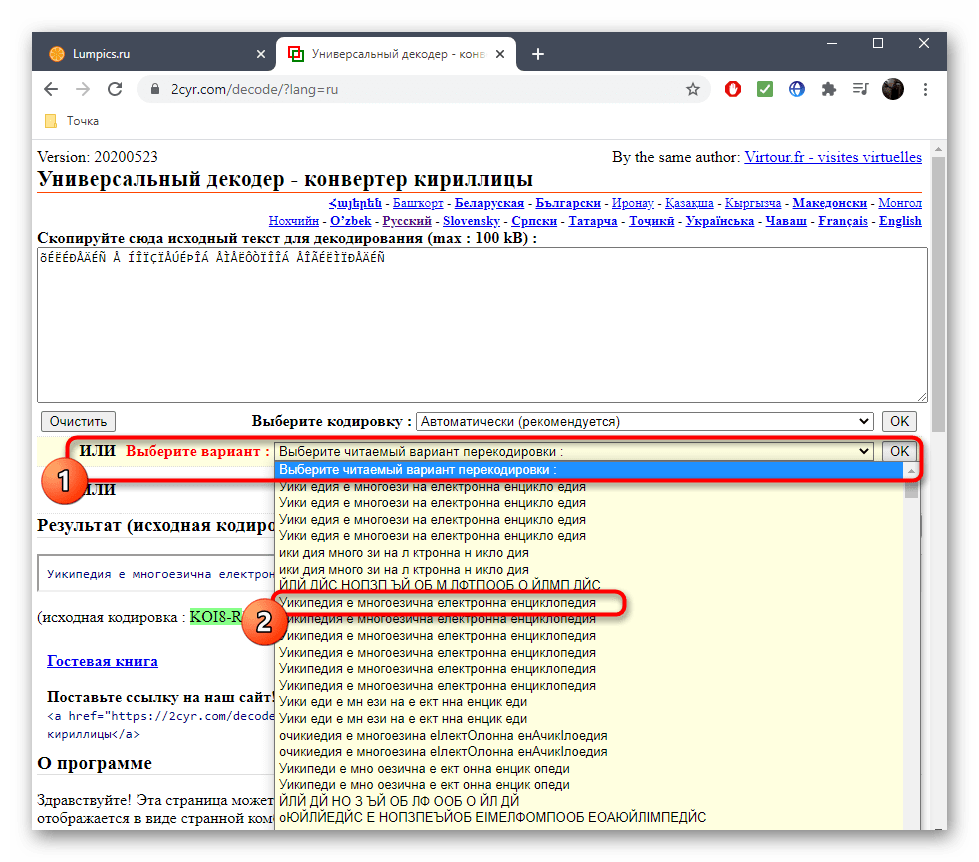
После этого подтвердите свой выбор, кликнув «ОК», ведь только так можно скопировать готовый текст.
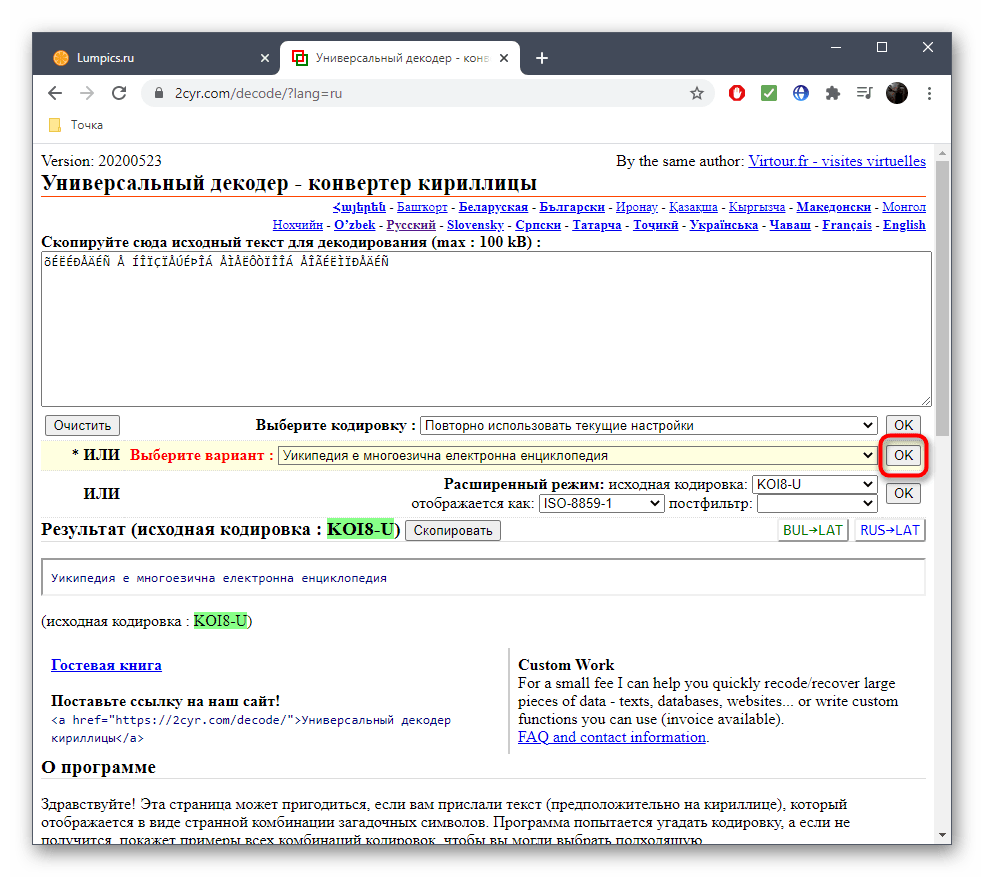
Он будет отображаться внизу и доступен для копирования. Выделите его зажатой левой кнопкой мыши и используйте упомянутые выше комбинации, чтобы скопировать и вставить в необходимый текстовый документ.
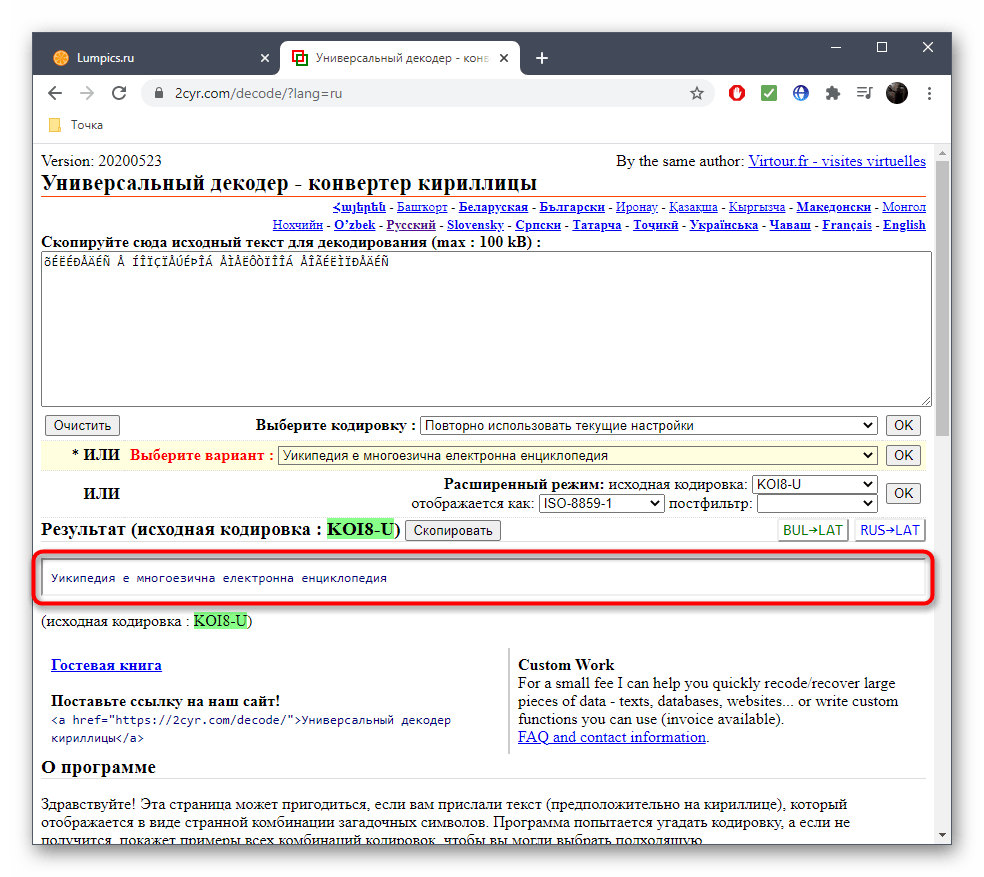
Исходную кодировку вы видите выше — она отмечена зеленым цветом. Иногда это нужно пользователям при ее декодировании.
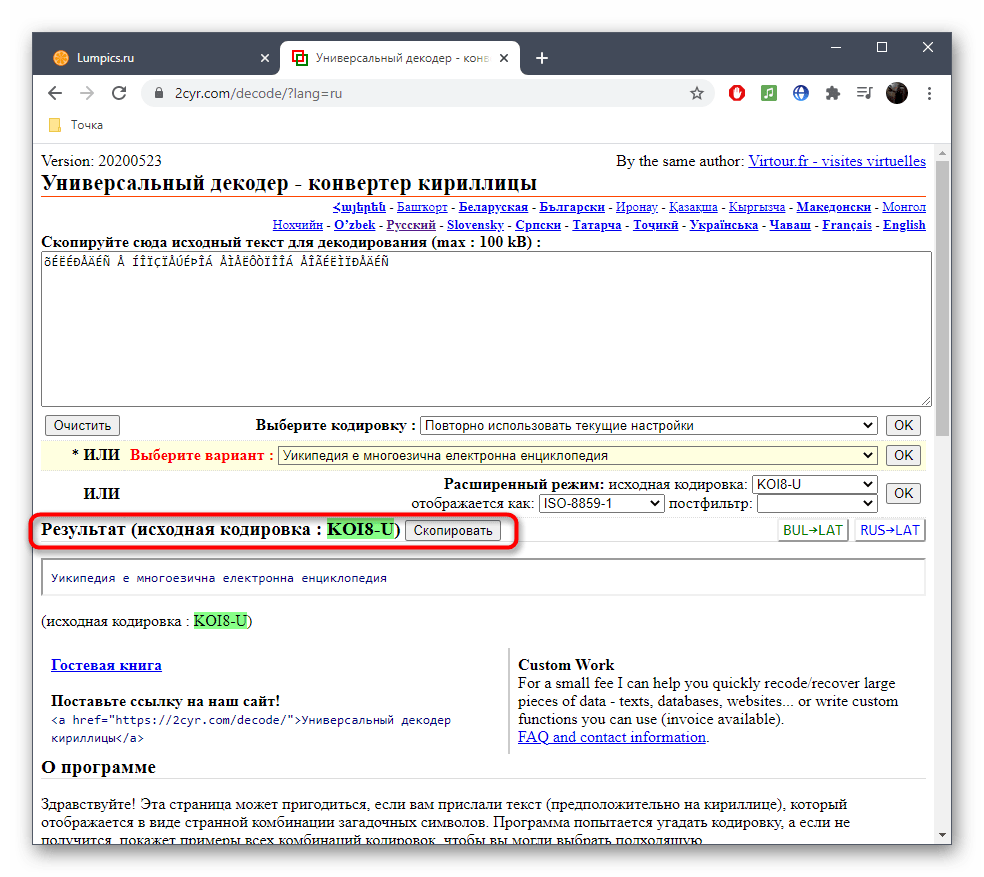
Данный сайт корректно исправляет любую кодировку, которая есть в списке поддерживаемых, поэтому вы можете взять его на вооружение и использовать в любой момент по необходимости.
Сохранение с указанием кодировки
У пользователя может возникнуть ситуация, когда он специально указывает определённую кодировку. Например, такое требование ему предъявляет получатель документа. В этом случае нужно будет сохранить документ как обычный текст через меню «Файл». Смысл в том, что для заданных форматов в Ворде есть привязанные глобальными кодировки, а для «Обычного текста» такой связи не установлено. Поэтому Ворд предложит самостоятельно выбрать для него кодировку, показав уже знакомое нам окно преобразования документа. Выбирайте для него нужную вам кодировку, сохраняйте, и можно отправлять или передавать этот документ. Как вы понимаете, конечному получателю нужно будет сменить в своём текстовом редакторе кодировку на такую же, чтобы прочитать ваш текст.

Кодирование текстовой информации и таблицы кодировок
Таблица кодировки — это место, где прописано какому символу какой код относится. Все таблицы кодировки являются согласованными — это нужно, чтобы не возникало путаницы между документами, закодированными по одной таблице, но на разных устройствах.
На сегодняшний день существует множество таблиц кодировок. Из-за этого часто возникают проблемы с переносом текстовых документов между устройствами. Так получается, что если текстовая информация была закодирована по одной какой-то таблице, то и раскодирована она может быть только по этой таблице. Если попытаться раскодировать другой таблицей, то в результате получим только набор непонятных символов, но никак не читабельный текст.
Наиболее популярные таблицы кодировки:
- ASCII,
- MS-DOS,
- ISO,
- Windows,
- КОИ8,
- CP866,
- Mac,
- CP 1251,
- Unicode,
- и др.
Как определить кодировку на сайте
Определить кодировку страницы своего или чужого сайта можно через исходный код страницы. Откройте страницу сайта, выберите «Просмотр кода страницы» (сочетание горячих клавиш Ctrl+U» в Google Chrome) и найдите упоминание «charset» внутри тега head.
На странице сайта используется кодировка UTF-8:
Указание кодировки в коде страницы
Узнать вид кодирования можно с помощью «Анализа сайта». Сервис проверяет в том числе и техническую сторону ресурса: анализирует серверную информацию, определяет кодировку, проверяет редиректы и другие пункты.
Фрагмент анализа серверной информации сайта
С помощью этого же сервиса можно проверить корректность указанного кодирования. Аудит внутренних страниц «Анализа сайта» проверяет кодировку сервера и сравнивает ее с той, которая указана на внутренней странице. Найденные ошибки Анализ покажет в результатах проверки, и вы сразу узнаете, где нужно исправить.
Отчет о технических данных
Кодировка сервера и страницы
Проверить кодировку еще можно через сервис Validator.w3, о котором писали в статье о проверке валидации кода. Нужная надпись находится внизу страницы.
Кодировка сайта в валидаторе
Если валидатор не обнаружит Charset, он покажет ошибку:
Ошибка указания кодировки
Но валидатор работает не точно: он проверяет только синтаксис разметки, поэтому может не показать ошибку, даже если кодирование указано неправильно.
Как поменять кодировку в Word. Способ первый
После того, как этому явлению было дано определение, можно переходить непосредственно к тому, как поменять кодировку в Word. Первый способ можно осуществить при открытии файла в программе.
В том случае, когда в открывшемся файле вы наблюдаете набор непонятных символов, это означает, что программа неверно определила кодировку текста и, соответственно, не способна его декодировать. Все, что нужно сделать для корректного отображения каждого символа, — это указать подходящую кодировку для отображения текста.
Говоря о том, как поменять кодировку в Word при открытии файла, вам необходимо сделать следующее:
- Нажать на вкладку «Файл» (в ранних версиях это кнопка «MS Office»).
- Перейти в категорию «Параметры».
- Нажать по пункту «Дополнительно».
- В открывшемся меню пролистать окно до пункта «Общие».
- Поставить о.
- Нажать»ОК».
Итак, полдела сделано. Скоро вы узнаете, как поменять кодировку текста в Word. Теперь, когда вы будете открывать файлы в программе «Ворд», будет появляться окно. В нем вы сможете поменять кодировку открывающегося текста.
Выполните следующие действия:
- Откройте двойным кликом файл, который необходимо перекодировать.
- Кликните по пункту «Кодированный текст», что находится в разделе «Преобразование файла».
- В появившемся окне установите переключатель на пункт «Другая».
- В выпадающем списке, что расположен рядом, определите нужную кодировку.
- Нажмите «ОК».
Если вы выбрали верную кодировку, то после всего проделанного откроется документ с понятным для восприятия языком. В момент, когда вы выбираете кодировку, вы можете посмотреть, как будет выглядеть будущий файл, в окне «Образец». Кстати, если вы думаете, как поменять кодировку в Word на MAC, для этого нужно выбрать из выпадающего списка соответствующий пункт.
Изменение кодировки в программе «Notepad ++»
Подобное приложение используется многими программистами для создания сайтов, различных приложений и многого другого
Поэтому очень важно сохранять и создавать файлы, используя необходимую кодировку. Для того, чтобы настроить нужный вариант для пользователя, следует:
Шаг 1. Запустить программу и в верхнем контекстном меню выбрать вкладку «Кодировки».
Выбираем вкладку «Кодировки»
Шаг 2. В выпадающем списке пользователю требуется выбрать из списка необходимую для него кодировку и щелкнуть на нее.
Выбираем из списка необходимую кодировку, щелкаем на ней
Шаг 3
Правильность проведения процедуры легко проверить, обратив внимание на нижнюю панель программы, которая будет отображать только что измененную кодировку
В нижней панели программы можно увидеть измененную кодировку
Перекодировка текста
К сожалению, в разных версиях Word необходимые действия для изменения кодировки различны, хотя и ведут к одинаковому результату. Рассмотрим подробнее необходимые шаги для разных версий в отдельности:
Word 2003
Для того, что бы сменить кодировку, зайдите в меню и выберите СЕРВИС, а затем ПАРАМЕТРЫ. После этого в разделе ЗАКЛАДКА –Общие подтверждаем преобразование при открытии. Теперь при каждом следующем открытии текстового файла, будет предоставлена возможность выбора системы кодирования;
Word 2010, 2007
Эти версии в плане изменения шрифтов ничем не отличаются. В главном меню через ФАЙЛ заходим в ПАРАМЕТРЫ. В новом, выпадающем, окне выбираем раздел ДОПОЛНИТЕЛЬНО и в самом низу окна у Вас будет возможность «разметить документ так, будто он создан … ». Вам будут представлена возможность и создавать, и читать документы в нужном формате.

Почему до сих пор используется 1251
Существует несколько причин, почему 1251 продолжает пользоваться большой популярностью среди разработчиков онлайн ресурсов:
Ввод специальных символов в документах системы windows
- Многие программисты php используют стандартную кодировку, поскольку OC Windows ее поддерживает в режиме по умолчанию. И хотя в последнее время разработчики стали активно внедрять UTF-8, все же 1251 пока не сдает свои активные позиции
- Если брать для примера старую версию MySQL до четвертой, то стоит отметить, что при включении даже тестового режима, вылезало множество ошибок в UTF-8. Только после выпуска 4.1 многие «глюки» были исправлены. Существует категория программистов, которая вовсе остается верна 1251, а их последователи рьяно берут с них пример и даже не собираются использовать нечто другое
- Поскольку один символ в системе 1251 весит меньше (один байт), то вполне логично, что возникает некая экономия в отличие от последнего варианта.
По сравнению с данной кодировкой, UTF-8 считается более оптимальным вариантом, поскольку она может распознать большее количество символов.
- Возможно включение любых знаков из набора Юникода. Кроме того, вполне логично, что здесь поддерживается 100 000 символов против 256. Здесь можно найти от стандартных смайликов до апострофа абсолютно все. Их использование возможно в любом документе. Кроме того, их можно прочитать даже в редакторе, что исключает вероятность появления нечитабельных знаков
- Ранее существовало мнение о том, что современный utf занимает больше места. В итоге оказалось, что символы также весят всего лишь байт. Значит, стоит сделать вывод о том, что увеличение веса странички не происходит и ее использование такое же легкое. Однако, если используется только русский алфавит, то в таком случае размер будет увеличен вдвое, поскольку изначально кириллица не включена в систему
- Система считается одной из самых универсальных, которые уже смогли достать. В таком случае можно создавать сайты для любого населения мира. Можно уже не думать о том, какая кодировка используется, поскольку Юникод является универсальной вещью
- UTF – это оптимальный вариант работы с php страницами.
Важно отметить, что изначально многие разработчики стали использовать 1251. И хотя сейчас тенденции поменялись, последователей именно этой кодировки осталось, а значит она продолжает пользоваться большой популярностью среди пользователей. ,
,
И хотя сейчас тенденции поменялись, последователей именно этой кодировки осталось, а значит она продолжает пользоваться большой популярностью среди пользователей. ,
Кто-то считает, что универсальная utf – это неплохое решение, которое устанавливается для современных ресурсов, но 1251 – это проверенный алгоритм для стран, использующих кириллицу.
Стоит отметить, что в большинстве случаев используют автоматические переключение. Так, например, если понадобится прочитать информацию на иностранном языке или на русском, достаточно просто переключить кодировку на актуальный формат.
Вероятно, что в будущем 1251 станет еще меньше востребованной, а на смену придут новые проверенные системы. Однако сегодня многие все же используют именно ее.
Также важно принять на заметку, что для работы с utf знание английского языка является обязательным условием
Как сменить кодировку в консоли windows?
Файл должен выводиться в utf-8, а в консоли – 866, в итоге в браузере отображаются ромбы.
После команды chcp 65001 ничего не поменялось.
Но у меня в CodePage таких файлов нет. Есть типы REG.SZ по умолчанию и 4 файла с номерами 932 936 949 950
Вариант постоянно изменять в консоли chcp не подходит, но и не работает. Lucida console подключен в консоли. Cygwin64 Terminal и Gitbash не запускает python server
Какие-то ещё есть варианты?
generate.py
horoscope.py
При запуске кода (python generate_all.py из командной строки или Ctrl B в саблайме) в этой же папке генерируется файл index.html, и, если поднять сервер в этой же директории (python -m http.server) из консоли win, то в браузере ромбы.
Закодированные тексты на ваших сайтах
Так как вычислительные системы понимают только переведённый в цифры текст, один и тот же материал в разных кодировках будет выглядеть для них по-разному. Эта особенность используется некоторыми для плагиата. Всё ещё есть роботы, проверяющие уникальность, которые могут не отличить текст с непривычной им кодировкой. Но если его скопировать в блокнот, он станет нечитабельным или обрастет лишними символами.
Браузер воспринимает текст сайта тоже через кодировку. Если она будет неправильно подобрана, вместо текста будут вопросы или непонятные знаки. Кодировка задается в head, в теге. В кавычках может быть любой стандарт, но utf-8 самый распространенный из них. Поэтому для своих русскоязычных проектов используйте её. Тогда ваши сайты будут корректно отображаться в любом браузере.
Чтобы детальнее разобраться с особенностями кодировки для вашего сайта, смотрите видеоуроки. В них наглядно разбираются вероятные проблемы и их решения. На портале у Михаила Русакова есть целый ряд таких уроков. Там можно найти ответы на множество вопросов по верстке сайтов.
А то, что уже умеете, сможете делать качественнее и быстрее, учась у профессионалов. Все уроки вы сможете сохранить в компьютере, просматривая при необходимости снова.
Подписывайтесь на обновления моего блога, чтобы не пропустить самое интересное. Также добавляйтесь в мою группу Вконтакте, где свежие дублируются свежие обновления. Так вы сможете видеть их прямо в своей ленте новостей.
Особенности с которыми я столкнулся
Чуть коснусь прелестей и проблем связанных с golang. Раздел может быть интересен только начинающим писать на golang.
Проблемы
Лично походил по некоторым подводным камушкам из 50 оттенков Go: ловушки, подводные камни и распространённые ошибки новичков.
Что делать если интерфейс является входным параметром нашей функции? Например если мы принимаем io.Reader, проверить его на nil ведь надо. Проверить на существование переменной типа io.Reader мне удалось только с помощью рефлексии.
Разок наступил на грабли с передачей массивов по значению. Немного тупанул на попытке изменять элементы хранящиеся в map пробегая по ним в range…
Прелести
Сложно сказать что конкретно, постоянное ли битьё по рукам от линтера и компилятора или активное использование range, или всё вместе, но практически отсутствуют залёты по выходу индекса за пределы.
Конечно очень приятно жить со сборщиком мусора. Полагаю мне ещё предстоит освоить грабли автоматизации выделения/освобождения памяти, но пока дебильная улыбка не покидает лица.
Строгая типизация — тоже кусочек счастья.
Переменные имеющие тип функции — соответственно лёгкая реализация различного поведения у однотипных объектов.
Странно мало пришлось сидеть в отладчике, перечитывание кода обычно быстро давало результат.
Щенячий восторг от наличия массы инструментов из коробки, это чудное ощущение когда компилятор, язык, библиотека и IDE Visual Studio Code работают на тебя вместе, слаженно.
Скалярные значения Юникода
Термин относится ко всем кодовым точкам, кроме суррогатных. Другими словами, скалярное значение — это любая кодовая точка, которой присвоен символ или которой может быть присвоен символ в будущем. Слово «символ» здесь относится ко всему, что может быть назначено кодовой точке, включая действия, которые определяют способ отображения текста или символов.
На приведенной ниже схеме показаны точки кода скалярного значения.
Тип Rune как скалярное значение
Начиная с версии .NET Core 3.0, тип System.Text.Rune представляет скалярное значение Юникода. Тип недоступен в .NET Core 2.x или .NET Framework 4.x.
Конструкторы проверяют, является ли полученный экземпляр допустимым скалярным значением Юникода. В противном случае они создают исключение. В следующем примере показан код, который создает экземпляры , так как входные данные представляют допустимые скалярные значения:
В следующем примере создается исключение, так как кодовая точка находится в суррогатном диапазоне и не является частью суррогатной пары:
В следующем примере создается исключение, так как кодовая точка находится за пределами дополнительного диапазона:
Пример использования Rune: изменение регистра букв
API, который принимает и предполагает, что работает с кодовой точкой, которая является скалярным значением, работает неправильно, если принадлежит суррогатной паре. Например, рассмотрим следующий метод, который вызывает Char.ToUpperInvariant для каждого экземпляра char в string:
Если string содержит строчную букву дезерет (), этот код не преобразует ее в прописную букву (). Код вызывает отдельно для каждой суррогатной кодовой точки и . Однако в самой кодовой точке информации недостаточно, чтобы идентифицировать ее как строчную букву. Таким образом оставляет ее как есть. И таким же образом обрабатывает . В результате буква «𐑉» нижнего регистра в string не преобразуется в букву «𐐡» верхнего регистра.
Вот два варианта правильного преобразования string в верхний регистр:
-
Вызовите String.ToUpperInvariant для входного экземпляра string, а не в итерации -by-. Метод имеет доступ к обеим частям каждой суррогатной пары, поэтому он может правильно обрабатывать все кодовые точки Юникода.
-
Выполните итерацию скалярных значений Юникода в качестве экземпляров , а не экземпляров , как показано в следующем примере. Так как экземпляр является допустимым скалярным значением Юникода, его можно передать в API-интерфейсы, которые должны работать со скалярным значением. Например, вызвав Rune.ToUpperInvariant, как показано в следующем примере, вы получите правильные результаты:
Другие API-интерфейсы Rune
Тип предоставляет аналоги многих API-интерфейсов . Например, приведенные ниже методы отражают статические API-интерфейсы для типа :
- Rune.IsLetter
- Rune.IsWhiteSpace
- Rune.IsLetterOrDigit
- Rune.GetUnicodeCategory
Чтобы получить необработанное скалярное значение из экземпляра , используйте свойство Rune.Value.
Чтобы преобразовать экземпляр обратно в последовательность типов , используйте метод Rune.ToString или Rune.EncodeToUtf16.
Так как любое скалярное значение Юникода может быть представлено одним экземпляром или суррогатной парой, любой экземпляр может быть представлен не более чем двумя экземплярами . Используйте Rune.Utf16SequenceLength, чтобы узнать количество экземпляров , требуемых для представления экземпляра .
Дополнительные сведения о типе .NET см. в справочнике по API для .
Что представляет собой кодировка и от чего она зависит?
Для каждого региона кодировка может в значительной степени разниться. Для понимания кодировки необходимо знать то, что информация в текстовом документе сохраняется в виде некоторых числовых значений. Персональный компьютер самостоятельно преобразует числа в текст, используя при этом алгоритм отдельно взятой кодировки. Для стран СНГ используется кодировка файлов с названием «Кириллица», а для других регионов, таких как Западная Европа, применяется «Западноевропейская (Windows)». Если текстовый документ был сохранен в кодировке кириллицы, а открыт с использованием западноевропейского формата, то символы будут отображаться совершенно неправильно, представляя собой бессмысленный набор знаков.
При открытии документа, сохраненного одним типом кодировки, в другом формате кодировки невозможно будет прочитать
Во избежание недоразумений и облегчения работы разработчики внедрили специальную единую кодировку для всех алфавитов – «Юникод». Этот общепринятый стандарт кодировки содержит в себе практически все знаки большинства письменных языков нашей планеты. К тому же он преобладает в интернете, где так необходима подобная унификация для охвата большего количества пользователей и удовлетворения их потребностей.
Тип кодировок, которые используются, как стандартные для всех языков
«Word 2013» работает как раз на основе Юникода, что позволяет обмениваться текстовыми файлами без применения сторонних программ и исправления кодировок в настройках. Но нередко пользователи сталкиваются с ситуацией, когда при открытии вроде бы простого файла вместо текста отображаются только знаки. В таком случае программа «Word» неправильно определила существующую первоначальную кодировку текста.
Кодирование текстовой информации и компьютеры
Если смотреть на текст глазами компьютера, то в тексте нет предложений, абзацев, заголовков и т. д., потому что весь текст просто состоит из отдельных символов. Причем символами будут являться не только буквы, но и цифры, и любые другие специальные знаки (+, -,*,= и т. д.). Что самое интересное, даже пробелы, перенос строки и табуляция — для компьютера это тоже отдельные символы.
Для справки. Есть уникальный язык программирования, который в качестве своих операторов использует только пробелы, табуляции и переносы строки. Практического применения этот язык не имеет, но он есть.
Мы вводим текст в компьютер при помощи клавиатуры, символы которой мы прекрасно понимаем. Нажимая на какую-то букву, мы отправляем в оперативную память компьютера двоичное представление нажатых клавиш. Каждый отдельный символ будет представлен 8-битной кодировкой. Например буква «А» — это «11000000». Получается, что один символ — это 1 байт или 8 бит. При такой кодировке, путем нехитрых подсчетов можно посчитать, что мы можем зашифровать 256 символов. Для кодирования текстовой информации данного количества символов более чем предостаточно.
Кодирование текстовой информации в компьютерных устройствах сводится к тому, что каждому отдельному символу присваивается уникальное десятичное значение от 0 и до 255 или его эквивалент в двоичной форме от 00000000 и до 11111111. Люди могут различать символы по их внешнему виду, а компьютерное устройство только по их уникальному коду.
Рассмотрите, как происходит процесс. Мы нажимаем нужный нам символ на клавиатуре, ориентируясь на их внешний вид. В оперативную память компьютера он попадает в двоичном представлении, а когда компьютер его выводит нам на экран, то происходит процесс декодирования, чтобы мы увидели знакомый нам символ.

Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке «Китайская традиционная (Big5)». В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание:
Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке «Кириллица (Windows)», текст на иврите не отобразится, а если сохранить его в кодировке «Иврит (Windows)», то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Выбор кодировки
Откройте вкладку Файл
.
В поле Имя файла
введите имя нового файла.
В поле Тип файла
выберите Обычный текст
.
Если появится диалоговое окно Microsoft Office Word — проверка совместимости
, нажмите кнопку Продолжить
.
В диалоговом окне Преобразование файла
выберите подходящую кодировку.
Чтобы использовать стандартную кодировку, выберите параметр Windows (по умолчанию)
.
Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS
.
Чтобы задать другую кодировку, установите переключатель Другая
и выберите нужный пункт в списке. В области Образец
можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание:
Чтобы увеличить область отображения документа, можно изменить размер диалогового окна Преобразование файла
.
Если появилось сообщение «Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке», можно выбрать другую кодировку или установить флажок Разрешить подстановку знаков
.
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк
и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в поле Завершать строки
.