[в закладки] bash для начинающих: 21 полезная команда
Содержание:
- Grep IP-адреса
- Conclusion
- Как мне использовать grep для поиска файла в Linux?
- Grep несколько шаблонов
- Checking for the given string in multiple files.
- Примеры команды grep в Linux и Unix
- Match regular expression in files
- 1.3, найди и xargs
- 2. Команда grep
- Использование sed в Linux
- Примеры использования find
- con GREP найдем любой текст в любом файле
- 2.1, общие параметры и примеры команды grep
- 4.2.2. Grep and regular expressions
- Примеры использования
- Регулярные выражения Linux
- Character classes and bracket expressions
- Квантификаторы
- Почему мы используем grep?
Grep IP-адреса
Greping для IP-адресов может быть немного сложным, потому что мы не можем просто сказать, что grep ищет 4 числа, разделенных точками — ну, мы могли бы, но эта команда также может вернуть недопустимые IP-адреса.
Следующая команда найдет и изолирует только действительные адреса IPv4 :
$ grep -E -o "(25|2|??)\.(25|2|??)\.(25|2|??)\.(25|2|??)" /var/log/auth.log
Мы использовали это на нашем сервере Ubuntu только для того, чтобы увидеть, откуда были сделаны последние попытки SSH.
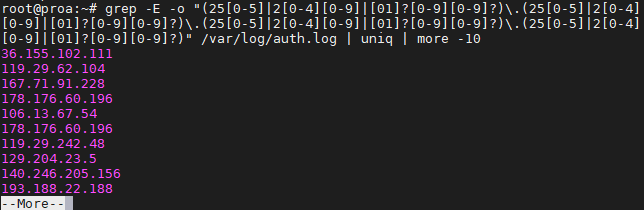
Чтобы избежать повторной информации и захламления вашего экрана, вы можете направить ваши команды grep в «uniq» и «more», как мы делали на скриншоте выше.
Conclusion
is useful in finding patterns within files or within the file system hierarchy, so it’s worth spending time getting comfortable with its options and syntax.
Regular expressions are even more versatile, and can be used with many popular programs. For instance, many text editors implement regular expressions for searching and replacing text.
Furthermore, most modern programming languages use regular expressions to perform procedures on specific pieces of data. Once you understand regular expressions, you’ll be able to transfer that knowledge to many common computer-related tasks, from performing advanced searches in your text editor to validating user input.
Как мне использовать grep для поиска файла в Linux?
Найдите /etc/passwd для пользователя boo, введите:
Примеры выходных данных::
foo:x:1000:1000:boo,,,:/home/boo:/bin/ksh
Мы можем использовать fgrep/grep тобы найти все строки файла, содержащие определенное слово. Например, чтобы перечислить все строки файла с именем address.txt в текущем каталоге, которые содержат слово “California” выполните:
Обратите внимание, что приведенная выше команда также возвращает строки, в которых “California” является частью других слов, например “Californication” или “Californian”. Следовательно, передайте -w параметр с помощью команды grep/fgrep чтобы получить только строки, в которых “California” включено как целое слово:
Вы можете заставить grep игнорировать регистр слов, то есть сопоставить boo, Boo, BOO и все другие комбинации с -i параметром. Например, введите следующую команду:. Последнийgrep -i «boo» /etc/passwd
 Последнийgrep -i "boo" /etc/passwd
Последнийgrep -i "boo" /etc/passwd
Grep несколько шаблонов
GNU поддерживает три синтаксиса регулярных выражений: базовый, расширенный и Perl-совместимый. Если тип регулярного выражения не указан, интерпретирует шаблоны поиска как базовые регулярные выражения.
Для поиска нескольких шаблонов используйте оператор OR (чередование).
Оператор чередования (pipe) позволяет вам указать различные возможные совпадения, которые могут быть буквальными строками или наборами выражений. Этот оператор имеет самый низкий приоритет среди всех операторов регулярных выражений.
Синтаксис поиска нескольких шаблонов с использованием базовых регулярных выражений следующий:
Всегда заключайте регулярное выражение в одинарные кавычки, чтобы избежать интерпретации и расширения метасимволов оболочкой.
При использовании основных регулярных выражений метасимволы интерпретируются как буквальные символы. Чтобы сохранить особые значения метасимволов, они должны быть экранированы обратной косой чертой ( ). Вот почему мы избегаем оператора ИЛИ ( ) косой чертой.
Чтобы интерпретировать шаблон как расширенное регулярное выражение, вызовите с параметром (или ). При использовании расширенного регулярного выражения не избегайте символа оператор:
Для получения дополнительной информации о том, как создавать регулярные выражения, ознакомьтесь с нашей статьей Grep regex .
Checking for the given string in multiple files.
Syntax: grep "string" FILE_PATTERN
This is also a basic usage of grep command. For this example, let us copy the demo_file to demo_file1. The grep output will also include the file name in front of the line that matched the specific pattern as shown below. When the Linux shell sees the meta character, it does the expansion and gives all the files as input to grep.
$ cp demo_file demo_file1 $ grep "this" demo_* demo_file:this line is the 1st lower case line in this file. demo_file:Two lines above this line is empty. demo_file:And this is the last line. demo_file1:this line is the 1st lower case line in this file. demo_file1:Two lines above this line is empty. demo_file1:And this is the last line.
Примеры команды grep в Linux и Unix
Ниже приведены некоторые стандартные команды grep, объясненные с примерами, которые помогут вам начать работу с grep в Linux, macOS и Unix:
- Найдите любую строку, которая содержит слово в имени файла в Linux: grep 'word' filename
- Выполните поиск слова ‘bar’ без учета регистра в Linux и Unix: grep -i 'bar' file1
- Найдите все файлы в текущем каталоге и во всех его подкаталогах в Linux по слову httpd: grep -R 'httpd' .
- Найдите и отобразите общее количество раз, когда строка ‘nixcraft’ появляется в файле с именем frontpage.md:: grep -c 'nixcraft' frontpage.md
Давайте подробно рассмотрим все команды и параметры.
Синтаксис
Синтаксис grep следующий:
grep 'word' filename fgrep 'word-to-search' file.txt grep 'word' file1 file2 file3 grep 'string1 string2' filename cat otherfile | grep 'something' command | grep 'something' command option1 | grep 'data' grep --color 'data' fileName grep -options pattern filename fgrep -options words file |
grep ‘word’ filename
fgrep ‘word-to-search’ file.txt
grep ‘word’ file1 file2 file3
grep ‘string1 string2’ filename
cat otherfile | grep ‘something’
command | grep ‘something’
command option1 | grep ‘data’
grep —color ‘data’ fileName
grep pattern filename
fgrep words file
Match regular expression in files
Syntax: grep "REGEX" filename
This is a very powerful feature, if you can use use regular expression effectively. In the following example, it searches for all the pattern that starts with «lines» and ends with «empty» with anything in-between. i.e To search «linesempty» in the demo_file.
$ grep "lines.*empty" demo_file Two lines above this line is empty.
From documentation of grep: A regular expression may be followed by one of several repetition operators:
- ? The preceding item is optional and matched at most once.
- * The preceding item will be matched zero or more times.
- + The preceding item will be matched one or more times.
- {n} The preceding item is matched exactly n times.
- {n,} The preceding item is matched n or more times.
- {,m} The preceding item is matched at most m times.
- {n,m} The preceding item is matched at least n times, but not more than m times.
1.3, найди и xargs
При использовании параметра -exec команды find для обработки сопоставленных файлов команда find передает все сопоставленные файлы в exec для выполнения. Однако некоторые системы имеют ограничения по длине команд, которые могут быть переданы в exec, так что ошибка переполнения произойдет после того, как команда find выполняется в течение нескольких минут. Обычно это сообщение об ошибке «слишком длинный столбец параметров» или «переполнение столбцов параметров». Здесь полезна команда xargs, особенно когда она используется с командой find.
Команда find передает сопоставленные файлы команде xargs, а команда xargs одновременно получает только часть файлов, а не все, в отличие от параметра -exec. Таким образом, он может обработать первую часть файла, затем следующий пакет и т. Д.
В некоторых системах использование параметра -exec инициирует соответствующий процесс для обработки каждого сопоставленного файла вместо одновременного выполнения всех сопоставленных файлов в качестве параметров, поэтому в некоторых случаях будет слишком много процессов. Проблема снижения производительности, поэтому эффективность не высокая;
С помощью команды xargs существует только один процесс. Кроме того, при использовании команды xargs, получать ли все параметры сразу или в пакетном режиме, и количество параметров, полученных каждый раз, будет определяться в соответствии с параметрами команды и соответствующими настраиваемыми параметрами в ядре системы.
Давайте посмотрим, как команда xargs используется с командой find, и приведем несколько примеров.
Команда find используется в сочетании с exec и xargs, чтобы позволить пользователям выполнять почти все команды для соответствующих файлов.
2. Команда grep
grep (глобальный поиск по регулярному выражению (RE) и распечатка строки) — это мощный инструмент для поиска текста, который может искать текст с помощью регулярных выражений и распечатывать соответствующие строки ,
Использование sed в Linux
sed (от англ. Stream EDitor) — потоковый текстовый редактор (а также язычок программирования), использующий различные предопределённые текстовые преобразования к последовательному потоку текстовых этих. Sed можно утилизировать как grep, выводя строки по шаблону базового регулярного выражения:
Может быть использовать его для удаления строк (удаление всех пустых строк):
Основным инструментом работы с sed является выражение типа:
Так, образчик, если выполнить команду:
Выше рассмотрены различия меж «grep», «egrep» и «fgrep». Невзирая на различия в наборе используемых регулярных представлений и скорости выполнения, параметры командной строчки остаются одинаковыми для всех трех версий grep.
Примеры использования find
Поиск файла по имени
1. Простой поиск по имени:
find / -name «file.txt»
* в данном примере будет выполнен поиск файла с именем file.txt по всей файловой системе, начинающейся с корня .
2. Поиск файла по части имени:
find / -name «*.tmp»
* данной командой будет выполнен поиск всех папок или файлов в корневой директории /, заканчивающихся на .tmp
3. Несколько условий.
а) Логическое И. Например, файлы, которые начинаются на sess_ и заканчиваются на cd:
find . -name «sess_*» -a -name «*cd»
б) Логическое ИЛИ. Например, файлы, которые начинаются на sess_ или заканчиваются на cd:
find . -name «sess_*» -o -name «*cd»
в) Более компактный вид имеют регулярные выражения, например:
find . -regex ‘.*/\(sess_.*cd\)’
find . -regex ‘.*/\(sess_.*\|.*cd\)’
* где в первом поиске применяется выражение, аналогичное примеру а), а во втором — б).
4. Найти все файлы, кроме .log:
find . ! -name «*.log»
* в данном примере мы воспользовались логическим оператором !.
Поиск по дате
1. Поиск файлов, которые менялись определенное количество дней назад:
find . -type f -mtime +60
* данная команда найдет файлы, которые менялись более 60 дней назад.
2. Поиск файлов с помощью newer. Данная опция доступна с версии 4.3.3 (посмотреть можно командой find —version).
а) дате изменения:
find . -type f -newermt «2019-11-02 00:00»
* покажет все файлы, которые менялись, начиная с 02.11.2019 00:00.
find . -type f -newermt 2019-10-31 ! -newermt 2019-11-02
* найдет все файлы, которые менялись в промежутке между 31.10.2019 и 01.11.2019 (включительно).
б) дате обращения:
find . -type f -newerat 2019-10-08
* все файлы, к которым обращались с 08.10.2019.
find . -type f -newerat 2019-10-01 ! -newerat 2019-11-01
* все файлы, к которым обращались в октябре.
в) дате создания:
find . -type f -newerct 2019-09-07
* все файлы, созданные с 07 сентября 2019 года.
find . -type f -newerct 2019-09-07 ! -newerct «2019-09-09 07:50:00»
* файлы, созданные с 07.09.2019 00:00:00 по 09.09.2019 07:50
Искать в текущей директории и всех ее подпапках только файлы:
find . -type f
* f — искать только файлы.
Поиск по правам доступа
1. Ищем все справами на чтение и запись:
find / -perm 0666
2. Находим файлы, доступ к которым имеет только владелец:
find / -perm 0600
Поиск файла по содержимому
find / -type f -exec grep -i -H «content» {} \;
* в данном примере выполнен рекурсивный поиск всех файлов в директории и выведен список тех, в которых содержится строка content.
С сортировкой по дате модификации
find /data -type f -printf ‘%TY-%Tm-%Td %TT %p\n’ | sort -r
* команда найдет все файлы в каталоге /data, добавит к имени дату модификации и отсортирует данные по имени. В итоге получаем, что файлы будут идти в порядке их изменения.
Лимит на количество выводимых результатов
Самый распространенный пример — вывести один файл, который последний раз был модифицирован. Берем пример с сортировкой и добавляем следующее:
find /data -type f -printf ‘%TY-%Tm-%Td %TT %p\n’ | sort -r | head -n 1
Поиск с действием (exec)
1. Найти только файлы, которые начинаются на sess_ и удалить их:
find . -name «sess_*» -type f -print -exec rm {} \;
* -print использовать не обязательно, но он покажет все, что будет удаляться, поэтому данную опцию удобно использовать, когда команда выполняется вручную.
2. Переименовать найденные файлы:
find . -name «sess_*» -type f -exec mv {} new_name \;
или:
find . -name «sess_*» -type f | xargs -I ‘{}’ mv {} new_name
3. Вывести на экран количество найденных файлов и папок, которые заканчиваются на .tmp:
find . -name «*.tmp» | wc -l
4. Изменить права:
find /home/user/* -type d -exec chmod 2700 {} \;
* в данном примере мы ищем все каталоги (type d) в директории /home/user и ставим для них права 2700.
5. Передать найденные файлы конвееру (pipe):
find /etc -name ‘*.conf’ -follow -type f -exec cat {} \; | grep ‘test’
* в данном примере мы использовали find для поиска строки test в файлах, которые находятся в каталоге /etc, и название которых заканчивается на .conf. Для этого мы передали список найденных файлов команде grep, которая уже и выполнила поиск по содержимому данных файлов.
6. Произвести замену в файлах с помощью команды sed:
find /opt/project -type f -exec sed -i -e «s/test/production/g» {} \;
* находим все файлы в каталоге /opt/project и меняем их содержимое с test на production.
con GREP найдем любой текст в любом файле
Прежде всего мы объясним доступные варианты:
- –i: не будет различать верхний и нижний регистр.
- –w: заставить его находить только определенные слова.
- –v: выбирает строки, которые не совпадают.
- –n: показывает номер строки с запрошенными словами.
- –h: удаляет префикс из имени файла Unix в выводе.
- –r: рекурсивный поиск в каталогах.
- –R: как -r, но следуйте всем символическим ссылкам.
- –l: показывает только имена файлов с выделенными строками.
- –c- Показывает только одно количество выбранных строк для каждого файла.
- -Цвет: Отображает совпадающие шаблоны в цветах.
На изображении, которое вы указали в заголовке этой статьи, я искал слово «Изображения» в файле «830.desktop», который находится по этому пути. Как видите, я написал:
grep Imágenes /home/pablinux/Documentos/830.desktop
Имейте в виду, что в этой статье мы напишем примеры, которые необходимо изменить в соответствии с нашими поисковыми предпочтениями. Когда мы говорим «Файл», «Слово» и т. Д., Мы будем ссылаться на файл с его путем.. Если бы я просто написал «grep Images 830.desktop», я бы получил сообщение о том, что файл не существует. Или так было бы, если бы файл не находился в корневом каталоге.
Другие примеры:
- grep -i images /home/pablinux/Documentos/830.desktop, где «изображения» — это слово, которое мы хотим найти, а остальное — файл с его путем. В этом примере выполняется поиск «изображений» в файле «830.desktop» без учета регистра.
- grep -R изображения: он будет искать во всех строках каталога и всех его подкаталогах, где найдено слово «изображения».
- grep -c пример test.txt: это будет искать нас и показывать общее количество раз, когда «example» появляется в файле с именем «test.txt».
2.1, общие параметры и примеры команды grep
Команда grep используется для поиска шаблона, указанного параметром Pattern, и записи каждой соответствующей строки в стандартный вывод. Эти шаблоны являются ограниченными регулярными выражениями, они используют стиль команд ed или egrep. Если в параметре File указано несколько имен, команда grep отобразит имя файла, содержащего совпадающую строку.
Персонажи с особым значением для раковины Он должен быть заключен в двойные кавычки, когда он появляется в параметре Pattern. Если параметр Pattern не является простой строкой, обычно весь шаблон должен быть заключен в одинарные кавычки. В таких какВ таких выражениях, как,(Знак минус) Вы можете указать диапазон в соответствии с последовательностью, которая сортируется в данный момент. Последовательность упорядочения может определять эквивалентные классы для использования в диапазонах символов. Если файл не указан, grep примет стандартный ввод.
4.2.2. Grep and regular expressions
| If you are not on Linux | |
|---|---|
|
We use GNU grep in these examples, which supports extended regular expressions. GNU grep is the default on Linux systems. If you are working on proprietary systems, check with the -V option which version you are using. GNU grep can be downloaded from http://gnu.org/directory/. |
4.2.2.1. Line and word anchors
From the previous example, we now exclusively want to display lines starting with the string «root»:
cathy ~> grep ^root /etc/passwd root:x:0:0:root:/root:/bin/bash |
If we want to see which accounts have no shell assigned whatsoever, we search for lines ending in «:»:
cathy ~> grep :$ /etc/passwd news:x:9:13:news:/var/spool/news: |
To check that PATH is exported in ~/.bashrc, first select «export» lines and then search for lines starting with the string «PATH», so as not to display MANPATH and other possible paths:
cathy ~> grep export ~/.bashrc | grep '\<PATH' export PATH="/bin:/usr/lib/mh:/lib:/usr/bin:/usr/local/bin:/usr/ucb:/usr/dbin:$PATH" |
Similarly, \> matches the end of a word.
If you want to find a string that is a separate word (enclosed by spaces), it is better use the -w, as in this example where we are displaying information for the root partition:
cathy ~> grep -w /etc/fstab LABEL=/ / ext3 defaults 1 1 |
If this option is not used, all the lines from the file system table will be displayed.
4.2.2.2. Character classes
A bracket expression is a list of characters enclosed by «». It matches any single character in that list; if the first character of the list is the caret, «^», then it matches any character NOT in the list. For example, the regular expression «» matches any single digit.
Within a bracket expression, a range expression consists of two characters separated by a hyphen. It matches any single character that sorts between the two characters, inclusive, using the locale’s collating sequence and character set. For example, in the default C locale, «» is equivalent to «». Many locales sort characters in dictionary order, and in these locales «» is typically not equivalent to «»; it might be equivalent to «», for example. To obtain the traditional interpretation of bracket expressions, you can use the C locale by setting the LC_ALL environment variable to the value «C».
Finally, certain named classes of characters are predefined within bracket expressions. See the grep man or info pages for more information about these predefined expressions.
cathy ~> grep /etc/group sys:x:3:root,bin,adm tty:x:5: mail:x:12:mail,postfix ftp:x:50: nobody:x:99: floppy:x:19: xfs:x:43: nfsnobody:x:65534: postfix:x:89: |
In the example, all the lines containing either a «y» or «f» character are displayed.
4.2.2.3. Wildcards
Use the «.» for a single character match. If you want to get a list of all five-character English dictionary words starting with «c» and ending in «h» (handy for solving crosswords):
cathy ~> grep '\<c...h\>' /usr/share/dict/words catch clash cloth coach couch cough crash crush |
If you want to display lines containing the literal dot character, use the -F option to grep.
For matching multiple characters, use the asterisk. This example selects all words starting with «c» and ending in «h» from the system’s dictionary:
cathy ~> grep '\<c.*h\>' /usr/share/dict/words caliph cash catch cheesecloth cheetah --output omitted-- |
If you want to find the literal asterisk character in a file or output, use single quotes. Cathy in the example below first tries finding the asterisk character in /etc/profile without using quotes, which does not return any lines. Using quotes, output is generated:
cathy ~> grep * /etc/profile cathy ~> grep '*' /etc/profile for i in /etc/profile.d/*.sh ; do |
Примеры использования
С теорией покончено, теперь перейдём к практике. Рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep, которые могут вам понадобиться в повседневной жизни.
Поиск текста в файлах
В первом примере мы будем искать пользователя User в файле паролей Linux. Чтобы выполнить поиск текста grep в файле /etc/passwd введите следующую команду:
В результате вы получите что-то вроде этого, если, конечно, существует такой пользователь:
А теперь не будем учитывать регистр во время поиска. Тогда комбинации ABC, abc и Abc с точки зрения программы будут одинаковы:
Вывести несколько строк
Например, мы хотим выбрать все ошибки из лог-файла, но знаем, что в следующей строчке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк. Ошибки будем искать в Xorg.log по шаблону «EE»:
Выведет строку с вхождением и 4 строчки после неё:
Выведет целевую строку и 4 строчки до неё:
Выведет по две строки с верху и снизу от вхождения.
Регулярные выражения в grep
Регулярные выражения grep — очень мощный инструмент в разы расширяющий возможности поиска текста в файлах. Для активации этого режима используйте опцию -e. Рассмотрим несколько примеров:
Поиск вхождения в начале строки с помощью спецсимвола «^», например, выведем все сообщения за ноябрь:
Поиск в конце строки — спецсимвол «$»:
Найдём все строки, которые содержат цифры:
Вообще, регулярные выражения grep — это очень обширная тема, в этой статье я лишь показал несколько примеров. Как вы увидели, поиск текста в файлах grep становиться ещё эффективнее. Но на полное объяснение этой темы нужна целая статья, поэтому пока пропустим её и пойдем дальше.
Рекурсивное использование grep
Если вам нужно провести поиск текста в нескольких файлах, размещённых в одном каталоге или подкаталогах, например в файлах конфигурации Apache — /etc/apache2/, используйте рекурсивный поиск. Для включения рекурсивного поиска в grep есть опция -r. Следующая команда займётся поиском текста в файлах Linux во всех подкаталогах /etc/apache2 на предмет вхождения строки mydomain.com:
В выводе вы получите:
Здесь перед найденной строкой указано имя файла, в котором она была найдена. Вывод имени файла легко отключить с помощью опции -h:
Поиск слов в grep
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить утилиту искать по содержимому файлов в Linux только те строки, которые выключают искомые слова с помощью опции -w:
Количество вхождений строки
Утилита grep может сообщить, сколько раз определённая строка была найдена в каждом файле. Для этого используется опция -c (счетчик):
C помощью опции -n можно выводить номер строки, в которой найдено вхождение, например:
Получим:
Инвертированный поиск в grep
Команда grep Linux может быть использована для поиска строк в файле, которые не содержат указанное слово. Например, вывести только те строки, которые не содержат слово пар:
Вывод имени файла
Вы можете указать grep выводить только имя файла, в котором было найдено заданное слово с помощью опции -l. Например, следующая команда выведет все имена файлов, при поиске по содержимому которых было обнаружено вхождение primary:
Регулярные выражения Linux
В регулярных выражениях могут использоваться два типа символов:
- обычные буквы;
- метасимволы.
Обычные символы — это буквы, цифры и знаки препинания, из которых состоят любые строки. Все тексты состоят из букв и вы можете использовать их в регулярных выражениях для поиска нужной позиции в тексте.
Метасимволы — это кое-что другое, именно они дают силу регулярным выражениям. С помощью метасимволов вы можете сделать намного больше чем поиск одного символа. Вы можете искать комбинации символов, использовать динамическое их количество и выбирать диапазоны. Все спецсимволы можно разделить на два типа, это символы замены, которые заменяют собой обычные символы, или операторы, которые указывают сколько раз может повторяться символ. Синтаксис регулярного выражения будет выглядеть таким образом:
обычный_символ спецсимвол_оператор
спецсимвол_замены спецсимвол_оператор
Если оператор не указать, то будет считаться, что символ обязательно должен встретится в строке один раз. Таких конструкций может быть много. Вот основные метасимволы, которые используют регулярные выражения bash:
- \ — с обратной косой черты начинаются буквенные спецсимволы, а также он используется если нужно использовать спецсимвол в виде какого-либо знака препинания;
- ^ — указывает на начало строки;
- $ — указывает на конец строки;
- * — указывает, что предыдущий символ может повторяться 0 или больше раз;
- + — указывает, что предыдущий символ должен повторится больше один или больше раз;
- ? — предыдущий символ может встречаться ноль или один раз;
- {n} — указывает сколько раз (n) нужно повторить предыдущий символ;
- {N,n} — предыдущий символ может повторяться от N до n раз;
- . — любой символ кроме перевода строки;
- — любой символ, указанный в скобках;
- х|у — символ x или символ y;
- — любой символ, кроме тех, что указаны в скобках;
- — любой символ из указанного диапазона;
- — любой символ, которого нет в диапазоне;
- \b — обозначает границу слова с пробелом;
- \B — обозначает что символ должен быть внутри слова, например, ux совпадет с uxb или tuxedo, но не совпадет с Linux;
- \d — означает, что символ — цифра;
- \D — нецифровой символ;
- \n — символ перевода строки;
- \s — один из символов пробела, пробел, табуляция и так далее;
- \S — любой символ кроме пробела;
- \t — символ табуляции;
- \v — символ вертикальной табуляции;
- \w — любой буквенный символ, включая подчеркивание;
- \W — любой буквенный символ, кроме подчеркивания;
- \uXXX — символ Unicdoe.
Важно отметить, что перед буквенными спецсимволами нужно использовать косую черту, чтобы указать, что дальше идет спецсимвол. Правильно и обратное, если вы хотите использовать спецсимвол, который применяется без косой черты в качестве обычного символа, то вам придется добавить косую черту
Например, вы хотите найти в тексте строку 1+ 2=3. Если вы используете эту строку в качестве регулярного выражения, то ничего не найдете, потому что система интерпретирует плюс как спецсимвол, который сообщает, что предыдущая единица должна повториться один или больше раз. Поэтому его нужно экранировать: 1 \+ 2 = 3. Без экранирования наше регулярное выражение соответствовало бы только строке 11=3 или 111=3 и так далее. Перед равно черту ставить не нужно, потому что это не спецсимвол.
Character classes and bracket expressions
A bracket expression is a list of characters enclosed by and . It matches any single character in that list; if the first character of the list is the caret ^ then it matches any character not in the list. For example, the regular expression matches any single digit.
Within a bracket expression, a range expression consists of two characters separated by a hyphen. It matches any single character that sorts between the two characters, inclusive, using the locale’s collating sequence and character set. For example, in the default C locale, is equivalent to . Many locales sort characters in dictionary order, and in these locales is often not equivalent to ; it might be equivalent to , for example. To obtain the traditional interpretation of bracket expressions, you can use the C locale by setting the LC_ALL environment variable to the value C.
Finally, certain named classes of characters are predefined within bracket expressions, as follows. Their names are self explanatory, and they are , , , , , , , , , , and . For example, ] means the character class of numbers and letters in the current locale. In the C locale and ASCII character set encoding, this is the same as . (Note that the brackets in these class names are part of the symbolic names, and must be included in addition to the brackets delimiting the bracket expression.) Most metacharacters lose their special meaning inside bracket expressions. To include a literal place it first in the list. Similarly, to include a literal ^ place it anywhere but first. Finally, to include a literal —, place it last.
Квантификаторы
Квантификаторы позволяют указать количество вхождений элементов, которые должны присутствовать, чтобы совпадение произошло. В следующей таблице показаны квантификаторы, поддерживаемые GNU :
| Квантификатор | Описание |
|---|---|
| Сопоставьте предыдущий элемент ноль или более раз. | |
| Соответствует предыдущему элементу ноль или один раз. | |
| Сопоставьте предыдущий элемент один или несколько раз. | |
| Сравните предыдущий элемент ровно раз. | |
| Сопоставьте предыдущий элемент не менее раз. | |
| Соответствовать предыдущему элементу не более раз. | |
| Сопоставьте предыдущий элемент от до раз. |
Символ (звездочка) соответствует предыдущему элементу ноль или более раз. Следующее будет соответствовать «right», «sright», «ssright» и так далее:
Ниже представлен более сложный шаблон, который соответствует всем строкам, которые начинаются с заглавной буквы и заканчиваются точкой или запятой. Регулярное выражение Соответствует любому количеству любых символов:
(знак вопроса) символ делает предыдущий элемент необязательным и может соответствовать только один раз. Следующие будут соответствовать как «ярким», так и «правильным». Символ экранирован обратной косой чертой, потому что мы используем базовые регулярные выражения:
Вот то же регулярное выражение с использованием расширенного регулярного выражения:
Символ (плюс) соответствует предыдущему элементу один или несколько раз. Следующее будет соответствовать «sright» и «ssright», но не «right»:
Фигурные скобки позволяют указать точное число, верхнюю или нижнюю границу или диапазон вхождений, которые должны произойти, чтобы совпадение произошло.
Следующее соответствует всем целым числам, содержащим от 3 до 9 цифр:
Почему мы используем grep?
Grep — это инструмент командной строки, который пользователи Linux используют для поиска текстовых строк. Вы можете использовать его для поиска файла по определенному слову или комбинации слов, или вы можете направить вывод других команд Linux в grep, так что grep может показать вам только тот вывод, который вам нужен.
Давайте посмотрим на некоторые действительно распространенные примеры. Скажем, вам нужно проверить содержимое каталога, чтобы увидеть, существует ли там определенный файл. Это то, для чего вы бы использовали команду «ls».
Но чтобы ускорить весь процесс проверки содержимого каталога, вы можете направить вывод команды ls в команду grep. Давайте посмотрим в нашем домашнем каталоге папку с названием Documents.
$ ls Desktop Drafts Ваше_имя 'My files' Samples Documents examples.desktop Linux Pictures Templates Downloads Favorites Music Public Videos
А теперь давайте попробуем проверить каталог снова, но на этот раз, используя grep, специально для проверки папки «Документы».
$ ls | grep Documents Documents
Как вы можете видеть на скриншоте выше, использование команды grep сэкономило нам время, быстро изолировав искомое слово от остальной части ненужного вывода, созданного командой ls.
Если папка Documents не существует, grep не вернет ничего. Поэтому, если ничего не возвращает grep, это означает, что он не может найти слово, которое вы ищете.


