Распознавание текста на фото в ios 15: как работает
Содержание:
- Также: OCR с Google Docs
- Копировать текст из распечатки файла
- Инструмент OCR онлайн
- Как из Интернета скопировать картинку
- Img2txt.com – русскоязычный сервис для распознавания текста
- Почему вебмастера не дают скопировать текст?
- Настройки и работа с FineScanner
- Как скопировать с сайта текст используя Word?
- Копирование текста с картинки в Интернет браузере
- Выключаем JavaScript
- Особенности процесса
Также: OCR с Google Docs
Если вы находитесь за пределами своего компьютера, попробуйте использовать функции оптического распознавания текста на Google Диске. Google Docs имеет встроенную программу OCR, которая может распознавать текст в Файлы JPEG, PNG, GIF и PDF. Но все файлы должны быть 2 МБ или меньше, а текст должен быть 10 пикселей или выше. Google Диск также может автоматически определять язык в отсканированных файлах, хотя точность с нелатинскими символами может быть невелика.
- Войдите в свою учетную запись Google Drive.
- Нажмите на Новый> Загрузка файла, Кроме того, вы также можете нажать на Мой диск> Загрузить файлы,
- Найдите файл на вашем ПК, который вы хотите конвертировать из PDF или изображения в текст. Нажмите на открыто Кнопка для загрузки файла.
- Документ теперь находится на вашем Google Диске. Щелкните правой кнопкой мыши на документе и нажмите Открыть с помощью> Документов Google,
- Google преобразует ваш PDF или файл изображения в текст с помощью OCR и открывает его в новом документе Google. Текст редактируемый, и вы можете исправить части, в которых OCR не смог правильно его прочитать.
- Вы можете скачать настроенные документы в нескольких форматах, которые поддерживает Google Drive. Выбери из Файл> Скачать как меню.
Копировать текст из распечатки файла
Вы можете вставлять файлы, например PDF-файлы, электронные таблицы или документы Word, в записную книжку OneNote. Эти распечатки вставлены в виде изображений, поэтому их нельзя редактировать. Однако вы можете скопировать текст с одной страницы (или всех страниц) распечатанного файла, а затем вставить его как обычный текст.
Чтобы вставить распечатку файла в OneNote, щелкните вкладку «Вставить», а затем щелкните «Распечатка файла» в раскрывающемся меню.

Найдите и выберите файл, который вы хотите вставить, на локальном компьютере. После вставки щелкните распечатку файла правой кнопкой мыши. Вы можете скопировать текст с одной или всех страниц распечатки файла, щелкнув «Копировать текст с этой страницы распечатки» или «Копировать текст со всех страниц распечатки» соответственно.
К сожалению, вы не можете скопировать текст с определенного количества страниц, поэтому, если вы хотите скопировать текст, например, только с 3 из 5 страниц, вам придется копировать эти 3 страницы по одной.

Затем щелкните то место, куда вы хотите вставить текст, а затем нажмите Ctrl + V (Command + V на Mac) или просто щелкните правой кнопкой мыши и затем выберите параметр вставки «Только текст» в контекстном меню.

Скопированный текст появится в вашей записной книжке OneNote.
Несмотря на то, что функция копирования / вставки является одной из основных, OneNote отличается тем, что вы можете копировать текст из изображений и распечаток файлов — функции, которой нет во многих других настольных приложениях (хотя вы можете сделать это на своем телефоне). И что еще лучше, если вы готовы преобразовать эту записную книжку OneNote обратно в PDF-файл, для этого есть вариант.
Инструмент OCR онлайн

Другим способом копировать и редактировать надписи на фото и графических картинках можно с использованием онлайн-инструментов. Одним из таких инструментов является: http://newocr.com.
Использовать инструмент очень легко, просто выберите файл изображения, выберите язык документа и загрузите изображение. После загрузки изображения, нажмите кнопку «OCR», и программа начинает конвертировать загруженное изображение.
Преобразованный текс, данным сервисом не слишком совершенен. Программа иногда теряет некоторые символы и нечеткие изображения букв. К счастью, она указывает на эти ошибки, и вы можете быстро все исправить.
После проверки орфографии, остается только скопировать и сохранить полученный документ. Этот инструмент дает возможность, помимо всего прочего переводить машинопись с помощью Google Translator. Когда статья готова, можно сохранить ее как PDF, TXT или DOC.
Честно сказать, данный сервис мне не очень понравился из-за наличия мешающейся рекламы + еще при конвертации страница перезагружается и вообще дизайн какой-то шаблонный и некрасивый. Но на все найдутся свои покупатели…)))
Копирование и вставка текста на современных мобильных гаджетах

В системе Windows, Андроид и IOS на современных смартфонах iPhone или Android, вы можете скопировать в основном произвольные фрагменты надписи и вставить их почти во все места, где можно вводить текст, экономя для себя, благодаря этой функции, много времени.
Скопировать адрес электронной почты и вставить его в качестве пункта назначения на карте. Скопировать рецепт с веб-сайта, вставить его в текстовое сообщение и отправить другу. Скопировать пункт из документа, Word Mobile Office и вставить его в сообщение электронной почты боссу.)))
Есть два способа копирования текста: выбор его или навигация по меню. После копирования в телефон, можно вставлять текст в любые другие места, любое количество раз.
Можно скопировать и вставить также отсканированную информацию с помощью функции Bing Vision в телефоне.
Как из Интернета скопировать картинку
Чтобы скопировать катринку из Интернета, нужно щелкнуть по ней правой кнопкой мышки и в открывшемся контекстном меню выбрать пункт «Сохранить изображение как…» (или с другим похожим по смыслу названием).
Откроется окно, в котором нужно будет указать место для сохранения изображения, название файла, в который оно будет сохранено, после чего нажать кнопку «Сохранить».
Бывает, что по каким-то причинам сохранить изображение указанным выше способом не удается. В этом случае из ситуации можно выйти путем создания скриншота части экрана монитора, в которой отображается интересующая картинка. Подробнее о том, что такое скриншот и как его создать, читайте в этой нашей статье.
Img2txt.com – русскоязычный сервис для распознавания текста
И последний сервис, о котором я хочу рассказать – это img2txt.com . Сервис был запущен в 2014 году, прошёл несколько стадий улучшения своего функционала, и ныне обладает довольно неплохим качеством распознавания. Здесь имеется русскоязычный интерфейс, что придётся по вкусу отечественному пользователю.
- Перейдите на img2txt.com;
- Кликните на «Выберите файл с изображением» и загрузите изображение с текстом на ресурс;
- Выберите язык текста для распознавания;
- Поставьте галочку рядом с надписью «Я не робот» (капча), и нажмите на «Загрузить»;
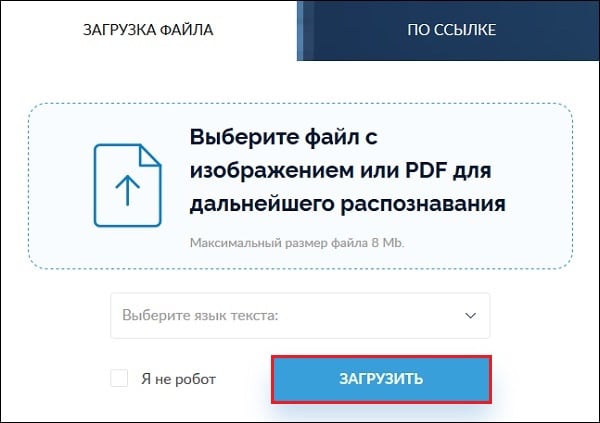
Загрузите файл на ресурс
Подождите некоторое время, пока изображение пройдёт распознание;
Просмотрите полученный результат.
Примечание: Мы стараемся как можно оперативнее обеспечивать вас актуальными справочными материалами на вашем языке. Эта страница переведена автоматически, поэтому ее текст может содержать неточности и грамматические ошибки
Для нас важно, чтобы эта статья была вам полезна. Просим вас уделить пару секунд и сообщить, помогла ли она вам, с помощью кнопок внизу страницы
Для удобства также приводим ссылку на оригинал (на английском языке) .
OneNote поддерживает функцию распознавания текста (OCR), инструмент, позволяющий копировать текст из рисунка или распечатки файла и вставьте его в заметки, можно внести изменения в эти слова. Это отличный способ выполнения действий, такие как Копировать сведения из визитной карточки отсканированное в записную книжку OneNote. После извлечения текста, чтобы вставить его в другом месте в OneNote или в другой программе, такие как Outlook или Word.
Почему вебмастера не дают скопировать текст?
Разумеется, читателям подобное поведение блогера очень не нравится. Но, хозяева сайтов закрывают от копирования свои тексты не от своих читателей, а от своих коллег, других вебмастеров. И происходит это за тем, чтобы текс остался уникальным. Иначе, недобросовестные вебмастера начинают копировать ваши статьи, вставляют на свои сайты, и при этом даже забывают добавить ссылку на ваш сайт.
Для продвижения сайта – это плохо. Вот и были созданы различные плагины и скрипты, которые не дают людям скопировать текст. Несколько лет назад я решил проверить свои статьи на уникальность, и обнаружил, что большинство моих статей были не уникальны. Я решил проверить, где же находятся копии моих статей через специальную программу.
Каково же было моё удивление, когда почти все данные статьи стояли всего на одном сайте. Причем всё как у меня, начиная с картинок и заканчивая текстом. Причем ссылок на первоисточник не было. А это обязательно! Я разрешаю копировать мои статьи. Но, с ОБЯЗАТЕЛЬНОЙ ссылкой на мой сайт. Затем я поговорил с хозяйкой сайта, на котором нашел свои статьи и мы решили этот вопрос мирным путём (она поставила на мой сайт ссылки).
Настройки и работа с FineScanner
После первого запуска хотелось бы остановится на некоторых настройках программы. В частности на экране согласия с соглашением.
На этом экране смело оставляем второй пункт без галочки, чтобы не получать рекламные сообщения. Первые два при этом нужно оставить включенными, иначе продолжить будет нельзя.
После того как прошли первые этапы знакомства с программой, сразу появится окно сканирования, где у вас попросят разрешения на работу с камерой. Разрешаем. Окно для работы выглядит следующим образом:
1 — Самая главная кнопка, с помощью которой мы будем фотографировать наши документы.
2 — Автозахват. С его помощью программа сама проанализирует происходящее и найдет документ. Потом сама его и cфотографирует. Ведет Автозахват себя не всегда предсказуемо, поэтому включать я его не всегда рекомендую. Но если вы не знаете, каким образом правильно сфотографировать документ, то можно эту настройку включить.
3 — Фонарик. Если освещение плохое, то с помощью этой кнопки можно включить фонарик на телефоне.
4 — Здесь будут показываться сфотографированные документы.
5 — Удаление последнего документа.
Переделать фотографию в вордовский документ в FineScanner можно следующим образом. Наводим нашу камеру на документ. В идеальной ситуации, в месте, где вы фотографируете, должно быть светло. Чем хуже освещение, тем хуже распознавание. Стараемся навести камеру на документ под прямым углом. Фотографировать под углом не рекомендуется. Можете включить инструмент Автозахвата, если не уверены в себе.
После того, как навели камеру на документ, фотографируем его по центральной кнопке внизу (1). Аналогичным образом фотографируем другие страницы документов. Справа внизу будет показано количество сфотографированных страниц (4). Если вы случайно сделали ошибку и сфотографировали не тот документ, то удалить его можно по значку корзины (5). Закончив фотографирование переходим на окно редактирования документа, нажав на значок справа внизу (4).
На этом экране можно обрезать, повернуть изображение или наложить фильтры. Сразу будет применен черно-белый фильтр. Такой фильтр сделает распознавание фото в документ более быстрым и точным. На качество распознавания также влияет сама страница. Если на странице много заметок или таблиц, то распознавание будет не таким точным. Лучше всего распознаются страницы в одну колонку без таблиц. Свайпами влево/вправо можно настроить каждую страницу по отдельности. Закончив с документом, нажимаем вверху сохранить.
После этого можно приступать к созданию вордовского документа по фото.
Как скопировать с сайта текст используя Word?
Довольно простой и удобны метод. Но, для его использования понадобится часть времени на обработку компьютером запроса. В итоге же, на странице Ворд появится полная копия данного контента с сайта (со всеми фото).
Итак, в документе Ворд кликнем по меню «Файл». У нас открывается колонка, где нас интересует вкладка «Открыть». Кликнем по ней и в правом окне кликнем по изображению папочки. Далее, всплывает новое окошко, где нас интересует строка «Имя файла». В неё мы вписываем адрес страницы, которую мы не могли скопировать, нажимаем «Открыть».
Какое-то время компьютер обрабатывает наш запрос (данное время обработки зависит от мощности вашего компьютера и веса страницы, которую мы решили скопировать. Через пару минут, у меня в документе Word появляется полная копия страницы моего сайта, на который я поставил защиту от копирования.
Word с этой функцией справился лучше, чем предыдущее методы. Появился новый документ, адресом которого служит адрес моей страницы с сайта. Вам остаётся только почистить страницу от лишних элементов (например, баннеров, их Ворд также скопировал), и текст готов. Можете использовать данный текст по назначению.
Копирование текста с картинки в Интернет браузере
Первый инструмент, о котором расскажем, будет плагин для браузера Google Chrome: Project Naptha. Это бесплатный и очень удобный плагин, который позволяет легко (без запуска других программ) в любое время скопировать информацию из графического изображения. Распознать текст с картинок и фотографий, сделанных в фотошопе.
После инсталляции (Меню… Дополнительные расширения… Расширения… Еще расширения… в поиске Project Naptha… Enter… Установка…), плагин будет все время активен и в документы на растровых образах.
Плагин распознает практически любой шрифт. К сожалению, есть один недостаток, не может справиться с некоторыми знаками. При копировании информации с некоторыми знаками, например «апостраф», может выскочить сообщение об ошибке.
Выключаем JavaScript
Данный ДжаваСкрипт можно отключить специальным дополнением для обозревателя «NOScript». Его достаточно скачать с базы дополнений и установить. Но, лучше попробовать выключить этот скрипт ручным методом. Лишние расширения тормозят браузер.
- Эту настройку я покажу в Chrome, так как им пользуется большая часть людей в мире. Текст на моём сайте остаётся заблокированным. Итак, необходимо зайти в настройки Хрома. Для этого, кликнем по 3 вертикальным точкам и в ниспадающем меню выберем «Настройки»;
- В новом окошке страницу перекручиваем в самый низ и нажимаем на треугольник команды «Дополнительные»;
- В показавшемся продолжении страницы находим команду «Настройки сайта» и нажимаем на неё;
- Теперь ищем вкладку JavaScript, нажимаем на неё;
- В новом окне над командой «Разрешено» передвигаем выключатель влево. Теперь у нас на этом месте появилась надпись «Заблокировано»;
- Вам осталось обновить нужную страницу, и вы можете скопировать текст без ограничений. После этого, нужно вернуть всё на место, иначе часть ресурсов будут показываться некорректно.
Данный метод работает не на всех сайтах. На моём он не сработал (а первый вариант сработал). Видно, я прославил довольно сильный плагин для блокировки. Но, зато, зайдя на другие сайта, он показал себя как отличный способ для разблокирования первого варианта.
Хочу добавить, если у вас появилась желание на части ресурсов отключить JavaScript навсегда, тогда проделаем следующее:
- Заходим в это же окно и после выключателя нажмём на синюю ссылку «Блокировать»;
- На этой кнопочке появляется надпись «Добавить», нажимаем на неё, и в открывшемся окошке вводим адрес сайта, на котором мы желаем заблокировать JavaScript.
- Теперь на сайте, с которого вы убрали действие ДжаваСкрипта, вы всё время сможете копировать столько текста, сколько нужно. Но, вполне возможно, что часть функций не будут на данном ресурсе работать, пока вы его адрес не удалите из этого списка.
Особенности процесса
В функционале программного обеспечения присутствует много функций, позволяющих работать с большинством шрифтов. Среди передовых возможностей присутствует способность распознать рукописный текст Word из jpg. Она имеет много преимуществ:
выбор качества. Пользователь может сам остановить предпочтительное качество для сканирования. Лучше выбирать не ниже 300 DPI, чтобы программа затрагивала для обработки даже мелкие детали, и смогла работать с мелкими шрифтами.
цветность. Необходимо, когда на изображении присутствуют таблицы или другая символика. В других же вариантах предпочтительно выбирать чёрно-белый режим, который уберёт смещения цветового диапазона с букв, сделав их чище
Цветной режим подойдёт для ярких картинок, где важно передать цвет текста.
фотография. Если картинка выполнена снимком, программа повысит приоритет сканирования
Также можно непосредственно с ABBYY FineReader сфотографировать текст, чтобы распознать его в jpg. Правда, это сильно ухудшит качество, отчего финальный результат будет иметь много ошибок.
Среди аналогичных программ присутствуют также бесплатные сервисы. Среди них выделяется также Google Drive, которая доступная непосредственно в браузере. Работа с OCR Convert имеет среднее качество, поэтому подходит для тех, у кого изображение имеет высокое расширение и чёткие шрифты. Сервис i2OCR предлагает аналогичные услуги, только картинки можно ещё загрузить с URL-ссылки. Они имеют больше любительский формат, поэтому не рассматриваются для профессионального использования.
Открыв картинку через Google Документы, вы получите документ с уже распознанным текстом
Получить результат
После начала сканирования обычно проходит пару минут, чтобы получить результат. Этот показатель зависит от сложности и количества располагаемого текста. После старта работы, программы в автоматическом режиме будут выделять участки для проверки, и преобразовать их. После окончания процесса, можно повторно распознать jpg данные, или сосредоточиться на определённых участках документа.
Готовый результат экспортируется в файл Word. Полученный текст можно редактировать при наблюдении ошибок, или продолжить с ним дальнейшую работу. Распознать текст с jpg картинок не представляет труда, если правильно подготовить изображение. Этот процесс может существенно сэкономить время, в отличие от ручного перепечатывания информации.
Поскольку работа с распознаванием текста с картинки требует качественного исходника, нужно изначально найти изображение с высоким разрешением. Это ускорит сам процесс обработки данных, а также уменьшит общий объем ошибок.



