Поисковые подсказки
Содержание:
- О статистике запросов Яндекса и Вордстате
- Пошаговая инструкция по работе с Yandex Wordstat
- Алгоритм работы парсера
- Обзор парсера Google Suggest#
- Виды подсказок
- getParserPreset#
- Как пользоваться парсером подсказок от Click.ru: пошаговая инструкция
- Парсеры поисковых систем#
- Какая связь между блоком быстрых ответов Google и long tail запросами
- Категории подсказок Яндекса
- Реклама в подсказках поиска Яндекс: как составить список правильных подсказок
- Последние материалы
- Как собрать подсказки Youtube: способы
- Парсинг html-сайтов с помощью PHP, Ruby, Python
- Немного истории и теории
- Принципы форматирования#
- P. S. Помните о сезонности
- Как удалить подсказки
- Формат имени файла результатов#
- Парсинг: что это такое простыми словами
- Возможности и преимушества#
- Заключение
О статистике запросов Яндекса и Вордстате
«Подбор слов» (wordstat.yandex.ru) – бесплатный сервис статистики поисковых запросов в Яндексе. Он показывает, как часто пользователи ищут в поиске то или иное слово или фразу.
С этим инструментом знакомится каждый, кто только начинает изучать продвижение в интернете: поисковую оптимизацию (SEO), контекстную рекламу (в Директе), контент-маркетинг.
Сама статистика поисковых запросов (ключевых слов, фраз или просто ключей) нужна предпринимателям, маркетологам и другим диджитал-специалистам для:
Поискового продвижения действующего сайта: сервис помогает прогнозировать трафик из поиска Яндекса, оптимизировать имеющиеся страницы, разрабатывать новые разделы.
Настройки и ведения контекстной рекламы:Вордстат позволяет понять, по каким словам и фразам размещать рекламу в Директе, а какие запросы нет смысла использовать.
Запуска нового сайта: данные Яндекса стоит учитывать при планировании структуры будущего ресурса, а также закладке бюджета на контент, дизайн, рекламу.
Анализа рынка перед запуском нового проекта: статистика поисковых запросов отражает интересы и потребности пользователей, спрос на товары и услуги с учетом географии и сезонности.
Статистика поисковых запросов Яндекса в Вордстате
Пошаговая инструкция по работе с Yandex Wordstat
Для грамотного использования Яндекс Вордстат необходимо:
- Зарегистрироваться и войти в свою почту (аккаунт) на Яндексе;
- Записать в поле запрос и кликнуть «Подобрать».
Если вы не залогинились в своем аккаунте, то Yandex Wordstat при заходе в него предложит вам сделать это.
Давайте пробежимся по функционалу интерфейса.
Под основной строкой для ввода ключевого слова есть три флажка:
- «По словам»;
- «По регионам»;
- «История запросов».
Подробнее работу с каждым из них мы рассмотрим далее.
Справа ссылка «Все регионы» — позволит выбрать и посмотреть статистику ключевика по заданному региону.
Сбор запросов по словам
Как видно из вышеприведенного скриншота в Яндекс Вордстат этот вариант стоит «по умолчанию». Он показывает статистику запросов по региону, если тот выбран, если нет, то статистика показывается по всем регионам.
Давайте введем в основное поле фразу «Стройматериалы» и посмотрим, что покажет нам Wordstat. Возможно, вам придется ввести капчу. У меня обошлось без этого.
Система выдаст две колонки, которые будут содержать различные вариации заданного ключевого слова.
В левом столбце Яндекс Вордстат будут все прямые и непрямые вхождения. Правый — отобразит похожие запросы — «стройматериалы», «строительные материалы», «строительный рынок» и т.д. Т.е. отсюда можно выбрать достаточно интересные ключи для продвижения и этим не стоит пренебрегать.
Цифры, расположенные справа от запросов — это количество показов в месяц. Но это всего лишь прогнозируемый Яндексом результат, который вычисляется из статистики поисковика. Т.е. реальный результат может быть больше или меньше прогнозируемого. Но в принципе, плюс/минус Яша всегда показывает «правду».
Еще можно посмотреть статистику отдельно для десктопов, мобильников и т.п., просто переключив флажок в соответствующее поле, под основным полем ввода исследуемой фразы.
Сбор ключевых слов по регионам
При просмотре ключей по регионам на выбор предлагается 3 вкладки:
- Регионы;
- Города;
- Все вместе.
Справа, напротив каждого запроса мы видим соотношение популярности ключа к тому или иному региону. Если кликнуть на соответствующую ссылку, то можно отсортировать запросы по региональной популярности.
Можно посмотреть частотности ключевых слов, показываемые на том или ином устройстве: смартфоне, планшете, ПК и т.д.
Кликнув по вкладке «Карта» откроется интерактивная карта. Наведя мышку на интересующую область, отобразится статистика по этому региону. Желтые области на карте относятся к наиболее популярным, красные к менее популярным.
Как посмотреть историю запросов
Установив флажок в поле «История запросов» можно посмотреть частоту показа этого запроса в определенный период времени (неделя, месяц, год). Таким образом определяются сезонные фразы.
Что это значит? Сезонные запросы – это те запросы, которые пользователи вбивают только в определенное время. Например, фраза «купить велосипед» будет вводиться в поиске Яндекса гораздо чаще весной и летом, чем осенью и зимой. Думаю, что вы со мной согласитесь.
График показывает наглядное изменение количества вводимых фраз за период с 2018 года по 2019. Здесь же можно сделать группировку по неделям и месяцам и выбрать требуемое устройство, как и на предыдущей вкладке.
На графике показаны две кривые – с абсолютным и относительным значениями. Абсолютное показывает значение в данный момент, а относительное – отношение реального количества к общему числу показов за неделю или за месяц. Это общая популярность фразы.
Специальные операторы
Например, вам надо, чтобы сервис показал только определенные фразы в точной словоформе, падеже, числе и тому подобное. Для этого надо обрамить фразу в кавычки и поставить перед каждым словом восклицательный знак. Например, «!жилье !за !границей».
| Оператор | Значение |
| — | Если фраза содержит знак минус, то это слово удаляется. |
|
+ |
Если фраза содержит знак плюс, то показываются только те запросы, которые содержат это слово. |
|
«» |
Фраза в кавычках показывает все слова из данного запросов в любом порядке и словоформе. |
| «!» | Точное вхождение. |
Например, если мы ищем «жилье за -границей», то нам будут показаны только фразы с «жилье за». Слово «граница» не будет учитываться.
Алгоритм работы парсера
Парсер работает следующим образом: он анализирует страницу на наличие контента, соответствующего заранее заданным параметрам, а потом извлекает его, превратив в систематизированные данные.
Процесс работы с утилитой для поиска и извлечения найденной информации выглядит так:
- Сначала пользователь указывает вводные данные для парсинга на сайте.
- Затем указывает список страниц или ресурсов, на которых нужно осуществить поиск.
- После этого программа в автоматическом режиме проводит глубокий анализ найденного контента и систематизирует его.
- В итоге пользователь получает отчет в заранее выбранном формате.
Естественно, процедура парсинга через специализированное ПО описана лишь в общих чертах. Для каждой утилиты она будет выглядеть по-разному. Также на процесс работы с парсером влияют цели, преследуемые пользователем.
Обзор парсера Google Suggest#
Парсер поисковых подсказок по ключевым словам в Гугле. Благодаря парсеру SE::Google::Suggest вы сможете автоматически собирать базы ключей из подсказок поисковой системы Google по запросу. Используя парсер SE::Google::Suggest можно легко и быстро спарсить подсказки Гугла по запросу исходя из выбранной страны, языка или домена.
Парсер Google подсказок решает одну из главных задач SEO, а именно быстрое автоматизированное получение расширенного семанического ядра. Поисковые подсказки google позволяют охватить максимальное количество фраз, а в комплексе с парсером Ключевых Слов Гугл — SE::Google::KeywordPlanner вы получите максимально целостную семантику, которая поможет привлечь больше органического трафика.
Благодаря многопоточной работе A-Parser’a, скорость обработки запросов может достигать 6000 запросов в минуту, что в среднем позволяет получать до 45000 — 46000 результатов в минуту.

Вы можете использовать автоматическое размножение запросов, подстановку подзапросов из файлов, перебор цифро-буквенных комбинаций и списков для получения максимально возможного количества результатов. Используя фильтрацию результатов вы можете сразу почистить результат, удалив весь не нужный мусор (использовав минус-слова).
Функционал A-Parser позволяет сохранять настройки парсинга парсера SE::Google::Suggest для дальнейшего использования (пресеты), задавать расписание парсинга и многое другое.
Сохранение результатов возможно в том виде и структуре которая вам необходима, благодаря встроенному мощному шаблонизатору Template Toolkit который позволяет применять дополнительную логику к результатам и выводить данные в различных форматах, включая JSON, SQL и CSV.
Виды подсказок
На мобильных устройствах применяются подсказки по словам. Пользователь набирает первое слово, после чего ему предлагается на выбор список отдельных слов или выражений. При выборе одного варианта появляются другие подсказки, продолжающие фразу.
В десктопной версии браузера используются полнотекстовые Яндекс-подсказки, представляющие собой целые длинные фразы.
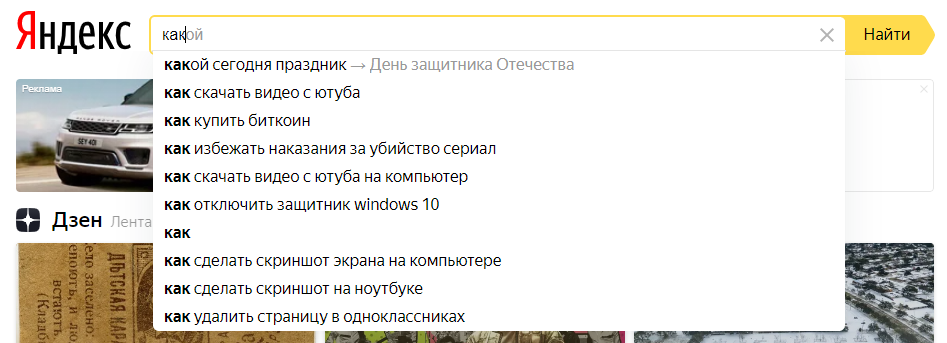
На часть запросов можно увидеть ответы в самих подсказках, к примеру, посмотреть, какой город является столицей определенного государства или узнать длину конкретной реки. То же касается погоды, балла пробок и др.
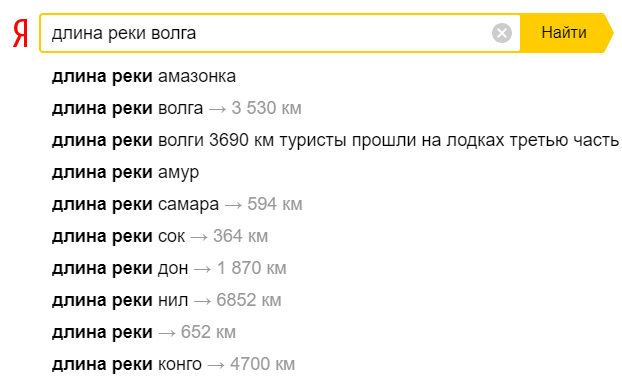
Кроме того, в мобильных версиях браузеров используются подсказки-фактоиды. Например, если ввести слово «погода» или «пробки», ниже строки поиска Яндекс покажет погоду в вашем городе или данные о загруженности дорог.
Также Яндекс предлагает запросы, основанные на истории поиска конкретного пользователя. Если вы зашли на сайт поисковика под своим логином, в качестве поисковых подсказок вам будут предложены ранее вводившиеся вами запросы.
Еще один тип подсказок – навигационные. Если поисковик считает, что оптимальным ответом на запрос пользователя является какой-то определенный сайт, подсказка со ссылкой на него будет показана первой.
getParserPreset#
Получение настроек указанного парсера и пресета.
tip
С помощью этого метода можно получить полный список параметров для использования в других API запросах.
Пример запроса
{
«password»»pass»,
«action»»getParserPreset»,
«data»{
«parser»»SE::Google»,
«preset»»default»
}
}
Скопировать
Пример ответа
{
«success»1,
«data»{
«queryformat»»$query»,
«parsenotfound»1,
«reCaptchaRetries»3,
«pagecount»5,
«gl»»»,
«proxyChecker»»*»,
«hl»»en»,
«domain»»www.google.com»,
«timeout»60,
«Util_ReCaptcha2_preset»»default»,
«useproxy»1,
«nfpr»,
«extraquery»»»,
«serptime»»all»,
«location»»»,
«usesessions»1,
«filter»1,
«linksperpage»100,
«dontTakeSession»,
«addHeaders»»»,
«serp»»»,
«proxyretries»10,
«device»»desktop»,
«requestdelay»,
«debug_nonexists_domains»,
«proxybannedcleanup»600,
«formatresult»»$serp.format(‘$link\\n’)»,
«reCaptchaPassProxy»,
«lr»»»
}
}
Скопировать
Как пользоваться парсером подсказок от Click.ru: пошаговая инструкция
1 Зарегистрируйтесь на Click.ru и перейдите на страницу парсера.
2 Добавьте запросы из эксель-файла или вставьте их списком.
Этап загрузки запросов
3 Выберите нужную поисковую систему и настройте региональность.
Выбор поисковых систем и управление регионами
4 Выберите способы сбора подсказок.По умолчанию подсказки собираются только по заданным запросам. Если нужно собрать семантическое ядро по максимуму, то следует включить дополнительные опции: перебор и/или и/или .
Просто подсказки по запросуА это подсказки по запросу + первая буква алфавита. Большая разница
5 Укажите глубину сбора.
Если оставить первую глубину, то будут собраны подсказки по умолчанию + подсказки, полученные в результате автоподстановок и/или и/или . Если же включить вторую глубину, то вы также получите дополнительные подсказки, собранные по всем словам и фразам первого результата.
Процесс выбора способа и глубины сбора подсказок
6. Запустите проверку.По окончании парсинга отчет можно будет изучить в интерфейсе Click.ru или же скачать на компьютер в эксель-формате.
Стоимость сбора подсказок зависит от количества ТЗ (внутренняя валюта Click.ru). 1 ТЗ — это сбор подсказок в 1 поисковой системе в 1 регионе по 1 фразе. Чтобы сначала попробовать инструмент, платить ничего не надо, так как при регистрации в Click.ru в подарок дается 50 ТЗ.
Парсеры поисковых систем#
| Название парсера | Описание |
|---|---|
| SE::Google | Парсинг всех данных с поисковой выдачи Google: ссылки, анкоры, сниппеты, Related keywords, парсинг рекламных блоков. Многопоточность, обход ReCaptcha |
| SE::Yandex | Парсинг всех данных с поисковой выдачи Yandex: ссылки, анкоры, сниппеты, Related keywords, парсинг рекламных блоков. Максимальная глубина парсинга |
| SE::AOL | Парсинг всех данных с поисковой выдачи AOL: ссылки, анкоры, сниппеты |
| SE::Bing | Парсинг всех данных с поисковой выдачи Bing: ссылки, анкоры, сниппеты, Related keywords, Максимальная глубина парсинга |
| SE::Baidu | Парсинг всех данных с поисковой выдачи Baidu: ссылки, анкоры, сниппеты, Related keywords |
| SE::Baidu | Парсинг всех данных с поисковой выдачи Baidu: ссылки, анкоры, сниппеты, Related keywords |
| SE::Dogpile | Парсинг всех данных с поисковой выдачи Dogpile: ссылки, анкоры, сниппеты, Related keywords |
| SE::DuckDuckGo | Парсинг всех данных с поисковой выдачи DuckDuckGo: ссылки, анкоры, сниппеты |
| SE::MailRu | Парсинг всех данных с поисковой выдачи MailRu: ссылки, анкоры, сниппеты |
| SE::Seznam | Парсер чешской поисковой системы seznam.cz: ссылки, анкоры, сниппеты, Related keywords |
| SE::Yahoo | Парсинг всех данных с поисковой выдачи Yahoo: ссылки, анкоры, сниппеты, Related keywords, Максимальная глубина парсинга |
| SE::Youtube | Парсинг данных с поисковой выдачи Youtube: ссылки, название, описание, имя пользователя, ссылка на превью картинки, кол-во просмотров, длина видеоролика |
| SE::Ask | Парсер американской поисковой выдачи Google через Ask.com: ссылки, анкоры, сниппеты, Related keywords |
| SE::Rambler | Парсинг всех данных с поисковой выдачи Rambler: ссылки, анкоры, сниппеты |
| SE::Startpage | Парсинг всех данных с поисковой выдачи Startpage: ссылки, анкоры, сниппеты |
Какая связь между блоком быстрых ответов Google и long tail запросами
Как мы уже выяснили, в блок быстрых ответов проще всего продвигать лонгриды. Знаете, чем лонгрид отличается от обычной статьи? Тем, что он максимально подробно раскрывает тему и дает ответы на все вопросы читателя. Поэтому лонгриды чаще всего репостят в социальные сети и сохраняют в закладках.
Long tail запросы можно собрать двумя методами. Первый метод – собрать запросы через планировщик ключевых слов Google.
Long tail: как увеличить трафик с помощью низкочастотных запросов.
Второй метод – собрать запросы, используя вопросительные слова и поисковые подсказки.
Что же получается? Мы берем вопросительные long tail запросы, которые пользователи каждый день ищут. Пишем полезный лонгрид, который ответит на все эти вопросы. В результате у нас получается крутой контент, который занимает нулевую позицию по десяткам, а то и сотням запросов и генерирует нам трафик. Плюс, мы получаем дополнительный трафик от репостов социальные сети и повышаем количество возвратов на сайт от добавлений в закладки, что повышает вовлеченность пользователей и еще больше влияет на поисковую выдачу.
Категории подсказок Яндекса
Одно можно утверждать с уверенностью: попасть в поисковые подсказки Яндекса примерно так же сложно, как и в топ. Дело в том, что поисковик использует специальные алгоритмы для формирования и выдачи подсказок
Как они работают? Это важно понимать, чтобы найти пути, по которым ваш брендированный запрос может там оказаться
Подсказки Яндекса делятся на три категории.
- Подсказка-ответ. Например, «Время + в Москве → 12:00».
- Подсказка с уточнением запроса пользователя. Например, «Время + показа фигурного катания сегодня на первом».
- Прямая ссылка на сайт. Например, «Грузоперевозки + по Московской области. Gazelkin.ru».
Пример подсказки-ответа и уточнения запроса
Конечно же, любой бизнес интересуют последние два варианта, которые и являются самыми эффективными. Помимо того, что такие подсказки прекрасно запоминаются аудиторией и подсознательно считаются наиболее релевантными результатами поиска, они ещё и увеличивают посещаемость сайта и хорошо работают как нативная реклама. О том, как в них попасть, чуть ниже, а пока — основные принципы, по которым такие подсказки формируются Яндексом.
Реклама в подсказках поиска Яндекс: как составить список правильных подсказок
Если вы продаёте, например, квартиры, бесполезно рекламировать в качестве подсказки фразу вроде «прекрасная возможность купить квартиры». Она тоже есть, но подобными словосочетаниями редко кто пользуется, так что эффективность стремится к нулю. С этим согласны все, но иногда что-то идет не так, и в качестве основных ключевых слов выбирают совсем не то, что надо.
Почему мы излагаем прописные истины в контексте подсказок? Всё просто — Яндекс не проводит никакой особенной проверки и никак не выделяет один бренд перед другим. Если слово часто употребляют в поиске, система начинает его подсказывать. То есть если вы правильно подберёте свою витальную подсказку, полдела сделано.
Где же искать информацию? Помимо подбора ключевых слов через Яндекс Wordstat, существуют и другие сервисы, которые могут детальнее разобрать поиск буквально на молекулы. Например, это keys.so или MOAB.pro. Из них можно вытащить самые актуальные запросы без конкуренции и с трафиком, в отличие от стандартного инструмента Яндекса, проверить около 100 вариантов, привязать запросы к подсказкам и многое другое. Словом, как следует подготовить почву для завоевания места под солнцем в рекламе подсказок Яндекса.
Последние материалы

Расширение asp. Расширение файла ASP. Проверьте, может ли ваша система обрабатывать Web browser
При наличии на компьютере установленной антивирусной программы
можносканировать все файлы на компьютере, а также каждый файл в отдельности
. Можно выполнить сканирование любого файла, щелкнув правой кнопкой мыши на файл и выбрав соответствующую опцию для.

Выбор домашнего компьютера
Читайте, как выбрать компьютер и на что обратить внимание. Разбираемся чем отличаются кроме цены компьютеры для дома, работы или игр.Сейчас практически в каждом магазине, торгующем техникой, можно найти готовые варианты компьютеров на любой вкус и кошелек.. Фотопринтеры нр
Лучшие фотопринтеры. Лучший компактный фотопринтер

Фотопринтеры нр. Лучшие фотопринтеры. Лучший компактный фотопринтер
Во времена пленочных фотоаппаратов для получения готовой фотографии требовалось довольно много времени. Сфотографировать, проявить пленку, напечатать – и каждый этап был крайне небыстрым.Но в определенный момент наступила эра моментальных фотографий, и им.

Как сделать анимацию в paint и powerpoint?
Paint.net – удобный бесплатный графический редактор, который отчасти может заменить дорогостоящий Adobe Photoshop. Набора его инструментов хватает для обработки фотографий и создания коллажей. В самом редакторе нет возможности создать анимацию, и поэтому .
Как собрать подсказки Youtube: способы
Парсинг подсказок Youtube имеет свои особенности. Платформа не посчитала нужным создавать сервис типа Вордстата, и это усложнило жизнь. Поэтому вариантов для парсинга не так много — то есть, два:
- вручную;
- с помощью сервисов.
Для обоих способов алгоритм действий одинаковый. Поэтому для начала разберемся — что делать и зачем. А потом перейдем к сервисам.
3. Перемножьте фразы с буквами и цифрами
На этом этапе надо взять основную фразу, ввести её в строку поиска и прибавлять все буквы по алфавиту. То же самое можно сделать и с цифрами. Пример на скриншоте.

Выше — пример работы вручную. Но принцип у парсинг-сервисов такой же .
Парсинг html-сайтов с помощью PHP, Ruby, Python
В общем смысле, парсинг – это линейное сопоставление последовательности слов с правилами языка. Понятие «язык» рассматривается в самом широком контексте. Это может быть человеческий язык (например, русский), используемый для коммуникации людей. А может и формализированный язык, в частности, любой язык программирования.
Парсинг сайтов – последовательный синтаксический анализ информации, размещённой на интернет-страницах.
Что представляет из себя текст интернет-страниц? Иерархичный набор данных, структурированный с помощью человеческих и компьютерных языков.
Макросы VBA. Пора использовать Excel правильно!
Зачем нужен парсинг?
Создавая веб-сайт, его владелец неизбежно сталкивается с проблемой – где брать контент? Оптимальный вариант: найти информацию там где её очень много – в Интернете. Но при этом приходится решать такие задачи:
- Большие объёмы. В эпоху бурного роста Сети и жесточайшей конкуренции уже всем ясно, что успешный веб-проект немыслим без размещения большого количества информации на сайте. Современные темпы жизни приводят к тому, что контента должно быть не просто много, а очень много, в количествах, намного превышающих пределы, возможные при ручном заполнении.
- Частое обновление. Обслуживание огромного потока динамично меняющейся информации не в силах обеспечить один человек или даже слаженная команда операторов. Порой информация изменяется ежеминутно и в ручном режиме обновлять её вряд ли целесообразно.
Конвертация CSV в YML. Прайс для Яндекса в нужном формате.
Парсинг сайтов является эффективным решением для автоматизации сбора и изменения информации.
По сравнению с человеком, компьютерная программа-парсер:
- быстро обойдёт тысячи веб-страниц;
- аккуратно отделит техническую информацию от «человеческой»;
- безошибочно отберёт нужное и отбросит лишнее;
- эффективно упакует конечные данные в необходимом виде.
Результат (будь то база данных или электронная таблица), конечно же, нуждается в дальнейшей обработке. Впрочем, последующие манипуляции с собранной информацией уже к теме парсинга не относятся.
Какие языки программирования используются для написания парсеров?
Любые, на которых создаются программы для работы со Всемирной Паутиной. Веб-приложения для парсинга обычно пишут на C++, Delphi, Perl, Ruby, Python, PHP.
Данный сайт создавался для того, чтобы продемонстрировать методы парсинга на самых популярных языках веб-программирования – PHP, Ruby и Python.
Немного истории и теории
В 2004 году поисковые подсказки ввёл Google. На 4 года позже этот удобный инструмент подхватил и Яндекс. Почему удобный? Дело в том, что подсказки существенно экономят время пользователя. Они помогают быстро закончить поисковый запрос, не наделать ошибок и уточнить критерии поиска по наиболее популярным словосочетаниям.
С точки зрения бизнеса подобная возможность также очень привлекательна. Бытует мнение, что раз название компании появляется в подсказках — значит, ею интересуется большое количество людей. Следовательно, такой компании можно доверять. Так что прорекламировать свой бренд подобным образом мечтают многие. Поэтому вопрос о том, как именно попасть в рекламу в подсказках Яндекса, — один из самых популярных в Рунете.
Так выглядит реклама в подсказках Яндекса
Специалисты Яндекса подробно разбирают всех существующие официальные возможности. Помимо них, свои услуги предлагают и дельцы от черного SEO. Их предложение звучит более заманчиво — поставить брендированные, так называемые витальные, поисковые запросы как рекламу в подсказках Яндекса быстро, качественно, дешево и навсегда. Насколько можно доверять подобным предложениям? Как эффективно проложить себе путь к поисковым подсказкам законными методами? Об этом мы с вами и поговорим.
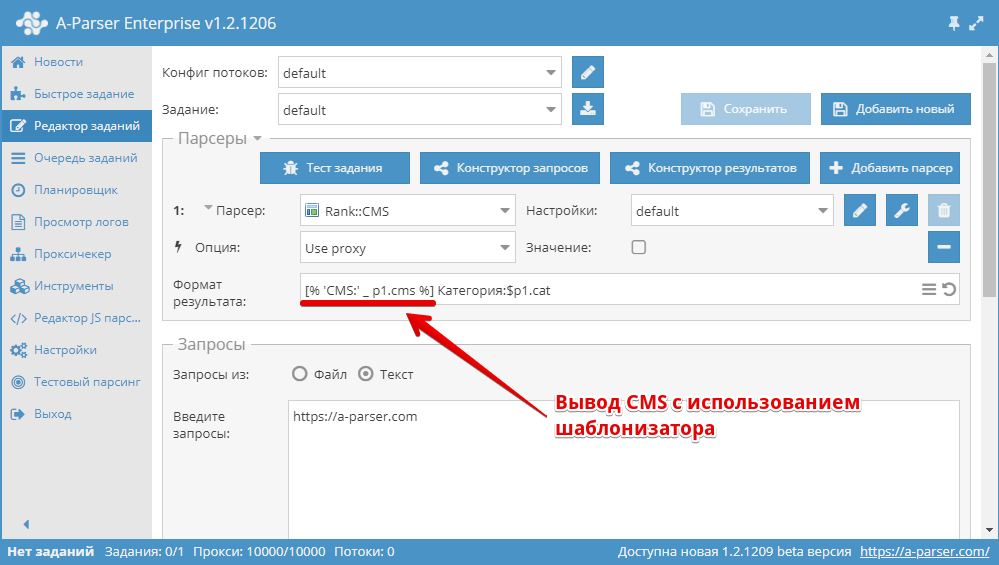
Принципы форматирования#
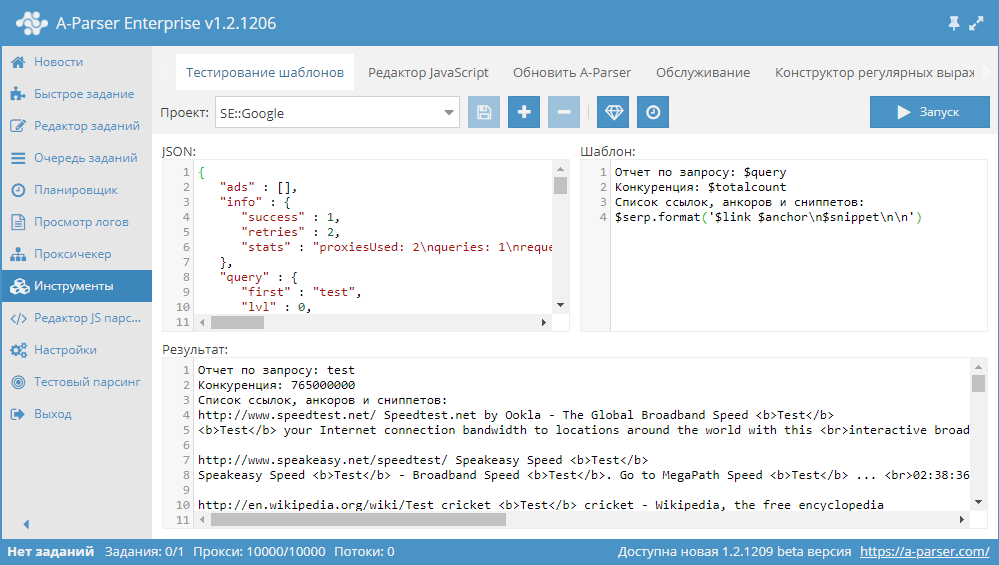
После того как парсер собрал данные в простых результатах и массивах, их необходимо отобразить(сохранить в файл) в нужном формате. Для удобства и функциональности в A-Parser’е используется Шаблонизатор Template Toolkit. Разберем часто используемые конструкции, для этого воспользуемся инструментом Тестирование шаблонов. Выберем проект для парсера SE::Google:

На скриншоте представлены 3 поля:
- JSON — внутреннее представление данных в парсере
- Шаблон — шаблон, по которому происходит форматирование результата
- Результат — непосредственно преобразованные данные по указанному шаблону, именно в таком виде результат будет записан в файл
Изменяя шаблон мы можем менять вид результата, рассмотрим следующий шаблон:
Текст в поле Шаблон:
Отчет по запросу: $query
Конкуренция: $totalcount
Список ссылок, анкоров и сниппетов:
$serp.format(‘$link $anchor\n$snippet\n\n’)
Скопировать
Выделим основные правила:
- Обычный текст выводится в результат как есть, без изменений
- Для вывода простых результатов необходимо в нужном месте вывести переменную содержащую нужный результат с префиксом
- Для форматирования массивов используется метод , о нем немного ниже
- отвечает за перенос строки
Форматирование массивов
Форматирование массивов, разберем конструкцию:
$serp.format(‘$link $anchor\n$snippet\n\n’)
Скопировать
Данная запись означает что для массива необходимо вызвать метод с параметром . Метод соединяет в строку все элементы массива по шаблону, указанному в параметре, сам шаблон означает: для каждого элемента массива вывести ссылку и анкор через пробел, затем с новой строки вывести сниппет, после чего идет еще два переноса строки, в результате образующих пустую строку между результатами.
Для использования шаблонизатора нужно вставить теги , и внутри тегов ввести логику которую нужно выполнить.
Проход по массиву
Для вывода элементов массива нужно использовать конструкцию :
Скопировать
P. S. Помните о сезонности
Вордстат – и, следовательно, парсер тоже – показывает статистику за последние 30 дней. Если запрос сезонный, можно сделать неправильные выводы, если смотреть только один месяц. Сезонные ключи нужно дополнительно проверять на wordstat.yandex.ru в разделе «История запросов»:
Зарегистрируйтесь в Click.ru сейчас и получите доступ к парсеру Wordstat, а также бесплатным инструментам по созданию и управлению контекстной рекламой – умному подборщику слов, генератору объявлений, медиапланеру, автобиддеру. По промокоду key вы в течение месяца сможете апробировать все возможности сервиса и получать максимальное вознаграждение 8 % вне зависимости от суммы расходов на контекстную рекламу.
Как удалить подсказки
Для того, чтобы удалить (отключить) поисковые подсказки, можно воспользоваться одним из нижеприведенных способов:
1. Полностью отключить подсказки в настройках.
Например, для Яндекса необходимо:
- перейти в «Настройки», ссылка на которые расположена под поисковой выдачей,
- перейти к «Настройка поиска»,
- убрать галочки в соответствующих полях и нажать «Сохранить».
2. Очистить историю браузера на десктопе или мобильном устройстве, чтобы таким образом избавиться от пользовательского опыта, используемого при формировании поисковых подсказок.
3. Если требуется удалить какую-то отдельную подсказку, можно воспользоваться «крестиком» напротив нее в Яндексе либо перейти на ненужную фразу и нажать Shift+Del в Google.
Формат имени файла результатов#
A-Parser позволяет использовать шаблоны также в именах результирующих файлов, что позволяет автоматически создавать файлы и папки на основе текущей даты, по порядковому номеру запроса, по самому запросу и в любом другом формате.
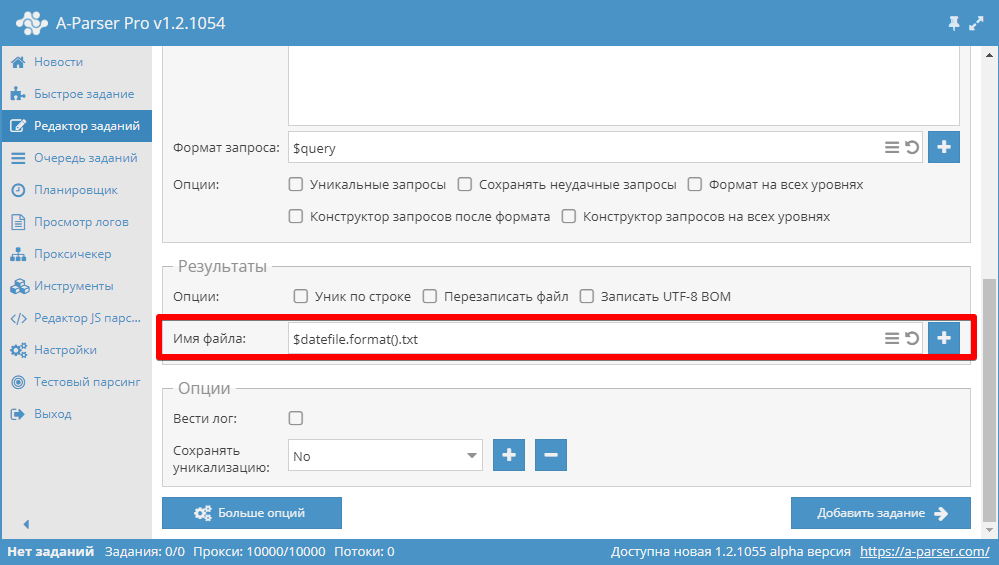
В поле Имя файла поддерживаются следующие переменные:
- Все переменные доступные для Общего формата результата
- — путь и имя файла с запросами, если запросы указаны через форму то будет содержать queries_from_text.txt
- — объект плагина date шаблонизатора Template Toolkit, настроенный на формат даты , при форматировании выдаёт текущее время и дату в виде May-08_20-08-38, формат возможно изменить в Дополнительных настройках
По умолчанию имя файла создаётся по дате и времени на момент старта задания
Комплексный пример
reports$queriesfile${query}.txt
Скопировать
- Будет создана папка reports
- Будет создана подпапка с именем файла запросов
- В подпапке будет создано столько файлов сколько запросов используется в задании, в качестве имени файла будет использоваться сам запрос с расширением .txt
tip
Переменная $query записана в формате ${query} для того чтобы предотвратить интерполяцию расширения .txt как части переменной, подробнее в документации по шаблонизатору Template Toolkit
Видео. Именование файлов результатов
В этом видео приведем несколько примеров именования файла результата:
- Нумерация файла результата в соответствии с запросами.
- Нумерация файла результата + часть имени запроса.
- Именование файла результата по запросу, если запрос линк.
Парсинг: что это такое простыми словами
Парсинг — это процесс автоматического сбора информации по заданным нами критериям. Для лучшего понимания давайте разберем пример:
Грубо говоря парсинг позволяет автоматизировать сбор любой информации по заданным нами критериям. Думаю понятно, что использовать ручной способ сбора информации малоэффективно (особенно в наше время, когда информации слишком много).
Для наглядности хочу сразу показать главные преимущества парсинга:
Преимущество №1 — Скорость. За одну единицу времени автомат может выдавать в разы больше деталей или в нашем случае информации, чем, если бы мы с лупой в руках отыскивали ее на страницах сайта. Поэтому компьютерные технологии в обработке информации превосходят ручной сбор данных.
Преимущество №2 — Структура или «скелет» будущего отчета. Мы собираем лишь те данные, которые заинтересованы получить. Это может быть что угодно. Например, цифры (цена, количество), картинки, текстовое описание, электронные адреса, ФИО, никнеймы, ссылки и прочее. Нам нужно только заранее обдумать, какую информацию мы хотим получить.
Преимущество №3 — Подходящий вид отчета. Мы получаем итоговый файл с массивом данных в требуемом формате (XLSX, CSV, XML, JSON) и можем даже сразу использовать его, вставив в нужное место на своем сайте.
Если говорить о наличие минусов, то это, разумеется, отсутствие у полученных данных уникальности. Прежде всего, это относится к контенту, мы ведь собираем все из открытых источников и парсер не уникализирует собранную информацию.
Думаю, что с понятием парсинга мы разобрались, теперь давайте разберемся со специальными программами и сервисами для парсинга.
Возможности и преимушества#
Многопоточность и производительность
- A-Parser работает на основе последних версий NodeJS и JavaScript движка V8
- AsyncHTTPX — собственная реализация HTTP движка с поддержкой HTTP/1.1 и HTTP/2, HTTPS/TLS, поддержка прокси HTTP/SOCKS4/SOCKS5 с опциональной авторизацией
- в зависимости от конфигурации компьютера и решаемой задачи
- Каждое задание(набор запросов) парсится в указанное число потоков
- При использовании нескольких парсеров в одном задании каждый запрос к разным парсерам выполняется в разных потоках одновременно
- Парсер умеет запускать несколько заданий параллельно
- также проходит в многопоточном режиме
Создание собственных парсеров
- Возможность создания парсеров без написания кода
- Использование регулярных выражений
- Поддержка многостраничного парсинга
- Вложенный парсинг — возможность
- Полноценная : разбор и формирование
- их для обработки полученных результатов прямо в парсере
Создание парсеров на языке JavaScript
- Богатое встроенное API на основе async/await
- Поддержка
- Возможность подключения любых NodeJS модулей
- Управление Chrome/Chromium через puppeteer с поддержкой раздельных прокси для каждой вкладки
Мощные инструменты для формирования запросов и результатов
- Конструктор запросов и результатов — позволяет видоизменять данные(поиск и замена, выделение домена из ссылки, преобразования по регулярным выражениям, XPath…)
- : из файла; перебор слов, символов и цифр, в том числе с заданным шагом
- Фильтрация результатов — по вхождению подстроки, равенству, больше\меньше
- Уникализация результатов — по строке, по домену, по главному домену(A-Parser знает все домены верхнего уровня, в т.ч. такие как co.uk, msk.ru)
- Мощный шаблонизатор результатов на основе — позволяет выводить результаты в любом удобном виде(текстом, csv, html, xml, произвольный формат)
- В парсере используется система пресетов — для каждого парсера можно создать множество предустановленных настроек для различных ситуаций
- Настроить можно все — никаких рамок и ограничений
- и настроек позволяет легко обмениваться опытом с другими пользователями
API
- Возможность интегрировать и управлять парсером из своих программ и скриптов
- Полная автоматизация бизнес-процессов
- Клиенты для PHP, NodeJs, Perl и Python
Заключение
Самое главное – не перестарайтесь с SEO-оптимизацией. В первую очередь вы должны писать для людей, и лишь во вторую очередь для машин. Создавайте авторский контент, ориентируясь на предпочтения своей аудитории. Наполняйте контент пользой – от простых советов до пошаговых инструкций. И обязательно общайтесь со своей аудиторией, собирайте обратную связь.
Не забывайте, что самые большие результаты дает комплексное продвижение. Каждый канал работает эффективнее, когда его усиливают другие.
Google рассказал в своем блоге, что в самое ближайшие время начнёт удалять больше разновидностей поисковых подсказок. Это нововведение призвано обезопасить пользователей от шокирующего или оскорбительного контента.
Сразу Вас успокою, данные новости никак не коснутся нормальных подсказок и Вы можете их продвигать как и раньше, наоборот данное сообщение в очередной раз напрямую доказывает, что на появление подсказок может оказывать прямое воздействие.
Функция автозаполнения в поиске Google неоднократно становилась объектом недовольства общественности. Неоднократно, пользователи жаловались на ксенофобские и расистские подсказки. Результаты, выдаваемые этим функционалом очень часто попадали в судебные разбирательства по всему миру.
Несмотря на все вышеперечисленное, Google продолжает доказывать, что эти результаты являются лишь результатом большого количества определенных запросов пользователей. При этом компания не отказывается от их модерации, устанавливая определенные рамки, а также удаляя ужасные подсказки в ручном режиме.
На этой неделе в Google в очередной раз заявили, что функционал подсказок основан на информации «реальных поисковых сессий и возвращает распространённые и трендовые запросы, релевантные тем символам, которые были набраны, а также местоположению и истории поиска пользователя».



