Создание первичных ключей
Содержание:
Первичный ключ
Столбец, который в базе данных должен быть уникальным помечают первичным ключом. Первичный ключ или primary key означает, что в таблице значение колонки primary key не может повторяться. Таким образом данный ключ позволяет однозначно идентифицировать запись в таблице не боясь при этом, что значение столбца повториться. Сразу пример: допустим у Вас есть таблица пользователей. В данной таблице есть поля: ФИО, год рождения, телефон. Как идентифицировать пользователя? Таким параметрам как ФИО и телефон доверять нельзя. Ведь у нас может быть несколько пользователей не только с одинаковой фамилией, но и с именем. Телефон может меняться со временем и пользователь с номером телефона может оказаться не тем кто у нас в базе данных.
Вот для этого и придумали первичный ключ. Один раз присвоили уникальный идентификатор и все. В mySql на примере которой мы выполняем все примеры из цикла статей по SQL поле AUTO_INCREMENT нельзя задать если не указать, что это первичный ключ.
К стати, в предыдущей теме мы уже познакомились с первичным ключом: что это такое и как его создавать. Синтаксис по созданию этого ключа Вы найдете в статье Создание, изменение, удаление таблиц SQL.
Думаю, что не стоит упоминать, что поле помеченное как первичный ключ не может быть пустым при создании записи.
Первичный и уникальный ключи
Скрыть рекламу в статье
Первичный и уникальный ключи
Первичные ключи являются одним из основных видов ограничений в базе данных. Они применяются для однозначной идентификации записей в таблице. Допустим, мы храним в базе данных список людей. Вполне вероятно, что могут появиться два (или больше) человека с одинаковыми фамилией, именем и отчеством Как же гарантированно отличить одного человека от другого (конечно. речь идет о том, чтобы отличить одного человека от другого на основании информации, хранящейся в базе данных)?
В данном случае «человек» представлен одной записью в таблице, поэтому можно задаться более общим вопросом — как отличить одну запись в (любой) таблице от другой записи в этой же таблице. Для этого используются ограничения — первичные кпочи. Первичный ключ представляет собой одно или несколько полей в таблице, сочетание которых уникально для каждой записи. Для одной таблицы не существует повторяющихся значений первичного ключа.
Уникальные кчочи несут аналогичную нагрузку — они также служат для однозначной идентификации записей в таблице. Отличие первичных ключей от уникальных состоит в том, что первичный ключ может быть в таблице только один, а уникатьных ключей — несколько. Надо отметить, что и первичный и уникальный ключ могут быть использованы в качестве ссылочной основы для внешних ключей (см. далее).
Синтаксис создания первичного и уникального ключа на основе единственного поля следующий:
<pkukconstraint> = {PRIMARY KEY |
UNIQUE}
Примеры первичных и уникальных ключей:
CREATE TABLE pkuk(
pk NUMERIC(15,0) NOT NULL PRIMARY KEY, /*первичный ключ*/
ukl VARCHAR(SO) NOT NULL UNIQUE,/*уникальный ключ */
uk2 INTEGER NOT NULL UNIQUE /* еще уникальный ключ */);
Синтаксис создания первичного и уникального ключей на основе нескольких полей:
<pkuktconstraint> = {PRIMARY KEY |
UNIQUE) ( col )
Такой синтаксис позволяет создавать ключи на основе комбинации полей. Вот примеры создания первичных и уникальных ключей из нескольких полей:
CREATE TABLE pkuk2(
Number1 INTEGER NOT NULL,
Namel VARCHAR(SO) NOT NULL,
Kol INTEGER NOT NULL,
Stoim NUMERIC(15,4) NOT NULL,
CONSTRAINT pkt PRIMARY KEY (Numberl, Namel), /*первичный ключ pkt на
основе двух полей*/
CONSTRAINT uktl UNIQUE (kol, Stoim) ); /*уникальный ключ uktl на основе
двух полей*/
Обратите внимание, что все поля, входящие в состав первичного и уникального ключей, должны быть объявлены как NOT NULL, так как эти ключи не могутиметь неопределенного значения. Помимо создания ограничения первичных и уникальных ключей в момент создания таблицы имеется возможность добавлять ограничения в уже существующую таблицу
Для этого используется предложение DDL: ALTER TABLE. Синтаксис добавтения ограничений первичного или уникального ключа в существующую таблицу аналогичен описанному выше:
Помимо создания ограничения первичных и уникальных ключей в момент создания таблицы имеется возможность добавлять ограничения в уже существующую таблицу. Для этого используется предложение DDL: ALTER TABLE. Синтаксис добавтения ограничений первичного или уникального ключа в существующую таблицу аналогичен описанному выше:
ALTER TABLE tablename
ADD {PRIMARY KEY | UNIQUE) ( col )
Давайте рассмотрим пример создания первичного и уникального ключа с помощью ALTER TABLE. Сначала создаем таблицу:
CREATE TABLE pkalter(
ID1 INTEGER NOT NULL,
ID2 INTEGER NOT NULL,
UID VARCHAR(24));
Затем добавляем ключи. Сначала первичный:
ALTER TABLE pkalter
ADD CONSTRAINT pkall PRIMARY KEY (idl, id2);
Затем уникальный ключ:
ALTER TABLE pkalter
ADD CONSTRAINT ukal UNIQUE (uid) ;
Важно отметить, что добавление (а также удаление) ограничений первичных и уникальных ключей к таблице может производить только владелец этой таблицы или системный администратор SYSDBA (подробнее о владельцах и пользователе SYSDBA см. главу «Безопасность в InterBase: пользователи, роли и права») (ч
4).
Оглавление книги
Представление в базе данных
Рассмотрим пример таблицы в базе данных с обоими видами ключей:
|
ПРИМЕЧАНИЕ
В качестве базы данных далее рассматривается MS SQL Server 2008. В качестве предметной области выберем Web-сайты, обрабатывающие ссылки на социальные истории. Примером таких Web-сайтов являются сайты DIGG, KIGG. |
Ниже приведен SQL-скрипт, описывающий таблицу, хранящую информацию о социальных историях.
IF
NOT
EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'.') AND type in (N'U'))
BEGINCREATETABLE .(
IDENTITY(1,1) NOTNULL,
(50) NOTNULL,
(50) NOTNULL,
(400) NOTNULL,
CONSTRAINT PRIMARYKEYCLUSTERED
(
ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON
) ON
END
|
В данном примере у нас суррогатный ключ Id является первичным ключом, а поля Title и Url входят в дополнительный ключ. Уникальность обеспечивается следующим ограничением (constraint):
IF
NOT
EXISTS (
SELECT *
FROM sys.indexes
WHERE object_id = OBJECT_ID(N'.')
AND name = N'IX_NK_TitleUrl'
)
CREATEUNIQUENONCLUSTEREDINDEX ON .
(
ASC,
ASC
) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF,
DROP_EXISTING = OFF, ONLINE = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
ON
|
Foreign Key Constraints
Внешний ключ (FK) — это столбец или сочетание столбцов, которое применяется для принудительного установления связи между данными в двух таблицах с целью контроля данных, которые могут храниться в таблице внешнего ключа. Если один или несколько столбцов, в которых находится первичный ключ для одной таблицы, упоминается в одном или нескольких столбцах другой таблицы, то в ссылке внешнего ключа создается связь между двумя таблицами. Этот столбец становится внешним ключом во второй таблице.
Например, таблица связана с таблицей с помощью внешнего ключа, так как существует логическая связь между заказами на продажу и менеджерами по продажам. Столбец в таблице соответствует столбцу первичного ключа таблицы . Столбец в таблице является внешним ключом таблицы . С помощью установления данной связи по внешнему ключу значение для не может быть вставлено в таблицу , если оно в настоящий момент не содержится в таблице .
Максимальное количество таблиц и столбцов, на которые может ссылаться таблица в качестве внешних ключей (исходящих ссылок), равно 253. SQL Server 2016 (13.x); увеличивает ограничение на количество других таблиц и столбцов, которые могут ссылаться на столбцы в одной таблице (входящие ссылки), с 253 до 10 000. (Требуется уровень совместимости не менее 130.) Увеличение имеет следующие ограничения:
-
Превышение 253 ссылок на внешние ключи поддерживается только для операций DML DELETE. Операции UPDATE и MERGE не поддерживаются.
-
Таблица со ссылкой внешнего ключа на саму себя по-прежнему ограничена 253 ссылками на внешние ключи.
-
Превышение 253 ссылок на внешние ключи в настоящее время недоступно для индексов columnstore, оптимизированных для памяти таблиц, базы данных Stretch или секционированных таблиц внешнего ключа.
Создание файла базы данных
При запуске Access открывается диалоговое окно — Окно запуска, в котором предлагается создать новую БД, запустить Мастера БД или открыть существующую БД.
В Access поддерживаются два способа создания БД. Можно создать пустой файл БД, а затем разрабатывать таблицы, формы, отчеты и другие объекты, добавляя их в БД. Такой способ является профессиональным и наиболее гибким, но требует отдельного определения каждого элемента БД. При выборе такого способа создания БД надо в окне запуска установить флажок Новая база данных. В раскрывшемся окне Файл новой базы данных следует выбрать каталог и задать имя создаваемой БД. Раскроется Окно базы данных.
Вниманию студентов! Студенческие БД должны создаваться в директории StudentGRNNN.
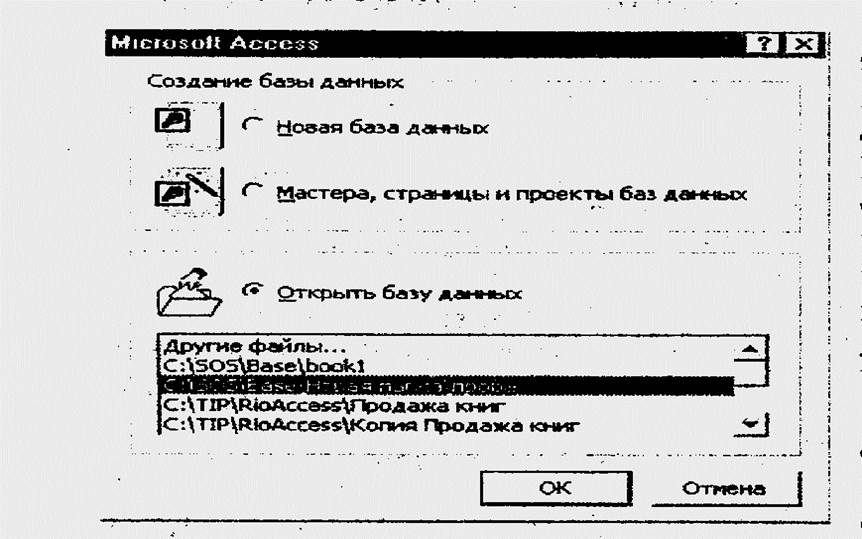
Для создания БД можно воспользоваться Мастером базы данных, установив в окне запуска флажок Мастера, страницы и проекты. Мастер создает БД, содержащую все необходимые объекты, и остается только ввести в таблицы данные. Это простейший способ начального создания БД, но в этом случае придется пользоваться шаблоном, предлагающим определенную структуру БД. Мастера баз данных нельзя использовать для добавления новых таблиц, форм, отчетов в уже существующую БД.
Флажок Открыть базу данных окна запуска позволяет открыть ранее
созданную БД, выбрав ее имя из предлагаемого списка. При выборе Другие файлы предоставляется каталог, из которого можно открыть нужную БД.
- АлтГТУ 419
- АлтГУ 113
- АмПГУ 296
- АГТУ 266
- БИТТУ 794
- БГТУ «Военмех» 1191
- БГМУ 172
- БГТУ 602
- БГУ 153
- БГУИР 391
- БелГУТ 4908
- БГЭУ 962
- БНТУ 1070
- БТЭУ ПК 689
- БрГУ 179
- ВНТУ 119
- ВГУЭС 426
- ВлГУ 645
- ВМедА 611
- ВолгГТУ 235
- ВНУ им. Даля 166
- ВЗФЭИ 245
- ВятГСХА 101
- ВятГГУ 139
- ВятГУ 559
- ГГДСК 171
- ГомГМК 501
- ГГМУ 1967
- ГГТУ им. Сухого 4467
- ГГУ им. Скорины 1590
- ГМА им. Макарова 300
- ДГПУ 159
- ДальГАУ 279
- ДВГГУ 134
- ДВГМУ 409
- ДВГТУ 936
- ДВГУПС 305
- ДВФУ 949
- ДонГТУ 497
- ДИТМ МНТУ 109
- ИвГМА 488
- ИГХТУ 130
- ИжГТУ 143
- КемГППК 171
- КемГУ 507
- КГМТУ 269
- КировАТ 147
- КГКСЭП 407
- КГТА им. Дегтярева 174
- КнАГТУ 2909
- КрасГАУ 370
- КрасГМУ 630
- КГПУ им. Астафьева 133
- КГТУ (СФУ) 567
- КГТЭИ (СФУ) 112
- КПК №2 177
- КубГТУ 139
- КубГУ 107
- КузГПА 182
- КузГТУ 789
- МГТУ им. Носова 367
- МГЭУ им. Сахарова 232
- МГЭК 249
- МГПУ 165
- МАИ 144
- МАДИ 151
- МГИУ 1179
- МГОУ 121
- МГСУ 330
- МГУ 273
- МГУКИ 101
- МГУПИ 225
- МГУПС (МИИТ) 636
- МГУТУ 122
- МТУСИ 179
- ХАИ 656
- ТПУ 454
- НИУ МЭИ 641
- НМСУ «Горный» 1701
- ХПИ 1534
- НТУУ «КПИ» 212
- НУК им. Макарова 542
- НВ 777
- НГАВТ 362
- НГАУ 411
- НГАСУ 817
- НГМУ 665
- НГПУ 214
- НГТУ 4610
- НГУ 1992
- НГУЭУ 499
- НИИ 201
- ОмГТУ 301
- ОмГУПС 230
- СПбПК №4 115
- ПГУПС 2489
- ПГПУ им. Короленко 296
- ПНТУ им. Кондратюка 119
- РАНХиГС 186
- РОАТ МИИТ 608
- РТА 243
- РГГМУ 118
- РГПУ им. Герцена 124
- РГППУ 142
- РГСУ 162
- «МАТИ» — РГТУ 121
- РГУНиГ 260
- РЭУ им. Плеханова 122
- РГАТУ им. Соловьёва 219
- РязГМУ 125
- РГРТУ 666
- СамГТУ 130
- СПбГАСУ 318
- ИНЖЭКОН 328
- СПбГИПСР 136
- СПбГЛТУ им. Кирова 227
- СПбГМТУ 143
- СПбГПМУ 147
- СПбГПУ 1598
- СПбГТИ (ТУ) 292
- СПбГТУРП 235
- СПбГУ 582
- ГУАП 524
- СПбГУНиПТ 291
- СПбГУПТД 438
- СПбГУСЭ 226
- СПбГУТ 193
- СПГУТД 151
- СПбГУЭФ 145
- СПбГЭТУ «ЛЭТИ» 380
- ПИМаш 247
- НИУ ИТМО 531
- СГТУ им. Гагарина 114
- СахГУ 278
- СЗТУ 484
- СибАГС 249
- СибГАУ 462
- СибГИУ 1655
- СибГТУ 946
- СГУПС 1513
- СибГУТИ 2083
- СибУПК 377
- СФУ 2423
- СНАУ 567
- СумГУ 768
- ТРТУ 149
- ТОГУ 551
- ТГЭУ 325
- ТГУ (Томск) 276
- ТГПУ 181
- ТулГУ 553
- УкрГАЖТ 234
- УлГТУ 536
- УИПКПРО 123
- УрГПУ 195
- УГТУ-УПИ 758
- УГНТУ 570
- УГТУ 134
- ХГАЭП 138
- ХГАФК 110
- ХНАГХ 407
- ХНУВД 512
- ХНУ им. Каразина 305
- ХНУРЭ 324
- ХНЭУ 495
- ЦПУ 157
- ЧитГУ 220
- ЮУрГУ 306
Полный список ВУЗов
Чтобы распечатать файл, скачайте его (в формате Word).
Проектирование базы данных
Основой любой реляционной БД являются таблицы. Разработка таблиц является одним из наиболее сложных этапов в проектировании БД. Грамотно спроектированные таблицы являются основой для создания работоспособной и эффективной БД.
Понятие таблицы в Access полностью соответствует аналогичному понятию реляционной модели данных. Любая таблица реляционной БД состоит из строк (называемых также записями) и столбцов (называемых также полями).
Строки таблицы содержат сведения об однотипных объектах — документах, людях, предметах. На пересечении столбца и строки находится конкретное значение, характеризующее объект.
Можно сформулировать ряд основных требований, которым должны удовлетворять таблицы.
1. Информация в таблице не должна дублироваться, т.е. в таблице не должно существовать двух записей с полностью совпадающим набором значений ее полей.
2. На пересечении любого столбца и любой строки должно находиться одно
3. Не рекомендуется включать в таблицу данные, которые являются результатом вычислений.
4. Значения данных в одном и том же столбце должны принадлежать к одному и тому же типу, доступному для использования в данной СУБД.
5. Каждое поле должно иметь уникальное имя.
6. Каждая таблица должна иметь первичный ключ.
7. Таблицы БД должны быть связаны через внешние ключи.
Каждая таблица должна содержать поле (или набор из нескольких полей), значения в котором однозначно идентифицируют каждую запись в таблице. Такое поле (или набор полей) называется ключевым полем таблицы или первичным ключом. Первичный ключ любой таблицы обязан содержать уникальные непустые значения для каждой записи. Если для таблицы обозначены ключевые поля, то Access предотвращает дублирование или ввод пустых значений в ключевое поле.
В Access можно выделить три типа ключевых полей: простой ключ, составной ключ и поле счетчика.
Если поле содержит уникальные значения, такие как коды или инвентарные номера, то это поле можно определить как простой первичный ключ. Если в этом поле появятся повторяющиеся или пустые значения, Access выведет сообщение об ошибке.
В случаях, когда невозможно гарантировать уникальность значений ни одного из полей, можно создать ключ, состоящий из нескольких полей — составной первичный ключ. Для составного ключа существенным может оказаться порядок образующих ключ полей. Не рекомендуется определять ключ по полям Имена и Фамилии, поскольку нельзя исключить повторения этой пары значений для разных людей.
Составной ключ необходим для таблицы, используемой для связывания двух таблиц в отношении «многие — ко — многим» Обычно такой ключ состоит из ключевых полей связываемых таблиц.
Если для какой-либо таблицы не удалось определить простой первичный ключ или найти подходящий набор полей для составного ключа, можно добавить в таблицу поле счетчика и сделать его ключевым. При создании каждой новой записи Access генерирует уникальный номер записи, называемый счетчиком. Указание такого поля в качестве ключевого является наиболее простым способом создания ключевых полей.
Если до сохранения созданной таблицы ключевые поля не были определены, то при сохранении будет выдано предложение о создании системой ключевого поля. При ответе Да будет создано ключевое поле счетчика.
Сила реляционных баз данных, таких как БД Microsoft Access, заключается в том, что они могут быстро найти и связать данные из разных таблиц при помощи запросов, форм и отчетов. Таблицы реляционных БД связываются через одинаковые значения одноименных полей, содержащихся в связываемых таблицах. Такие поля называются внешним ключом для этих таблиц. Все таблицы БД Access должны быть связаны с помощью внешних ключей.
1.2.5. Первичный ключ
Мы уже достаточно много говорили про ключевые поля, но ни разу их не использовали. Самое интересное, что все работало. Это преимущество, а может недостаток базы данных Microsoft SQL Server и MS Access. В таблицах Paradox такой трюк не пройдет и без наличия ключевого поля таблица будет доступна только для чтения.
В какой-то степени ключи являются ограничениями, и их можно было рассматривать вместе с оператором CHECK, потому что объявление происходит схожим образом и даже используется оператор CONSTRAINT. Давайте посмотрим на этот процесс на примере. Для этого создадим таблицу из двух полей «guid» и «vcName». При этом поле «guid» устанавливается как первичный ключ:
CREATE TABLE Globally_Unique_Data ( guid uniqueidentifier DEFAULT NEWID(), vcName varchar(50), CONSTRAINT PK_guid PRIMARY KEY (Guid) )
Самое вкусное здесь это строка CONSTRAINT. Как мы знаем, после этого ключевого слова идет название ограничения, и объявления ключа не является исключением. Для именования первичного ключа, я рекомендую использовать именование типа PK_имя, где имя – это имя поля, которое должно стать главным ключом. Сокращение PK происходит от Primary Key (первичный ключ).
После этого, вместо ключевого слова CHECK, которое мы использовали в ограничениях, стоит оператор PRIMARY KEY, Именно это указывает на то, что нам необходима не проверка, а первичный ключ. В скобках указывается одно, или несколько полей, которые будут составлять ключ.
Помните, что в ключевом поле не может быть одинакового значения у двух строк, в этом ограничение первичного ключа идентично ограничению уникальности. Это значит, что если сделать поле для хранения фамилии первичным ключом, то в такую таблицу нельзя будет записать двух Ивановых с разными именами. Это нарушает ограничение первичного ключа. Именно поэтому ключи являются ограничениями и объявляются также как и ограничение CHECK. Но это не верно только для первичных ключей и вторичных с уникальностью.
В данном примере, в качестве первичного ключа выступает поле типа uniqueidentifier (GUID). Значение по умолчанию для этого поля – результат выполнения серверной процедуры NEWID.
Внимание
Только один первичный ключ может быть создан для таблицы
Для простоты примеров, в качестве ключа желательно использовать численный тип и если позволяет база данных, то будет лучше, если он будет типа «autoincrement» (автоматически увеличивающееся/уменьшающееся число). В MS SQL Server таким полем является IDENTITY, а в MS Access это поле типа «счетчик».
Следующий пример показывает, как создать таблицу товаров, в которой в качестве первичного ключа выступает целочисленное поле с автоматическим увеличением:
CREATE TABLE Товары ( id int IDENTITY(1, 1), товар varchar(50), Цена money, Количество numeric(10, 2), CONSTRAINT PK_id PRIMARY KEY (id) )
Именно такой тип ключа мы будем использовать чаще всего, потому что в ключевом поле будут храниться легкие для восприятия числа и с ними проще и нагляднее работать.
Первичный ключ может состоять из более, чем одной колонки. Следующий пример создает таблицу, в которой поля «id» и «Товар» образуют первичный ключ, а значит, будет создан индекс уникальности на оба поля:
CREATE TABLE Товары1
(
id int IDENTITY(1, 1),
Товар varchar(50),
Цена money,
Количество numeric(10, 2),
CONSTRAINT PK_id PRIMARY KEY
(id, )
)
Очень часто программисты создают базу данных с ключевым полем в виде целого числа, но при этом в задаче четко стоит, что определенные поля должны быть уникальными. А почему не создать сразу первичный ключ из тех полей, которые должны быть уникальны и не надо будет создавать отдельные решения для данной проблемы.
Единственный недостаток первичного ключа из нескольких колонок – проблемы создания связей. Тут приходиться выкручиваться различными методами, но проблема все же решаема. Достаточно только ввести поле типа uniqueidentifier и производить связь по нему. Да, в этом случае у нас получаются уникальными первичный ключ и поле типа uniqueidentifier, но эта избыточность в результате не будет больше, чем та же таблица, где первичный ключ uniqueidentifier, а на поля, которые должны быть уникальными установлено ограничение уникальности. Что выбрать? Зависит от конкретной задачи и от того, с чем вам удобнее работать.
Определение сущностей
На этом этапе вам необходимо определить сущности, из которых будет состоять база данных.
Сущность — это объект в базе данных, в котором хранятся данные. Сущность может представлять собой нечто вещественное (дом, человек, предмет, место) или абстрактное (банковская операция, отдел компании, маршрут автобуса). В физической модели сущность называется таблицей.
Сущности состоят из атрибутов (столбцов таблицы) и записей (строк в таблице).
Обычно базы данных состоят из нескольких основных сущностей, связанных с большим количеством подчиненных сущностей. Основные сущности называются независимыми: они не зависят ни от какой-либо другой сущности. Подчиненные сущности называются зависимыми: для того чтобы существовала одна из них, должна существовать связанная с ней основная таблица.
На диаграммах сущности обычно представляются в виде прямоугольников. Имя сущности указывается внутри прямоугольника:
Любая таблица имеет следующие характеристики:
- в ней нет одинаковых строк;
- все столбцы (атрибуты) в таблице должны иметь разные имена;
- элементы в пределах одной колонки имеют одинаковый тип (строка, число, дата);
- порядок следования строк в таблице может быть произвольным.
На этом этапе вам необходимо выявить все категории информации (сущности), которые будут храниться в базе данных.
Ссылочная целостность
Первое из правил ссылочной целостности фактически уже изложено в предыдущем абзаце: в таблице не допускается появления (неважно, при добавлении или при модификации) строк, внешний ключ которых не совпадает с каким-либо из имеющихся значений родительского ключа. Более интересные моменты возникают, когда мы удаляем или изменяем строки родительской таблицы
Как при этом не допустить появления \»болтающихся в воздухе\» строк дочерней таблицы? Для этого существуют правила ссылочной целостности ON UPDATE и ON DELETE, которые, по стандарту SQL 92, могут содержать следующие инструкции:
Более интересные моменты возникают, когда мы удаляем или изменяем строки родительской таблицы. Как при этом не допустить появления \»болтающихся в воздухе\» строк дочерней таблицы? Для этого существуют правила ссылочной целостности ON UPDATE и ON DELETE, которые, по стандарту SQL 92, могут содержать следующие инструкции:
- CASCADE — обеспечивает автоматическое выполнение в дочерней таблице тех же изменений, которые были сделаны в родительском ключе. Если родительский ключ был изменен — ON UPDATE CASCADE обеспечит точно такие же изменения внешнего ключа в дочерней таблице. Если строка родительской таблицы была удалена, ON DELETE CASCADE обеспечит удаление всех соответствующих строк дочерней таблицы.
- SET NULL — при удалении строки родительской таблицы ON DELETE SET NULL установит значение NULL во всех столбцах вторичного ключа в соответствующих строках дочерней таблицы. При изменении родительского ключа ON UPDATE SET NULL установит значение NULL в соответствующих столбцах соответствующих строк (о как:) дочерней таблицы.
- SET DEFAULT — работает аналогично SET NULL, только записывает в соответствующие ячейки не NULL, а значения, установленные по умолчанию.
- NO ACTION (установлено по умолчанию) — при изменении родительского ключа никаких действий с внешним ключом в дочерней таблице не производится. Но если изменение значений родительского ключа приводит к нарушению ссылочной целосности (т.е. к появлению «висящих в воздухе» строк дочерней таблицы), то СУБД не даст произвести такие изменения родительской таблицы.
Ну а сейчас — от общего к частному.
SQL PRIMARY KEY в CREATE TABLE
Следующий SQL создает первичный ключ в столбце «ID» при создании таблицы «Persons»:
MySQL:
CREATE TABLE Persons
(
ID int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int,
PRIMARY KEY (ID)
);
SQL Server / Oracle / MS Access:
CREATE TABLE Persons
(
ID int NOT NULL PRIMARY KEY,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int
);
Чтобы разрешить именование ограничения PRIMARY KEY и определить ограничение PRIMARY KEY для нескольких столбцов, используйте следующий синтаксис SQL:
MySQL / SQL Server / Oracle / MS Access:
CREATE TABLE Persons
(
ID int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int,
CONSTRAINT PK_Person PRIMARY KEY (ID,LastName)
);
Примечание: В приведенном выше примере существует только один первичный ключ (PK_Person).
Однако значение первичного ключа состоит из TWO COLUMNS (ID + LastName).


