База данных субд access
Содержание:
- В чём преимущества
- Встраиваемые
- Сетевая модель базы данных
- Классификация Structured Query Language
- Ключ-значение
- Создание базы данных с помощью шаблона
- NoSQL как альтернатива традиционным БД
- Какую СУБД мы изучаем
- Каким требованиям должна отвечать современная СУБД?
- Достоинства документных баз
- Объектно-ориентированные субд
- Какие реляционные БД популярны в веб-разработке
В чём преимущества
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
Представьте, что у вас есть экселька со списком клиентов. Это не база данных, это просто таблица. Чтобы прочитать или записать что-то в эту эксельку, вам нужно её открыть, сделать дело, сохранить.
Допустим, экселька с клиентами лежит на сетевом диске. Вы открыли её и ковыряетесь в данных, вносите изменения. Пока вы это делаете, ваш коллега тоже её открыл и тоже вносит изменения. Потом вы сохранились и закрыли эксельку. Экселька перезаписалась вашими данными. Но у вашего коллеги эти данные не отобразились, он-то открыл её раньше. Теперь, когда он сохранит свою эксельку, его данные перезапишутся поверх ваших, а ваши данные пропадут. Это полный ахтунг: вся ваша работа потеряна.
Или у вас в компании правило: экселька всегда на одной флешке, работаем только с неё. Сейчас флешка в вашем компьютере, вы с ней работаете. А вашему коллеге нужно с ней тоже поработать. Он говорит: «Дай». Вы ему «Отстань». Ну и слово за слово…
Но можно организовать своего рода СУБД. Один ответственный сотрудник назначается главным по эксельке. Она открыта на его компьютере, а вы ему говорите: «Петруха, добавь в клиента такого-то вот такие данные». «Петруха, а шо, когда дедлайн по поставке для этих ребят из Воронежа?», «Петруха, питерские отказались, поставь там отказ».
Петруха — ваша система управления базой данных. А экселька — это его база данных.
Понятно, что Петруха медленный и не всегда многозадачный, но хотя бы он избавляет от проблемы рассинхрона версий и потери данных.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.
Скорость важна ещё и потому, что СУБД обычно обслуживает сразу много потоков: одновременно ей могут пользоваться десятки и сотни тысяч человек, поэтому ей некогда копаться. В хорошо сделанных БД всё молниеносно.
Сложность. Базы данных нужны в числе прочего для хранения сложно структурированных данных. Мы привыкли думать, что база данных — это такая таблица, где есть строки и столбцы. Но база данных при правильной организации может намного больше:
- Связывать одну единицу данных с множеством других. Например, если один человек совершил много заказов со множеством товаров внутри каждого, база данных способна хранить и обрабатывать такие связи.
- База может хранить дерево данных — вроде того, о котором мы писали недавно. Попробуй в реальной жизни похранить дерево!
- В базах могут жить ссылки на другие фрагменты и отделы базы.
Базу можно представить как таблицу, но лишь в самом упрощённом виде. Для более сложных задач базу можно представить как очень сложное дерево, или огромный склад упорядоченных коробок, или даже как огромный завод по фасовке данных.
Встраиваемые
Встраиваемая система управления базой данных — это система, которая может быть связана с клиентским приложением таким образом, чтобы приложение и СУБД работали в едином адресном пространстве. Вместе со встроенной базой данных приложение может быть развернуто как единая программа, которая функциональна, эффективна и автономна. Благодаря связыванию приложения с базой данных, прикладная система выигрывает от снижения общей сложности и уменьшения затрат на администрирование. Во многих случаях встраиваемая система управления базой данных — самый подходящий вариант для систем с ограниченными ресурсами. Однако, встраиваемые СУБД зачастую подходят лишь для решения задач узкой спецификации.
Сетевая модель базы данных
Сетевая модель базы данных подразумевает, что у родительского элемента может быть несколько потомков, а у дочернего элемента — несколько предков. Записи в такой модели связаны списками с указателями. IDMS («Интегрированная система управления данными») от компании Computer Associates international Inc. — пример сетевой СУБД.
Иерархическая модель данных структурирует данные в виде древа записей, где есть один родительский элемент и несколько дочерних. Сетевая модель позволяет иметь несколько предков и потомков, формирующих решётчатую структуру.
Сетевая модель позволяет более естественно моделировать отношения между элементами. И хотя эта модель широко применялась на практике, она так и не стала доминантной по двум основным причинам. Во-первых, компания IBM решила не отказываться от иерархической модели в расширениях для своих продуктов, таких как IMS и DL/I. Во-вторых, через некоторое время её сменила реляционная модель, предлагавшая более высокоуровневый, декларативный интерфейс.
Популярность сетевой модели совпала с популярностью иерархической модели. Некоторые данные намного естественнее моделировать с несколькими предками для одного дочернего элемента. Сетевая модель как раз и позволяла моделировать отношения «многие ко многим». Её стандарты были формально определены в 1971 году на конференции по языкам систем обработки данных (CODASYL).
Основной элемент сетевой модели данных — набор, который состоит из типа «запись-владелец», имени набора и типа «запись-член». Запись подчинённого уровня («запись-член») может выполнять свою роль в нескольких наборах. Соответственно, поддерживается концепция нескольких родительских элементов.
Запись старшего уровня («запись-владелец») также может быть «членом» или «владельцем» в других наборах. Модель данных — это простая сеть, связи, типы пересечения записей (в IDMS они называются junction records, то есть «перекрёстные записи). А также наборы, которые могут их объединять. Таким образом, полная сеть представлена несколькими парными наборами.
В каждом из них один тип записи является «владельцем» (от него отходит «стрелка» связи), и один или более типов записи являются «членами» (на них указывает «стрелка»). Обычно в наборе существует отношение 1:М, но разрешено и отношение 1:1. Сетевая модель данных CODASYL основана на математической теории множеств.
Известные сетевые базы данных:
- TurboIMAGE;
- IDMS;
- Встроенная RDM;
- Серверная RDM.
Классификация Structured Query Language
SQL запросы можно разделить на следующие виды:
DDL
Язык определения данных – DDL (аббревиатура Data Definition Language). Основная задача – формирование БД и представление ее структуры. Они диктуют правила (вид) размещения данных в БД.
К DDL относятся SQL Queries:
- ALTER – применяется для добавления, удаления, изменения столбцов в ранее созданной таблице (ALTER TABLE);
- COLLATE – используется, чтобы определить, по каким параметрам будет сортироваться БД, столбцы либо операции приведения условий сортировки, если используется выражение строки символов;
- CREATE – позволяет создать новую БД;
- DROP – позволяет удалять любые данные (в том числе и таблицы) из БД. Добавляется приставкой к нужному элементу (DROP TABLE – удалить таблицу);
- DISABLE TRIGGER – выполняет функции отключения триггеров;
- ENABLE TRIGGER – выполняет включение триггеров DML, DDL или logon;
- RENAME – используется для переименования таблицы, которая создана пользователем;
- UPDATE STATISTICS – выполняет функции обновления статистики оптимизации запросов как для таблиц, так и для индексированных представлений;
- TRUNCATE – удаляет все значения из таблицы, но ее саму оставляет.
DML
Язык манипулирования данными – DML (сокращенное от Data Manipulation Language). К нему относятся команды, при использовании которых осуществляются определенные манипуляции с данными.
Основная часть MS SQL запросов относится именно к DML. В их число входят:
- BULK INSERT – импортирует файл с данными в таблицу либо представляет БД в том формате, который указал пользователь;
- SELECT – выводит нужные данные из определенной таблицы;
- DELETE – выполняет удаление указанной строки (с помощью оператора WHERE) из определенной таблицы в БД,
- UPDATE – позволяет вносить правки или добавлять новую информацию в сделанные ранее записи. Включает: таблицу с полем, в котором необходимо внести изменения, запись нового значения, для обозначения места в выбранной таблице применяется WHERE;
- INSERT – в имеющуюся БД добавляет новые записи;
- UPDATETEXT – выполняет обновление (изменение) существующих полей типа text, ntext или image;
- MERGE – в целевой таблице выполняет операции вставок, обновлений либо удалений, основанные на результатах соединения с данными исходной;
- WRITETEXT – выполняет обновление существующих столбцов, имеющих тип text, ntext или image, в режиме онлайн, с минимальным использованием журнала. Данная инструкция перезаписывает в столбцах, для которых используется, любые данные. Но ее нельзя применять в представлениях для столбцов вышеуказанных типов;
- READTEXT – производит считывание значений text, ntext или image из соответствующих столбцов. Процесс запускается с указанных позиций и длится для обозначенного числа байтов.
Без них не обойтись, когда необходимо:
- внести изменения в ранее занесенные данные;
- получить данные из сформированной ранее БД;
- сохранить, обновить, удалить данные из БД.
DCL
Языком управления данными является DCL (расшифровывается – Data Control Language). В нем объединены запросы вместе с командами, которые касаются прав, разрешений и прочих настроек систем управления БД.
К их числу относятся:
- GRANT – применяется для распределения пользователям привилегий;
- REVOKE – выполняет функции отмены привилегий,
- DENY – применяется для запрещения разрешений участникам. Наделен приоритетом над иными разрешениями, однако не может использоваться к владельцам либо членам с правами sysadmin.
TCL
Языком управления транзакциями является TCL (аббревиатура от Transaction Control Language). TCL-конструкции используются для управления изменениями, происходящими благодаря применению DML-команд. Они дают возможность объединять в наборы транзакций запросы DML.
К ним относятся:
- BEGIN – позволяет выполнять инструкции T-SQL;
- COMMIT – выполняет фиксацию транзакции;
- ROLLBACK – выполняет откат транзакции.
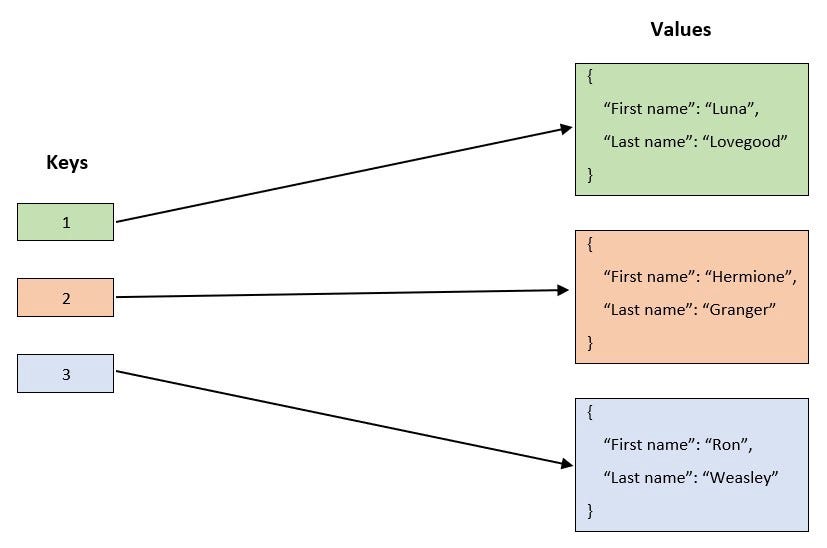
Ключ-значение
В этих БД запросы только на основе ключа — вы запрашиваете ключ и получаете его значение.
Такие БД не поддерживают запросы между различными значениями записей, вроде такого: выбрать все записи, где город — Нью-Йорк.Полезное свойство этих БД — поле времени жизни (Time-to-Live, TTL), в котором можно задать отдельно для каждой записи и состояния, когда их нужно удалить из БД.
Достоинства
Это очень быстрые БД. Во-первых, потому что используют уникальные ключи, во-вторых, потому что большинство БД типа ключ-значение хранят данные в оперативной памяти, что обеспечивает быстрый доступ к данным.
Недостатки
Необходимо определять уникальные ключи, хорошие идентификаторы, основанные на заранее известных вам данных. Зачастую они дороже, чем другие типы баз данных, так как используют оперативную память.
Использование
В основном используются для кэширования, потому что быстрые и не требуют сложных запросов. Поле времени жизни для кэширования также очень полезно. Такие БД могут использоваться для любых данных, которые требуют быстрых запросов и соответствуют формату ключ-значение. Примеры таких баз:
- Redis
- Memcached
Создание базы данных с помощью шаблона
В Access есть разнообразные шаблоны, которые можно использовать как есть или в качестве отправной точки. Шаблон — это готовая к использованию база данных, содержащая все таблицы, запросы, формы, макросы и отчеты, необходимые для выполнения определенной задачи. Например, существуют шаблоны, которые можно использовать для отслеживания вопросов, управления контактами или учета расходов. Некоторые шаблоны содержат примеры записей, демонстрирующие их использование.
Если один из этих шаблонов вам подходит, с его помощью обычно проще и быстрее всего создать необходимую базу данных. Однако если необходимо импортировать в Access данные из другой программы, возможно, будет проще создать базу данных без использования шаблона. Так как в шаблонах уже определена структура данных, на изменение существующих данных в соответствии с этой структурой может потребоваться много времени.
-
Если база данных открыта, нажмите на вкладке Файл кнопку Закрыть. В представлении Backstage откроется вкладка Создать.
-
На вкладке Создать доступно несколько наборов шаблонов. Некоторые из них встроены в Access, а другие шаблоны можно скачать с сайта Office.com. Дополнительные сведения см. в следующем разделе.
-
Выберите шаблон, который вы хотите использовать.
-
Access предложит имя файла для базы данных в поле «Имя файла». При этом имя файла можно изменить. Чтобы сохранить базу данных в другой папке, отличной от папки, которая отображается под полем «Имя файла», нажмите кнопку , перейдите к папке, в которой ее нужно сохранить, и нажмите кнопку «ОК». При желании вы можете создать базу данных и связать ее с сайтом SharePoint.
-
Нажмите кнопку Создать.
Access создаст базу данных на основе выбранного шаблона, а затем откроет ее. Для многих шаблонов при этом отображается форма, в которую можно начать вводить данные. Если шаблон содержит примеры данных, вы можете удалить каждую из этих записей, щелкнув область маркировки (затененное поле или полосу слева от записи) и выполнив действия, указанные ниже.
На вкладке Главная в группе Записи нажмите кнопку Удалить.
-
Щелкните первую пустую ячейку в форме и приступайте к вводу данных. Для открытия других необходимых форм или отчетов используйте область навигации. Некоторые шаблоны содержат форму навигации, которая позволяет перемещаться между разными объектами базы данных.
Дополнительные сведения о работе с шаблонами см. в статье Создание базы данных Access на компьютере с помощью шаблона.
NoSQL как альтернатива традиционным БД
Мир меняется. В ходе цифровой трансформации перед бизнесом встают новые задачи. Компании решают их с помощью новых баз данных. Во-первых, чтобы не перегружать имеющиеся, во-вторых, не для всех современных задач подходят классические реляционные СУБД.
И вот, в начале 2000-х появились нереляционные базы. Помимо решения новых задач, их разработчики сделали упор на исправление главных недостатков реляционных баз — проблем с гибкостью, низкой производительностью и масштабируемостью.
В NoSQL нет таких понятий, как строки, столбцы, таблицы и их соединения. Данные в нереляционных базах хранятся как объекты с произвольными атрибутами: это могут быть пары «ключ-значение», документы в формате JSON, графы и так далее.
Какую СУБД мы изучаем
В основу курса положена работа с СУБД от компании Microsoft – SQL Server. Это реляционная распределенная клиент-серверная СУБД. Все запросы в последующих главах написаны на диалекте языка SQL – Transact SQL.
Эта СУБД выбрана из -за ее популярности на системах на базе операционных систем Windows.
Следующий раздел посвящен тому. Что нужно для работы с этой СУБД. Откуда это взять. Как установить, настроить и приступить к работе.
Установка и настройка MS SQL Server и MS SQL Server Management Studio
Этот раздел посвящен вопросам установки, настройки и запуска СУБД MS SQL Server – для реализации сервера и установки, и настройки MS Server Management Studio – для реализации запросов на языке Transact SQL серверу.
Установка обоих компонентов будет производится на один компьютер. И несмотря на то, что SQL Server распределенная СУБД, выполнение запросов и их написание будет производится на одном и том же компьютере.
Каким требованиям должна отвечать современная СУБД?
Информационное хранилище должно постоянно пополняться новыми данными в соответствии с ритмом жизни компании, это же касается и формирование новых категорий учета.
При этом вносить информацию должен иметь возможность любой новый сотрудник. То же касается и обслуживания данной инфраструктуры со стороны системного администратора, формирования новых выборок данных со стороны аналитиков с разным уровнем допуска к информации и с разными профилями анализируемых данных.
Необходимо отметить, что количество информации увеличивается не только в объеме, но и качественно. В результате появляется необходимость одновременной работы с ней нескольких экспертов. Кроме того, появляется возможность привлечения специализированных экспертов для выполнения сложных процедур анализа данных (Data mining Интеллектуальный анализ данных). Сегодня не только для формирования будущей стратегии, но и для выполнения повседневных задач все большее значение имеет прогнозная аналитика, которая для формирования верного вектора развития использует объективные, а не субъективные данные.
Помимо этого единая база данных упрощает формирования отчетности как отдельным подразделениям компании, так и всей компании в целом для подачи документов в государственные инстанции или их предоставления для ознакомления внешним экспертным комиссиям. Единая база позволяет в автоматическом режиме обновлять документацию, относящуюся к нормативно-справочной информации (НСИ). Дополнительно общая база данных позволяет оперировать информацией в своеобразной унифицированной форме, делая процедуры анализа информации более единообразными в рамках компании.
Еще одним плюсом от единого подхода к хранению информации является гораздо более простая процедура резервирования, снижение времени простоя после сбоя, обеспечение безопасности данных в плане распределения прав доступа, более прозрачная процедура миграции на новые версии программного и аппаратного обеспечения.
Достоинства документных баз
- Позволяют хранить объекты с разной структурой.
- Могут отображать почти все структуры данных, включая объекты на основе ООП, списки и словари, используя старый добрый JSON.
- Несмотря на то, что NoSQL не схематичны по своей природе, они часто поддерживают проверку схемы. Это значит, что вы можете сделать коллекцию со схемой. Эта схема не будет простой, как таблица: это будет JSON схема со специфическими полями.
- Запросы к NoSQL очень быстрые — каждая запись независима и, следовательно, время запроса не зависит от размера базы. По той же причине эта БД поддерживает параллельность.
- В NoSQL масштабирование БД осуществляется добавлением компьютеров и распределением данных между ними, этот метод называется горизонтальное масштабирование. Оно позволяет автоматически добавлять ресурсы к БД, когда нам нужно, не провоцируя простои.
Объектно-ориентированные субд
Появление объектно-ориентированных СУБД вызвано потребностями программистов на ОО-языках, которым были необходимы средства для хранения объектов, не помещавшихся в оперативной памяти компьютера. Также важна была задача сохранения состояния объектов между повторными запусками прикладной программы. Поэтому, большинство ООСУБД представляют собой библиотеку, процедуры управления данными которой включаются в прикладную программу. Примеры реализации ООСУБД как выделеного сервера базы данных крайне редки.
Сразу же необходимо заметить, что общепринятого определения «объектно-ориентированной модели данных» не существует. Сейчас можно говорить лишь о неком «объектном» подходе к логическому представлению данных и о различных объектно-ориентированных способах его реализации.
Структура
Структура объектной модели описываются с помощью трех ключевых понятий:
инкапсуляция — каждый объект обладает некоторым внутренним состоянием (хранит внутри себя запись данных), а также набором методов — процедур, с помощью которых (и только таким образом) можно получить доступ к данным, определяющим внутреннее состояние объекта, или изменить их. Таким образом, объекты можно рассматривать как самостоятельные сущности, отделенные от внешнего мира;
наследование — подразумевает возможность создавать из классов объектов новые классы объекты, которые наследуют структуру и методы своих предков, добавляя к ним черты, отражающие их собственную индивидуальность. Наследование может быть простым (один предок) и множественным (несколько предков);
полиморфизм — различные объекты могут по разному реагировать на одинаковые внешние события в зависимости от того, как реализованы их методы.
Целостность данных
Для поддержания целостности объектно-ориентированный подход предлагает использовать следующие средства:
автоматическое поддержание отношений наследования возможность объявить некоторые поля данных и методы объекта как «скрытые», не видимые для других объектов; такие поля и методы используются только методами самого объекта создание процедур контроля целостности внутри объекта
Средства манипулирования данными
К сожалению, в объектно-ориентированном программировании отсутствуют общие средства манипулирования данными, такие как реляционная алгебра или реляционное счисление. Работа с данными ведется с помощью одного из объектно-ориентированных языков программирования общего назначения, обычно это SmallTalk, C++ или Java.
В объектно-ориентированных базах данных, в отличие от реляционных, хранятся не записи, а объекты. ОО-подход представляет более совершенные средства для отображения реального мира, чем реляционная модель, естественное представление данных. В реляционной модели все отношения принадлежат одному уровню, именно это осложняет преобразование иерархических связей модели «сущность-связь» в реляционную модель. ОО-модель можно рассматривать послойно, на разных уровнях абстракции. Имеется возможность определения новых типов данных и операций с ними.
В то же время, ОО-модели присущ и ряд недостатков:
осутствуют мощные непроцедурные средства извлечения объектов из базы. Все запросы приходится писать на процедурных языках, проблема их оптимизации возлагается на программиста;
вместо чисто декларативных ограничений целостности (типа явного объявления первичных и внешних ключей реляционных таблиц с помощью ключевых слов PRIMARY KEY и REFERENCES) или полудекларативных триггеров для обеспечения внутренней целостности приходится писать процедурный код.
Очевидно, что оба эти недостатка связаны с отсутствием развитых средств манипулирования данными. Эта задача решается двумя способами — расширение ОО-языков в сторону управления данными (стандарт ODMG), либо добавление объектных свойств в реляционные СУБД (SQL-3, а также так называемые объектно-реляционных СУБД).
Какие реляционные БД популярны в веб-разработке
MySQL
Это открытая СУБД, купленная Oracle в придачу к Sun Microsystems. С ней работают более половины (55,6%) всех разработчиков (по опроса, который в 2020 году провёл сайт StackOverflow.com среди 65 тысяч респондентов).
Главные её преимущества — бесплатность и высокая скорость работы с данными. MySQL создавалась для обработки огромных массивов информации в промышленных масштабах, но благодаря доступности и быстродействию оккупировала Всемирную паутину, заслужив звание «СУБД всея интернета». И сегодня MySQL всё ещё самая удобная СУБД для работы с интернет-страницами и веб-приложениями.
MySQL пользуется мощной поддержкой у создателей языков программирования: практически во всех популярных языках есть интерфейс для работы с ней.
SQLite
Эта СУБД использует большую часть стандартного языка SQL.
Главное преимущество SQlight — встраиваемость. Это объясняется тем, что SQlight не приложение типа «клиент-сервер» (в отличие от других реляционных СУБД), а библиотека, которую подключают непосредственно к программе.
И она тоже весьма популярна: достаточно сказать, что SQLite есть в каждом смартфоне. Например, в смартфонах на Android там хранятся контакты и медиа, а в iOS её используют многие приложения.
PostgreSQL
Её можно назвать самой продвинутой. Это не просто реляционная, а объектно-реляционная свободная СУБД.
PostgreSQL поддерживает не только типы данных, которые есть в других реляционных СУБД. Помимо числовых, текстовых, булевых и других стандартных типов, в ней можно хранить и обрабатывать геометрические и денежные данные, сетевые адреса, JSON, XML, массивы, а также создавать собственные типы данных.


