Базы данных
Содержание:
- Пример SQL-сервера
- В чём преимущества
- Что такое нормализация
- Виды нереляционных баз данных
- Пример PostgreSQL
- Ключи
- Определение сущностей
- Другие модели баз данных (ООСУБД)
- Динамичные базы данных
- Рейтинг
- Что такое схемы базы данных?
- Создание связей между сущностями
- Логическое проектирование и оптимизация
- Создание базы данных с помощью шаблона
Пример SQL-сервера
База данных SQL содержит такие объекты, как представления, таблицы, функции, индексы и представления. Нет никаких ограничений на количество объектов, которые мы можем использовать. Схемы SQL определяются на логическом уровне, и пользователь, владеющий этой схемой, называется владельцем схемы.
SQL используется для доступа, обновления и управления данными. MySQL — это СУБД для хранения и организации.
Мы можем использовать SQL Server CREATE SCHEMAдля создания новой схемы в базе данных. В MySQL схема является синонимом базы данных. Вы можете заменить ключевое слово SCHEMAдля DATABASEсинтаксиса MySQL SQL.
Некоторые другие продукты баз данных различаются. Например, в продукте Oracle Database схема представляет только часть базы данных: таблицы и другие объекты принадлежат одному пользователю.
Первичные ключи и внешние ключи оказываются здесь полезными, поскольку они представляют отношения от одной таблицы к другой.
В чём преимущества
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
Представьте, что у вас есть экселька со списком клиентов. Это не база данных, это просто таблица. Чтобы прочитать или записать что-то в эту эксельку, вам нужно её открыть, сделать дело, сохранить.
Допустим, экселька с клиентами лежит на сетевом диске. Вы открыли её и ковыряетесь в данных, вносите изменения. Пока вы это делаете, ваш коллега тоже её открыл и тоже вносит изменения. Потом вы сохранились и закрыли эксельку. Экселька перезаписалась вашими данными. Но у вашего коллеги эти данные не отобразились, он-то открыл её раньше. Теперь, когда он сохранит свою эксельку, его данные перезапишутся поверх ваших, а ваши данные пропадут. Это полный ахтунг: вся ваша работа потеряна.
Или у вас в компании правило: экселька всегда на одной флешке, работаем только с неё. Сейчас флешка в вашем компьютере, вы с ней работаете. А вашему коллеге нужно с ней тоже поработать. Он говорит: «Дай». Вы ему «Отстань». Ну и слово за слово…
Но можно организовать своего рода СУБД. Один ответственный сотрудник назначается главным по эксельке. Она открыта на его компьютере, а вы ему говорите: «Петруха, добавь в клиента такого-то вот такие данные». «Петруха, а шо, когда дедлайн по поставке для этих ребят из Воронежа?», «Петруха, питерские отказались, поставь там отказ».
Петруха — ваша система управления базой данных. А экселька — это его база данных.
Понятно, что Петруха медленный и не всегда многозадачный, но хотя бы он избавляет от проблемы рассинхрона версий и потери данных.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.
Скорость важна ещё и потому, что СУБД обычно обслуживает сразу много потоков: одновременно ей могут пользоваться десятки и сотни тысяч человек, поэтому ей некогда копаться. В хорошо сделанных БД всё молниеносно.
Сложность. Базы данных нужны в числе прочего для хранения сложно структурированных данных. Мы привыкли думать, что база данных — это такая таблица, где есть строки и столбцы. Но база данных при правильной организации может намного больше:
- Связывать одну единицу данных с множеством других. Например, если один человек совершил много заказов со множеством товаров внутри каждого, база данных способна хранить и обрабатывать такие связи.
- База может хранить дерево данных — вроде того, о котором мы писали недавно. Попробуй в реальной жизни похранить дерево!
- В базах могут жить ссылки на другие фрагменты и отделы базы.
Базу можно представить как таблицу, но лишь в самом упрощённом виде. Для более сложных задач базу можно представить как очень сложное дерево, или огромный склад упорядоченных коробок, или даже как огромный завод по фасовке данных.
Что такое нормализация
Чтобы уменьшить размер реляционной базы (не хранить избыточные данные) и избежать противоречивости (аномалий) при работе с ними, отношения в базе нормализуют. Проще говоря — разбивают их на взаимосвязанные таблицы. Это называется декомпозицией.
Избыточность данных — это когда одни и те же данные хранятся в базе сразу в нескольких местах.
Проверим наш пример на избыточность
Каждая строка таблицы Messages содержит имя клиента и никнейм оператора, а также их телефоны. Причём в 1-й и 3-й строках мы видим звонки от одного и того же клиента, а в 1-й и во 2-й — ответы одного и того же менеджера. То есть в 1-й и 3-й строках дублируются имя и телефон клиента — Васи, а в 1-й и 2-й — никнейм менеджера «Оператор1».
Чтобы избавиться от дублирования информации, выделим сущности Клиент и Оператор. И вынесем специфичные для каждой атрибуты в отдельные таблицы.
В первой (Clients) будут храниться имена и телефоны клиентов, а во второй (Operators) — операторов. Кроме того, каждой записи в этих таблицах мы присвоим атрибут id — так называемый первичный ключ (его значение уникально, то есть не может повторяться в пределах таблицы). С его помощью мы установим связь с записями таблицы Messages.
Для этого к каждой записи в Messages (напомним, она всё ещё представляет сущность «звонок») добавим два новых атрибута (внешних ключа): id_client и id_oper. Они будут ссылаться на первичные ключи из таблиц Clients и Operators соответственно. Столбцы с именами и телефонами из таблицы Messages уберём.
И вот что получим:
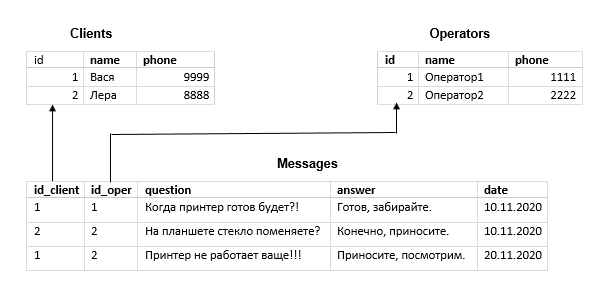
В такой базе, чтобы поменять телефон клиента сразу для всех записей, достаточно изменить всего одно поле в таблице Clients.
Всего существует шесть форм нормализации реляционных баз данных — в порядке уменьшения избыточности отношений. Все они описаны формальными правилами. Наше отношение мы привели ко второй нормальной форме.
Виды нереляционных баз данных
Базы NoSQL делятся на четыре основные категории (в зависимости от решаемых с их помощью задач).
Ключ-значение
Такую базу можно представить как огромную таблицу. В каждой её ячейке хранятся данные произвольного типа, а каждому значению присвоен уникальный ключ, по которому это значение можно найти.
Такая СУБД не поддерживает связи между объектами, выполняет лишь операции поиска значений по ключу, добавления и удаления записи.
Например:
| key | value |
|---|---|
| user1 | {Кузнецов В., отдел маркетинга} |
| user2 | {name:Лена, position:секретарь} |
| user3 | {ООО «Вектор»} |
| user4 | {Трофимова Таня, отд.2, дизайнер} |
| user5 | {Галина Николаевна, гл. бух.} |
| user6 | {65,84,236} |
Базы «ключ-значение» часто используют для кэширования данных и организации очередей.
Их достоинства — быстрый поиск и простое масштабирование.
Их недостаток — нельзя производить операции со значениями. Например — сортировать их или анализировать.
Одна из самых популярных — Redis. Её используют Uber, Slack, Stack Overflow, сайты гостиниц и туристические, социальная сеть Twitter.
Документоориентированные СУБД
В таких данные хранятся в виде иерархических структур (документов) с произвольным набором полей и их значений. Документы объединяются в коллекции.
Если провести аналогию с реляционными СУБД, то коллекциям соответствуют таблицы, а документам — строки в них.
Например, фрагмент документа с информацией о фильмах:
Документоориентированные базы используют в системах управления содержимым (CMS) — для хранения каталогов и пользовательских профилей.
Одна из самых популярных — MongoDB (там можно создавать процедуры на JavaScript).
Колоночные
Эти базы отличаются от реляционных лишь способом хранения данных на накопителе.
Если реляционная база создаёт для каждой таблицы по файлу, то в колоночной отдельный файл создаётся для каждого столбца таблицы.
Например, если реляционная таблица выглядит так:
| name | color | property |
|---|---|---|
| волк | серый | зубастый |
| коза | белая | рогатая |
| капуста | зелёная |
То те же записи колоночной базы будут выглядеть примерно так:
| name | волк | коза | капуста |
| color | серый | белая | зелёная |
| property | зубастый | рогатая |
Что это даёт? Представьте, что вам нужны только названия объектов, а их свойства вас не интересуют.
При выполнении запроса в реляционной таблице просматривается каждая запись и из неё выбираются нужные данные. В колоночной базе с диска будет считана только одна колонка с названиями. Это сокращает время выполнения запроса, причём намного.
Колоночные базы применяются в различных каталогах и архивах данных, работа с которыми основана на подобных выборках.
Одна из самых популярных СУБД такого типа — Apache Cassandra.
Графовые
В некоторых предметных областях данные удобно представлять в виде графов. Для их хранения лучше всего подходят графовые базы.
Вершины (или узлы графа) — это объекты (сущности), а рёбра графа — взаимосвязи между ними.
Пример PostgreSQL
PostgreSQL — это бесплатная система управления реляционными базами данных с открытым исходным кодом, которая отличается высокой расширяемостью и соответствует требованиям SQL. В PostgreSQL схема базы данных — это пространство имен с именованными объектами базы данных.
Сюда входят таблицы, представления, индексы, типы данных, функции и операторы. В этой системе схемы являются синонимами каталогов, но они не могут быть вложены в иерархию.
Примечание. В программировании пространство имен — это набор знаков (называемых именами), которые мы используем для идентификации объектов. Пространство имен гарантирует, что всем объектам присваиваются уникальные имена, чтобы их было легко идентифицировать.
Итак, хотя база данных Postgres может содержать несколько схем, уровень будет только один. Посмотрим на визуальное представление:
В PostgreSQL кластер баз данных содержит одну или несколько баз данных. Пользователи совместно используются в кластере, но данные не передаются. Вы можете использовать одно и то же имя объекта в нескольких схемах.
Мы используем это выражение CREATE SCHEMAдля начала
Обратите внимание, что PostgreSQL автоматически создаст общедоступную схему. Здесь будет размещаться каждый новый объект
Чтобы создать объекты в схеме базы данных, мы пишем полное имя, которое включает имя схемы и имя таблицы:
В следующем примере из документации Postgres вызывается CREATE SCHEMAновая схема scm, вызывается таблица deliveriesи вызывается представление delivery_due_list.
Ключи
Ключом (key) называется набор атрибутов, однозначно определяющий запись. Ключи делятся на два класса: простые и составные.
Простой ключ состоит только из одного атрибута. Например, в базе «Паспорта граждан страны» номер паспорта будет простым ключом: ведь не бывает двух паспортов с одинаковым номером.
Составной ключ состоит из нескольких атрибутов. В той же базе «Паспорта граждан страны» может быть составной ключ со следующими атрибутами:
фамилия, имя, отчество, дата рождения. Это — как пример, т. к. этот составной ключ, теоретически, не обеспечивает гарантированной уникальности записи.
Также существует несколько типов ключей, о которых рассказано далее.
Возможный ключ
Возможный ключ представляет собой любой набор атрибутов, однозначно идентифицирующих запись в таблице. Возможный ключ может быть простым или составным.
Каждая сущность должна иметь, по крайней мере, один возможный ключ, хотя таких ключей может быть и несколько. Ни один из атрибутов первичного ключа не может принимать неопределенное (NULL) значение.
Возможный ключ называется также суррогатным.
Первичные ключи
Первичным ключом называется совокупность атрибутов, однозначно идентифицирующих запись в таблице (сущности). Один из возможных ключей становится первичным ключом. На диаграммах первичные ключи часто изображаются выше основного списка атрибутов или выделяются специальными символами. Сущность на рисунке имеет как ключевые, так и обычные атрибуты.
Альтернативные ключи
Любой возможный ключ, не являющийся первичным, называется альтернативным ключом. Сущность может иметь несколько альтернативных ключей.
Внешние ключи
Внешним ключом называется совокупность атрибутов, ссылающихся на первичный или альтернативный ключ другой сущности. Если внешний ключ не связан с первичной сущностью, то он может содержать только неопределенные значения. Если при этом ключ является составным, то все атрибуты внешнего ключа должны быть неопределенными.
На диаграммах атрибуты, объединяемые во внешние ключи, обозначаются специальными символами. На рисунке изображены две связанные сущности (Дома и их Хозяева) и образованные ими внешние ключи (ведь один человек может владеть больше, чем одним домом).
Ключи являются логическими конструкциями, а не физическими объектами. В реляционных базах данных предусмотрены механизмы, обеспечивающие сохранение ключей.
Определение сущностей
На этом этапе вам необходимо определить сущности, из которых будет состоять база данных.
Сущность — это объект в базе данных, в котором хранятся данные. Сущность может представлять собой нечто вещественное (дом, человек, предмет, место) или абстрактное (банковская операция, отдел компании, маршрут автобуса). В физической модели сущность называется таблицей.
Сущности состоят из атрибутов (столбцов таблицы) и записей (строк в таблице).
Обычно базы данных состоят из нескольких основных сущностей, связанных с большим количеством подчиненных сущностей. Основные сущности называются независимыми: они не зависят ни от какой-либо другой сущности. Подчиненные сущности называются зависимыми: для того чтобы существовала одна из них, должна существовать связанная с ней основная таблица.
На диаграммах сущности обычно представляются в виде прямоугольников. Имя сущности указывается внутри прямоугольника:
Любая таблица имеет следующие характеристики:
- в ней нет одинаковых строк;
- все столбцы (атрибуты) в таблице должны иметь разные имена;
- элементы в пределах одной колонки имеют одинаковый тип (строка, число, дата);
- порядок следования строк в таблице может быть произвольным.
На этом этапе вам необходимо выявить все категории информации (сущности), которые будут храниться в базе данных.
Другие модели баз данных (ООСУБД)
В последнее время на рынке СУБД появились продукты, представленные объектными и объектно-ориентированной моделью данных, такие как Gem Stone и Versant ОСУБД. Также производятся исследования в области многомерных и логических моделей данных.
Особенности объектно-ориентированных систем управления базами данных (ООСУБД):
- При интеграции возможностей базы данных с объектно-ориентированным языком программирования получается объектно-ориентированная СУБД.
- ООСУБД представляет данные как объекты одного или нескольких языков программирования.
- Такая система должна отвечать двум критериям: являться СУБД и должна быть объектно-ориентированной. То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
- ООСУБД дают возможность моделирования данных в виде объектов.
А также поддержку классов объектов и наследование свойств и методов классов подклассами и их объектами.
На данный момент не существует общепринятого стандарта ООСУБД. Считается, что подобные модели данных находится на ранней стадии развития.
Примеры ООСУБД:
- D Gemstone;
- IRS;
- ORION;
- ONTOS.
Применение ООСУБД:
- В конструкторских и рассредоточенных базах данных, телекоммуникации, а также в таких научных областях, как физика высоких энергий и молекулярная биология.
- Используются в специализированных областях финансового сектора.
- Во встроенных системах, пакетном программном обеспечении и системах реального времени, чтобы у пользователей была возможность создавать объекты по своему выбору.
Пожалуйста, оставляйте ваши отзывы по текущей теме статьи. За комментарии, отклики, дизлайки, лайки, подписки низкий вам поклон!
Пожалуйста, оставьте ваши комментарии по текущей теме материала. Мы очень благодарим вас за ваши комментарии, лайки, отклики, подписки, дизлайки!
МКМихаил Кузнецовавтор-переводчик статьи «Types of Database Models | Database Management System»
Динамичные базы данных
Проблема безопасности привела к проблеме ограничения доступа. Много имен и паролей, много сотрудников и рост числа потерь информации, доступа, персональных данных. Работа ради работы — не самое лучшее решение.
Компания стремится к выполнению своей миссии, а не к тому, чтобы ее служба безопасности поддерживала нормальную работу ее забывчивых сотрудников
Человеческий фактор здесь важно учитывать
Адекватный и востребованный ответ динамичные базы данных, которые моментально захватывают всю инфраструктуру компании и ее сотрудников, автоматом предоставляют каждому, согласно его полномочиям, с любого устройства.
Службы технической поддержки, абонентский сервис, колл-центры — надлежащий ответ разнообразные системы тикетов соединяют в единую базу данных, но не только голосовые и электронные сообщения от клиентов, а также события, вытекающие из работы компании.
Характерная черта современной обработки информации: специалисты научились работать в динамике и использовать статичный потенциал громоздких баз данных в условиях изменчивой потребности.
Рейтинг
Итак, рейтинг 10 наиболее популярных баз данных, согласно ресурсу DB-Engines, выглядит следующим образом:
- Oracle;
- MySQL;
- Microsoft SQL Server;
- PostgreSQL;
- MongoDB;
- DB2;
- Cassandra;
- Microsoft Access;
- Redis;
- SQLite.
Итого, 7 из 10 представителей рейтинга – реляционные базы данных, а также по одному экземпляру документоориентированной БД (MongoDB), с распределёнными значениями (Cassandra) и использующей подход «ключ-значение» (Redis). Таким образом, на сегодняшний день доминирование реляционных баз данных неоспоримо, но что будет завтра?
Для ответа на этот вопрос обратимся на этом же ресурсе к разделу тренды. Если брать отметки времени в более чем в 2 или 4 года, то наибольший рост демонстрирует подход с использованием теории графов. В то же время за последний год максимальный рост популярности продемонстрировали БД на основе временных данных. Это относительно новый подход, он также считается NoSQL, преимущество сводится к созданию структуры на основе дат или временных диапазонов. На данный момент наиболее популярным представителем Time Series БД является InfluxDB.
А какие базы данных используете вы? И какая на ваш взгляд наиболее перспективная NoSQL БД?
Что такое схемы базы данных?
Когда дело доходит до выбора базы данных, одна из вещей, о которой вы должны подумать, — это форма ваших данных, модель, которой они будут следовать, и то, как сформированные отношения помогут нам при разработке схемы.
Схема базы данных — это план или архитектура того, как будут выглядеть наши данные. Он не содержит самих данных, а вместо этого описывает форму данных и то, как они могут быть связаны с другими таблицами или моделями. Запись в нашей базе данных будет экземпляром схемы базы данных. Он будет содержать все свойства, описанные в схеме.
Думайте о схеме базы данных как о типе структуры данных. Он представляет собой структуру и структуру содержимого данных организации.
Схема базы данных будет включать:
- Все важные или важные данные
- Единое форматирование для всех записей данных
- Уникальные ключи для всех записей и объектов базы данных
- Каждый столбец в таблице имеет имя и тип данных.
Размер и сложность схемы вашей базы данных зависит от размера вашего проекта. Визуальный стиль схемы базы данных позволяет программистам правильно структурировать базу данных и ее взаимосвязи, прежде чем переходить к коду. Процесс планирования дизайна базы данных называется моделированием данных.
Схемы важны для проектирования систем управления базами данных (СУБД) или систем управления реляционными базами данных (СУБД). СУБД — это программное обеспечение, которое хранит и извлекает пользовательские данные безопасным способом в соответствии с концепцией ACID.
Во многих компаниях ответственность за проектирование базы данных и СУБД обычно ложится на роль администратора базы данных (DBA). Администраторы баз данных несут ответственность за обеспечение беспрепятственного доступа к информации аналитикам данных и пользователям баз данных. Они работают вместе с командами менеджеров для планирования и безопасного управления базой данных организации.
Создание связей между сущностями
Теперь, когда данные преобразованы в таблицы, нужно проанализировать связи между ними. Сложность базы данных определяется количеством элементов, взаимодействующих между двумя связанными таблицами. Определение сложности помогает убедиться, что вы разделили данные на таблицы наиболее эффективно.
Каждый объект может быть взаимосвязан с другим с помощью одного из трех типов связи:
Связь «один-к одному»
Когда существует только один экземпляр объекта A для каждого экземпляра объекта B, говорят, что между ними существует связь «один-к одному» (часто обозначается 1:1). Можно указать этот тип связи в ER-диаграмме линией с тире на каждом конце:
Создание базы данных mysql от А до Я
Если при проектировании и разработке баз данных у вас нет оснований разделять эти данные, связь 1:1 обычно указывает на то, что в лучше объединить эти таблицы в одну.
Но при определенных обстоятельствах целесообразнее создавать таблицы со связями 1:1. Если есть поле с необязательными данными, например «описание», которое не заполнено для многих записей, можно переместить все описания в отдельную таблицу, исключая пустые поля и улучшая производительность базы данных.
Чтобы гарантировать, что данные соотносятся правильно, в нужно будет включить, по крайней мере, один идентичный столбец в каждой таблице. Скорее всего, это будет первичный ключ.
Связь «один-ко-многим»
Эта связи возникают, когда запись в одной таблице связана с несколькими записями в другой. Например, один клиент мог разместить много заказов, или у читателя может быть сразу несколько книг, взятых в библиотеке. Связи «один- ко-многим» (1:M) обозначаются так называемой «меткой ноги вороны», как в этом примере:
Чтобы реализовать связь 1:M, добавьте первичный ключ из «одной» таблицы в качестве атрибута в другую таблицу. Если первичный ключ таким образом указан в другой таблице, он называется внешним ключом. Таблица со стороны связи «1» представляет собой родительскую таблицу для дочерней таблицы на другой стороне.
Связь «многие-ко-многим»
Когда несколько объектов таблицы могут быть связаны с несколькими объектами другой. Говорят, что они имеют связь «многие-ко-многим» (M:N). Например, в случае студентов и курсов, поскольку студент может посещать много курсов, и каждый курс могут посещать много студентов.
На ER-диаграмме эти связи отображаются с помощью следующих строк:
При проектировании структуры базы данных реализовать такого рода связи невозможно. Вместо этого нужно разбить их на две связи «один-ко-многим».
Для этого нужно создать между этими двумя таблицами новую сущность. Если между продажами и продуктами существует связь M:N, можно назвать этот новый объект «sold_products», так как он будет содержать данные для каждой продажи. И таблица продаж, и таблица товаров будут иметь связь 1:M с sold_products. Этот вид промежуточного объекта в различных моделях называется таблицей ссылок, ассоциативным объектом или таблицей связей.
Каждая запись в таблице связей будет соответствовать двум сущностям из соседних таблиц. Например, таблица связей между студентами и курсами может выглядеть следующим образом:
Создание базы данных SQL и работа с таблицами в SQL
Обязательно или нет?
Другим способом анализа связей является рассмотрение того, какая сторона связи должна существовать, чтобы существовала другая. Необязательная сторона может быть отмечена кружком на линии. Например, страна должна существовать для того, чтобы иметь представителя в Организации Объединенных Наций, а не наоборот:
Два объекта могут быть взаимозависимыми (один не может существовать без другого).
Рекурсивные связи
Иногда при проектировании базы данных таблица указывает на себя саму. Например, таблица сотрудников может иметь атрибут «руководитель», который ссылается на другое лицо в этой же таблице. Это называется рекурсивными связями.
Лишние связи
Лишние связи — это те, которые выражены более одного раза
Как правило, можно удалить одну из таких связей без потери какой-либо важной информации. Например, если объект «ученики» имеет прямую связь с другим объектом, называемым «учителя», но также имеет косвенные отношения с учителями через «предметы», нужно удалить связь между «учениками» и «учителями»
Так как единственный способ, которым ученикам назначают учителей — это предметы.
Логическое проектирование и оптимизация
OLTP – обработка транзакций в режиме реального времени. Способ организации БД, при котором система работает с небольшими по размерам транзакциями, но идущими большим потоком, и при этом клиенту требуется от системы минимальное время отклика. Примерами OLTP приложений могут быть системы складского учета, системы заказов билетов, банковские системы, выполняющие операции по переводу денег.
Особенности OLTP приложений:
- Транзакций очень много.
- Транзакции выполняются одновременно.
- При возникновении ошибки транзакция должна целиком откатиться и вернуть систему к состоянию, которое было до начала транзакции (не должно быть ситуации, когда деньги сняты со счета, но не поступили на другой счет).
- Все запросы к базе данных, которые должны выполняться в реальном времени, состоят из команд вставки, обновления, удаления.
OLAP системы характеризуются следующими признаками:
- Добавление в систему новых данных происходит относительно редко крупными блоками.
- Данные, добавленные в систему, обычно никогда не удаляются.
- Перед загрузкой данные проходят различные процедуры очистки, связанные с тем, что в одну систему могут поступать данные из многих источников, имеющих различные форматы представления для одних и тех же понятий, данные могут быть некорректны, ошибочны
- Запросы к системе являются нерегламентированными и, как правило, достаточно сложными. Очень часто новый запрос формулируется аналитиком для уточнения результата, полученного при выполнении предыдущего запроса.
- Скорость выполнения запросов важна, но не критична.
Создание базы данных с помощью шаблона
В Access есть разнообразные шаблоны, которые можно использовать как есть или в качестве отправной точки. Шаблон — это готовая к использованию база данных, содержащая все таблицы, запросы, формы, макросы и отчеты, необходимые для выполнения определенной задачи. Например, существуют шаблоны, которые можно использовать для отслеживания вопросов, управления контактами или учета расходов. Некоторые шаблоны содержат примеры записей, демонстрирующие их использование.
Если один из этих шаблонов вам подходит, с его помощью обычно проще и быстрее всего создать необходимую базу данных. Однако если необходимо импортировать в Access данные из другой программы, возможно, будет проще создать базу данных без использования шаблона. Так как в шаблонах уже определена структура данных, на изменение существующих данных в соответствии с этой структурой может потребоваться много времени.
-
Если база данных открыта, нажмите на вкладке Файл кнопку Закрыть. В представлении Backstage откроется вкладка Создать.
-
На вкладке Создать доступно несколько наборов шаблонов. Некоторые из них встроены в Access, а другие шаблоны можно скачать с сайта Office.com. Дополнительные сведения см. в следующем разделе.
-
Выберите шаблон, который вы хотите использовать.
-
Access предложит имя файла для базы данных в поле «Имя файла». При этом имя файла можно изменить. Чтобы сохранить базу данных в другой папке, отличной от папки, которая отображается под полем «Имя файла», нажмите кнопку , перейдите к папке, в которой ее нужно сохранить, и нажмите кнопку «ОК». При желании вы можете создать базу данных и связать ее с сайтом SharePoint.
-
Нажмите кнопку Создать.
Access создаст базу данных на основе выбранного шаблона, а затем откроет ее. Для многих шаблонов при этом отображается форма, в которую можно начать вводить данные. Если шаблон содержит примеры данных, вы можете удалить каждую из этих записей, щелкнув область маркировки (затененное поле или полосу слева от записи) и выполнив действия, указанные ниже.
На вкладке Главная в группе Записи нажмите кнопку Удалить.
-
Щелкните первую пустую ячейку в форме и приступайте к вводу данных. Для открытия других необходимых форм или отчетов используйте область навигации. Некоторые шаблоны содержат форму навигации, которая позволяет перемещаться между разными объектами базы данных.
Дополнительные сведения о работе с шаблонами см. в статье Создание базы данных Access на компьютере с помощью шаблона.


