Открытие файла формата csv
Содержание:
- Writer Objects¶
- Examples¶
- Запись файлов CSV
- Writer объекты¶
- Важная информация о редактировании файлов CSV
- Файлы CSV
- Как структурированы csv файлы
- С помощью Pandas
- Другие способы преобразования файлов Excel в CSV
- Как преобразовать файл Excel в CSV
- Процедура открытия
- Чтение CSV-файла при помощи csv.reader(). Метод 1
- Метод # 4: анализ с помощью библиотек Python
- Теперь усложним задачу
- Указание разделителя¶
- Побеждаем порчу данных правильным импортом
- Метод # 2: разделить на несколько частей
- Устранение неполадок
- Методы для группировки данных по полю,полям в Таблице Значений на примере универсального метода списания по партиям, а также отбора строк в ТЗ по произвольному условию. Для 8.x и 7.7 Промо
Writer Objects¶
objects ( instances and objects returned by
the function) have the following public methods. A row must be
an iterable of strings or numbers for objects and a dictionary
mapping fieldnames to strings or numbers (by passing them through
first) for objects. Note that complex numbers are written
out surrounded by parens. This may cause some problems for other programs which
read CSV files (assuming they support complex numbers at all).
- (row)
-
Write the row parameter to the writer’s file object, formatted according
to the current . Return the return value of the call to the
write method of the underlying file object.Changed in version 3.5: Added support of arbitrary iterables.
- (rows)
-
Write all elements in rows (an iterable of row objects as described
above) to the writer’s file object, formatted according to the current
dialect.
Writer objects have the following public attribute:
-
A read-only description of the dialect in use by the writer.
DictWriter objects have the following public method:
Examples¶
The simplest example of reading a CSV file:
import csv
with open('some.csv', newline='') as f
reader = csv.reader(f)
for row in reader
print(row)
Reading a file with an alternate format:
import csv
with open('passwd', newline='') as f
reader = csv.reader(f, delimiter=':', quoting=csv.QUOTE_NONE)
for row in reader
print(row)
The corresponding simplest possible writing example is:
import csv
with open('some.csv', 'w', newline='') as f
writer = csv.writer(f)
writer.writerows(someiterable)
Since is used to open a CSV file for reading, the file
will by default be decoded into unicode using the system default
encoding (see ). To decode a file
using a different encoding, use the argument of open:
import csv
with open('some.csv', newline='', encoding='utf-8') as f
reader = csv.reader(f)
for row in reader
print(row)
The same applies to writing in something other than the system default
encoding: specify the encoding argument when opening the output file.
Registering a new dialect:
import csv
csv.register_dialect('unixpwd', delimiter=':', quoting=csv.QUOTE_NONE)
with open('passwd', newline='') as f
reader = csv.reader(f, 'unixpwd')
A slightly more advanced use of the reader — catching and reporting errors:
import csv, sys
filename = 'some.csv'
with open(filename, newline='') as f
reader = csv.reader(f)
try
for row in reader
print(row)
except csv.Error as e
sys.exit('file {}, line {}{}'.format(filename, reader.line_num, e))
And while the module doesn’t directly support parsing strings, it can easily be
done:
import csv
for row in csv.reader():
print(row)
Footnotes
- 1(,)
-
If is not specified, newlines embedded inside quoted fields
will not be interpreted correctly, and on platforms that use linendings
on write an extra will be added. It should always be safe to specify
, since the csv module does its own
() newline handling.
Запись файлов CSV
Мы также можем не только читать, но и писать любые новые и существующие файлы CSV. Запись файлов на Python осуществляется с помощью модуля csv.writer(). Он похож на модуль csv.reader() и также имеет два метода, то есть функцию записи или класс Dict Writer.
Он представляет две функции: writerow() и writerows(). Функция writerow() записывает только одну строку, а функция writerows() записывает более одной строки.
Диалекты
Они определяются как конструкция, которая позволяет создавать, хранить и повторно использовать различные параметры форматирования. Диалект поддерживает несколько атрибутов; наиболее часто используются:
- Dialect.delimiter: этот атрибут используется как разделительный символ между полями. Значение по умолчанию – запятая(,).
- Dialect.quotechar: этот атрибут используется для выделения полей, содержащих специальные символы, в кавычки.
- Dialect.lineterminator: используется для создания новых строк, значение по умолчанию – ‘\r\n’.
Запишем следующие данные в файл CSV.
data =
Пример –
import csv
with open('Python.csv', 'w') as csvfile:
fieldnames =
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'Rank': 'B', 'first_name': 'Parker', 'last_name': 'Brian'})
writer.writerow({'Rank': 'A', 'first_name': 'Smith',
'last_name': 'Rodriguez'})
writer.writerow({'Rank': 'B', 'first_name': 'Jane', 'last_name': 'Oscar'})
writer.writerow({'Rank': 'B', 'first_name': 'Jane', 'last_name': 'Loive'})
print("Writing complete")
Выход:
Writing complete
Он возвращает файл с именем Python.csv, который содержит следующие данные:
first_name,last_name,Rank Parker,Brian,B Smith,Rodriguez,A Jane,Oscar,B Jane,Loive,B
Writer объекты¶
У объектов ( сущности и объекты, возвращённые функцией
), есть следующий публичные методы. row должен быть
итератором строк или чисел для объектов и словаря,
отображающего имена полей в строки или числа (передав им сначала
) для объектов
Обратите внимание, что
комплексные числа записываются в окружении родителей. Это может вызвать некоторые
проблемы для других программ, которые читают файлы CSV (при условии,
что они вообще поддерживают комплексные числа)
- (row)
-
Записать параметр row в файл объекта writer, отформатированному
согласно текущему диалекту. Возвратит возвращаемое значение вызываемое
write методом основного объекта файла.Изменено в версии 3.5: Добавлена поддержка произвольных итераторов.
- (rows)
-
Написать все элементы в rows (итерируемый из объектов row, как
описано выше) к объекту файла writer’a, отформатированному согласно текущему
диалекту.
Объекты Writer содержат следующий публичный атрибут:
-
Описание диалекта, используемого Writer’ом только для чтения.
У объектов DictWriter есть следующий публичный метод:
Важная информация о редактировании файлов CSV
Вероятно, вы встретите файл CSV только при экспорте информации из одной программы в файл, а затем будете использовать этот же файл для импорта данных в другую программу, особенно при работе с приложениями, ориентированными на таблицы.
Однако, иногда вы можете отредактировать файл CSV или создать его с нуля, и в этом случае следует учитывать следующее:
Распространенной программой, используемой для открытия и редактирования файлов CSV, является Microsoft Excel
Что важно понять об использовании Excel или любой другой подобной программы для работы с электронными таблицами, даже если эти программы обеспечивают поддержку нескольких листов при редактировании файла CSV, формат CSV не поддерживает «листы» или «вкладки», поэтому данные, которые вы создаете в этих дополнительных областях, не будут записаны обратно в CSV при сохранении
Например, предположим, что вы изменяете данные на первом листе документа, а затем сохраняете файл в CSV – эти данные на первом листе – это то, что будет сохранено. Однако, если вы переключитесь на другой лист и добавите туда данные, а затем снова сохраните файл, то будет сохранена информация на последнем отредактированном листе – данные с первого листа больше не будут доступны после закрытия программы.
Это «природа» программного обеспечения для работы с электронными таблицами, которое делает эту задачу запутанной. Большинство инструментов для работы с электронными таблицами поддерживают такие вещи, как диаграммы, формулы, стили строк, изображения и другие вещи, которые просто невозможно сохранить в формате CSV.
Нет проблем, если вы понимаете это ограничение. Вот почему существуют другие, более продвинутые форматы таблиц, такие как XLSX. Другими словами, если вы хотите сохранить в CSV любую работу, кроме базовых изменений данных, не используйте CSV – вместо этого сохраните или экспортируйте в более расширенный формат.
Файлы CSV
Последнее обновление: 29.04.2017
Одним из распространенных файловых форматов, которые хранят в удобном виде информацию, является формат csv.
Каждая строка в файле csv представляет отдельную запись или строку, которая состоит из отдельных столбцов, разделенных запятыми. Собственно поэтому
формат и называется Comma Separated Values. Но хотя формат csv — это формат текстовых файлов, Python для упрощения работы с ним
предоставляет специальный встроенный модуль csv.
Рассмотрим работу модуля на примере:
import csv
FILENAME = "users.csv"
users = ,
,
]
with open(FILENAME, "w", newline="") as file:
writer = csv.writer(file)
writer.writerows(users)
with open(FILENAME, "a", newline="") as file:
user =
writer = csv.writer(file)
writer.writerow(user)
В файл записывается двухмерный список — фактически таблица, где каждая строка представляет одного пользователя. А каждый пользователь
содержит два поля — имя и возраст. То есть фактически таблица из трех строк и двух столбцов.
При открытии файла на запись в качестве третьего параметра указывается значение — пустая строка позволяет корректно считывать
строки из файла вне зависимости от операционной системы.
Для записи нам надо получить объект writer, который возвращается функцией . В эту функцию передается открытый файл.
А собственно запись производится с помощью метода Этот метод принимает набор строк. В нашем случае это двухмерный список.
Если необходимо добавить одну запись, которая представляет собой одномерный список, например, , то в этом случае можно вызвать метод
writer.writerow(user)
В итоге после выполнения скрипта в той же папке окажется файл users.csv, который будет иметь следующее содержимое:
Tom,28 Alice,23 Bob,34 Sam,31
Для чтения из файла нам наоборот нужно создать объект reader:
import csv
FILENAME = "users.csv"
with open(FILENAME, "r", newline="") as file:
reader = csv.reader(file)
for row in reader:
print(row, " - ", row)
При получении объекта reader мы можем в цикле перебрать все его строки:
Tom - 28 Alice - 23 Bob - 34 Sam - 31
Работа со словарями
В примере выше каждая запись или строка представляла собой отдельный список, например, . Но кроме того, модуль csv имеет
специальные дополнительные возможности для работы со словарями. В частности, функция csv.DictWriter() возвращает объект writer,
который позволяет записывать в файл. А функция csv.DictReader() возвращает объект reader для чтения из файла. Например:
import csv
FILENAME = "users.csv"
users =
with open(FILENAME, "w", newline="") as file:
columns =
writer = csv.DictWriter(file, fieldnames=columns)
writer.writeheader()
# запись нескольких строк
writer.writerows(users)
user = {"name" : "Sam", "age": 41}
# запись одной строки
writer.writerow(user)
with open(FILENAME, "r", newline="") as file:
reader = csv.DictReader(file)
for row in reader:
print(row, "-", row)
Запись строк также производится с помощью методов и . Но теперь каждая строка представляет собой отдельный словарь,
и кроме того, производится запись и заголовков столбцов с помощью метода writeheader(), а в метод csv.DictWriter в качестве второго параметра
передается набор столбцов.
При чтении строк, используя названия столбцов, мы можем обратиться к отдельным значениям внутри строки: .
НазадВперед
Как структурированы csv файлы
Шаблоны CSV или файлы данных можно загрузить по ссылкам в верхней части инструмента «Загрузить данные». Первая строка шаблона или файла данных содержит заголовки столбцов. Каждая последующая строка соответствует записи в базе данных. Когда загружается шаблон CSV, он содержит только заголовки столбцов. Поскольку шаблоны используются для добавления новых записей, новые строки будут добавляться для каждой записи.
Когда документ данных CSV загружается, первая строка содержит заголовок столбца, а последующие строки содержат записи данных, которые уже существуют в базе данных. Записи в этих строках можно редактировать или удалять.
В документе CSV каждая строка содержит упорядоченную последовательность заголовков столбцов или значений, разделенных запятыми. Запятые используются для сохранения файловой структуры. Каждая запятая в первой строке (которая содержит заголовки столбцов) разделяет заголовок столбца и место в упорядоченной последовательности столбцов.
Запятые в последующих строках также поддерживают последовательность упорядоченных столбцов, поэтому первое значение в каждой последующей строке представляет значение в первом столбце, второе значение в каждой последующей строке представляет значение во втором столбце и так далее. В отличие от стандартной пунктуации предложений, после запятой не ставится пробел.
Большинство значений заключено в двойные кавычки. Исключением является односимвольное значение, например 1 или 0 (ноль). Заключение значения в двойные кавычки позволяет использовать в поле сложные значения, например, содержащие запятые, без нарушения структуры документа. Например, поле, содержащее ряд элементов, например избранные цвета, может иметь такое значение:
“красный, зеленый и синий”
Вы не будете знать об этих цитатах при просмотре файла данных в приложении для работы с электронными таблицами, но они появляются, когда file просматривается в текстовом редакторе.
С помощью Pandas
Это так же просто, как прочитать файл CSV с помощью pandas. Вам необходимо создать DataFrame, который представляет собой двумерную неоднородную табличную структуру данных и состоит из трех основных компонентов: данных, столбцов и строк. Здесь мы берем для чтения немного более сложный файл под названием hrdata.csv, который содержит данные о сотрудниках компании.
Name,Hire Date,Salary,Leaves Remaining John Idle,08/15/14,50000.00,10 Smith Gilliam,04/07/15,65000.00,8 Parker Chapman,02/21/14,45000.00,10 Jones Palin,10/14/13,70000.00,3 Terry Gilliam,07/22/14,48000.00,7 Michael Palin,06/28/13,66000.00,8
Пример –
import pandas
df = pandas.read_csv('hrdata.csv',
index_col='Employee',
parse_dates=,
header=0,
names=)
df.to_csv('hrdata_modified.csv')
Выход:
Employee, Hired, Salary, Sick Days John Idle, 2014-03-15, 50000.0,10 Smith Gilliam, 2015-06-01, 65000.0,8 Parker Chapman, 2014-05-12, 45000.0,10 Jones Palin, 2013-11-01, 70000.0,3 Terry Gilliam, 2014-08-12 , 48000.0,7 Michael Palin, 2013-05-23, 66000.0,8
Изучаю Python вместе с вами, читаю, собираю и записываю информацию опытных программистов.
Другие способы преобразования файлов Excel в CSV
Описанные выше способы экспорта данных из Excel в CSV (UTF-8 и UTF-16) универсальны, т.е. подойдут для работы с любыми специальными символами и в любой версии Excel от 2003 до 2013.
Существует множество других способов преобразования данных из формата Excel в CSV. В отличие от показанных выше решений, эти способы не будут давать в результате чистый UTF-8 файл (это не касается , который умеет экспортировать файлы Excel в несколько вариантов кодировки UTF). Но в большинстве случаев получившийся файл будет содержать правильный набор символов, который далее можно безболезненно преобразовать в формат UTF-8 при помощи любого текстового редактора.
Преобразуем файл Excel в CSV при помощи Таблиц Google
Как оказалось, можно очень просто преобразовать файл Excel в CSV при помощи Таблиц Google. При условии, что на Вашем компьютере уже установлен , выполните следующие 5 простых шагов:
- В Google Drive нажмите кнопку Создать (Create) и выберите Таблица (Spreadsheet).
- В меню Файл (File) нажмите Импорт (Import).
- Кликните Загрузка (Upload) и выберите файл Excel для загрузки со своего компьютера.
- В диалоговом окне Импорт файла (Import file) выберите Заменить таблицу (Replace spreadsheet) и нажмите Импорт (Import).
Совет: Если файл Excel относительно небольшой, то для экономии времени можно перенести из него данные в таблицу Google при помощи копирования / вставки.
- В меню Файл (File) нажмите Скачать как (Download as), выберите тип файла CSV – файл будет сохранён на компьютере.
В завершение откройте созданный CSV-файл в любом текстовом редакторе, чтобы убедиться, что все символы сохранены правильно. К сожалению, файлы CSV, созданные таким способом, не всегда правильно отображаются в Excel.
Сохраняем файл .xlsx как .xls и затем преобразуем в файл CSV
Для этого способа не требуется каких-либо дополнительных комментариев, так как из названия уже всё ясно.
Это решение я нашёл на одном из форумов, посвящённых Excel, уже не помню, на каком именно. Честно говоря, я никогда не использовал этот способ, но, по отзывам множества пользователей, некоторые специальные символы теряются, если сохранять непосредственно из .xlsx в .csv, но остаются, если сначала .xlsx сохранить как .xls, и затем как .csv, как мы .
Так или иначе, попробуйте сами такой способ создания файлов CSV из Excel, и если получится, то это будет хорошая экономия времени.
Сохраняем файл Excel как CSV при помощи OpenOffice
OpenOffice – это пакет приложений с открытым исходным кодом, включает в себя приложение для работы с таблицами, которое отлично справляется с задачей экспорта данных из формата Excel в CSV. На самом деле, это приложение предоставляет доступ к большему числу параметров при преобразовании таблиц в файлы CSV (кодировка, разделители и так далее), чем Excel и Google Sheets вместе взятые.
Просто открываем файл Excel в OpenOffice Calc, нажимаем Файл > Сохранить как (File > Save as) и выбираем тип файла Текст CSV (Text CSV).
На следующем шаге предлагается выбрать значения параметров Кодировка (Character sets) и Разделитель поля (Field delimiter). Разумеется, если мы хотим создать файл CSV UTF-8 с запятыми в качестве разделителей, то выбираем UTF-8 и вписываем запятую (,) в соответствующих полях. Параметр Разделитель текста (Text delimiter) обычно оставляют без изменения – кавычки («). Далее нажимаем ОК.
Таким же образом для быстрого и безболезненного преобразования из Excel в CSV можно использовать ещё одно приложение – LibreOffice. Согласитесь, было бы здорово, если бы Microsoft Excel предоставил возможность так же настраивать параметры при создании файлов CSV.
Как преобразовать файл Excel в CSV
Если требуется экспортировать файл Excel в какое-либо другое приложение, например, в адресную книгу Outlook или в базу данных Access, предварительно преобразуйте лист Excel в файл CSV, а затем импортируйте файл .csv в другое приложение. Ниже дано пошаговое руководство, как экспортировать рабочую книгу Excel в формат CSV при помощи инструмента Excel – «Сохранить как».
- В рабочей книге Excel откройте вкладку Файл (File) и нажмите Сохранить как (Save as). Кроме этого, диалоговое окно Сохранение документа (Save as) можно открыть, нажав клавишу F12.
- В поле Тип файла (Save as type) выберите CSV (разделители – запятые) (CSV (Comma delimited)).Кроме CSV (разделители – запятые), доступны несколько других вариантов формата CSV:
- CSV (разделители – запятые) (CSV (Comma delimited)). Этот формат хранит данные Excel, как текстовый файл с разделителями запятыми, и может быть использован в другом приложении Windows и в другой версии операционной системы Windows.
- CSV (Macintosh). Этот формат сохраняет книгу Excel, как файл с разделителями запятыми для использования в операционной системе Mac.
- CSV (MS-DOS). Сохраняет книгу Excel, как файл с разделителями запятыми для использования в операционной системе MS-DOS.
- Текст Юникод (Unicode Text (*txt)). Этот стандарт поддерживается почти во всех существующих операционных системах, в том числе в Windows, Macintosh, Linux и Solaris Unix. Он поддерживает символы почти всех современных и даже некоторых древних языков. Поэтому, если книга Excel содержит данные на иностранных языках, то рекомендую сначала сохранить её в формате Текст Юникод (Unicode Text (*txt)), а затем преобразовать в CSV, как описано далее в разделе .
Замечание: Все упомянутые форматы сохраняют только активный лист Excel.
- Выберите папку для сохранения файла в формате CSV и нажмите Сохранить (Save).После нажатия Сохранить (Save) появятся два диалоговых окна. Не переживайте, эти сообщения не говорят об ошибке, так и должно быть.
- Первое диалоговое окно напоминает о том, что В файле выбранного типа может быть сохранён только текущий лист (The selected file type does not support workbooks that contain multiple sheets). Чтобы сохранить только текущий лист, достаточно нажать ОК.Если нужно сохранить все листы книги, то нажмите Отмена (Cancel) и сохраните все листы книги по-отдельности с соответствующими именами файлов, или можете выбрать для сохранения другой тип файла, поддерживающий несколько страниц.
- После нажатия ОК в первом диалоговом окне, появится второе, предупреждающее о том, что некоторые возможности станут недоступны, так как не поддерживаются форматом CSV. Так и должно быть, поэтому просто жмите Да (Yes).
Вот так рабочий лист Excel можно сохранить как файл CSV. Быстро и просто, и вряд ли тут могут возникнуть какие-либо трудности.
Процедура открытия
Не так много онлайн-сервисов предлагают возможность не только конвертации, но и удаленного просмотра содержимого файлов CSV. Тем не менее, такие ресурсы существуют. Об алгоритме работы с некоторыми из них мы и поговорим в этой статье.
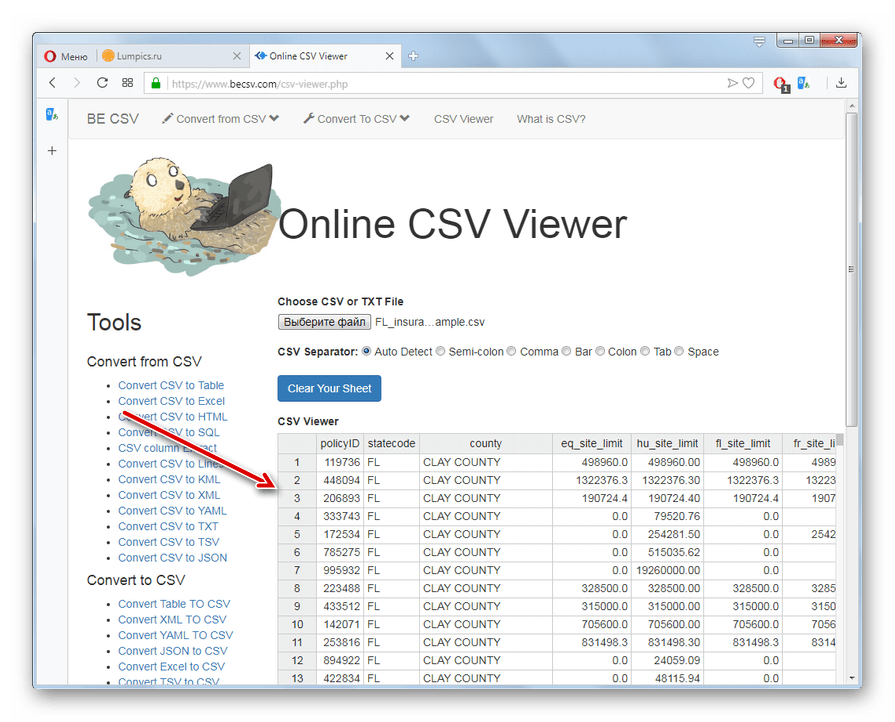
Способ 1: BeCSV
Одним из самых популярных сервисов, который специализируется на работе с CSV, является BeCSV. На нем можно не только просматривать указанный тип файлов, но и преобразовывать в данный формат объекты с другими расширениями и наоборот.
Способ 2: ConvertCSV
Ещё одним онлайн-ресурсом, на котором можно производить различные манипуляции с объектами формата CSV, в том числе и просмотр их содержимого, является популярный сервис ConvertCSV.
- Перейдите на главную страницу ConvertCSV по представленной выше ссылке. Далее щелкните по пункту «CSV Viewer and Editor».
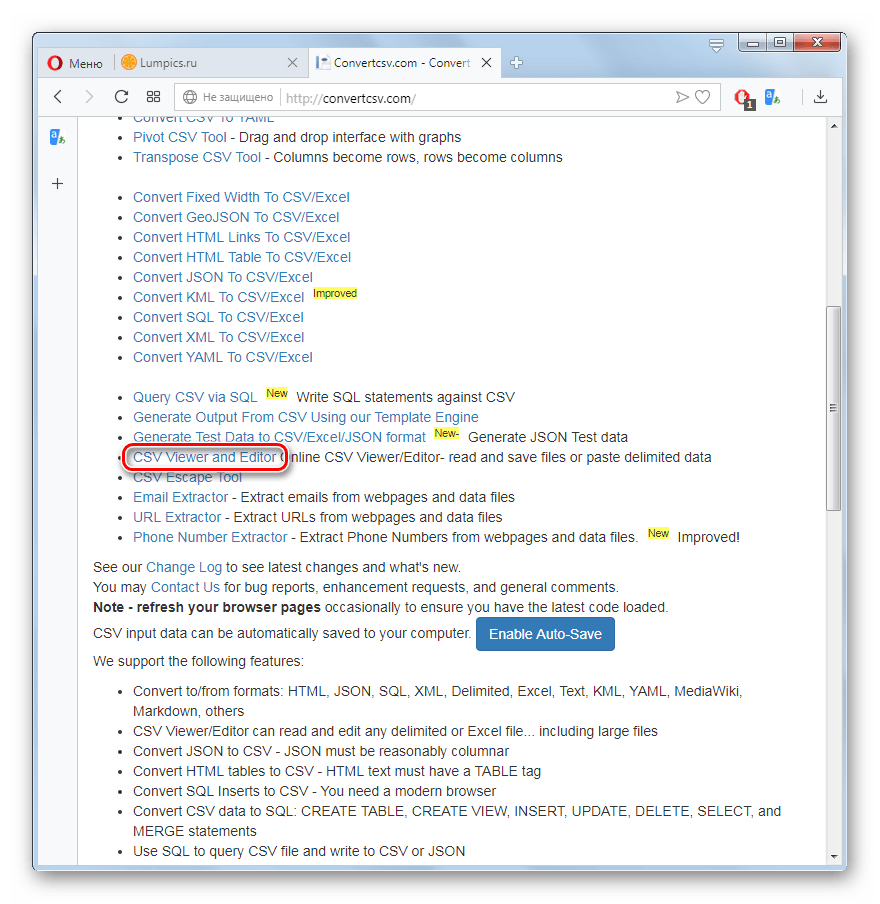
Откроется раздел, в котором можно онлайн не только просматривать, но и редактировать CSV. В отличие от предыдущего метода, данный сервис в блоке «Select your input» предлагает сразу 3 варианта добавления объекта:
- Выбор файла с компьютера или с подключенного к ПК дискового носителя;
- Добавление ссылки на размещенный в интернете CSV;
- Ручная вставка данных.
Так как задачей, которая ставится в этой статье, является просмотр уже существующего файла, в данном случае подойдет первый и второй варианты, в зависимости от того, где объект размещен: на жестком диске ПК или в сети.
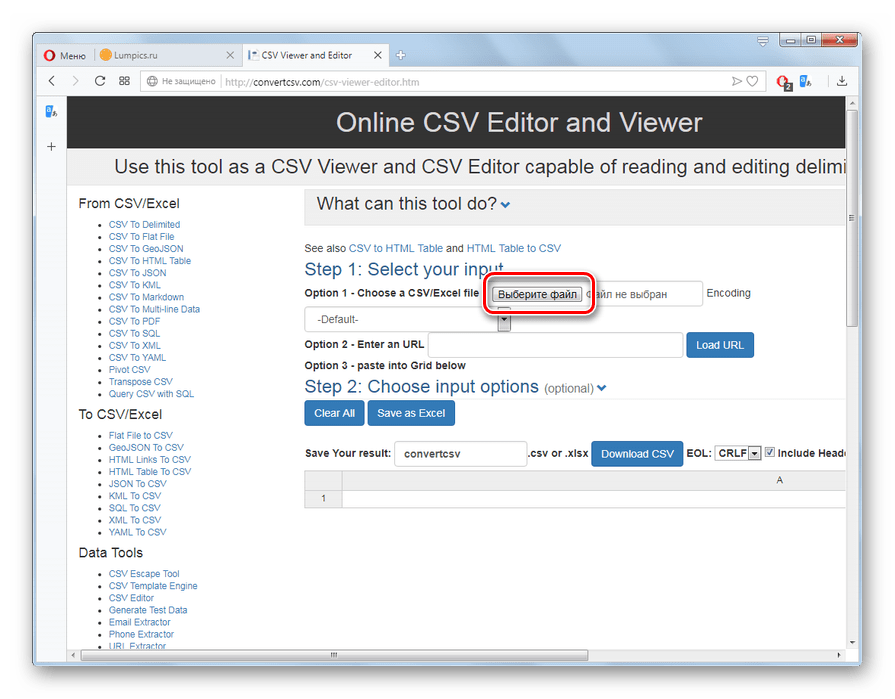
При добавлении размещенного на компьютере CSV щелкните напротив опции «Choose a CSV/Excel file» по кнопке «Выберите файл».
Далее, как и при использовании предыдущего сервиса, в открывшемся окне выбора файла переместитесь в директорию дискового носителя, которая содержит в себе CSV, выделите этот объект и нажмите «Открыть».
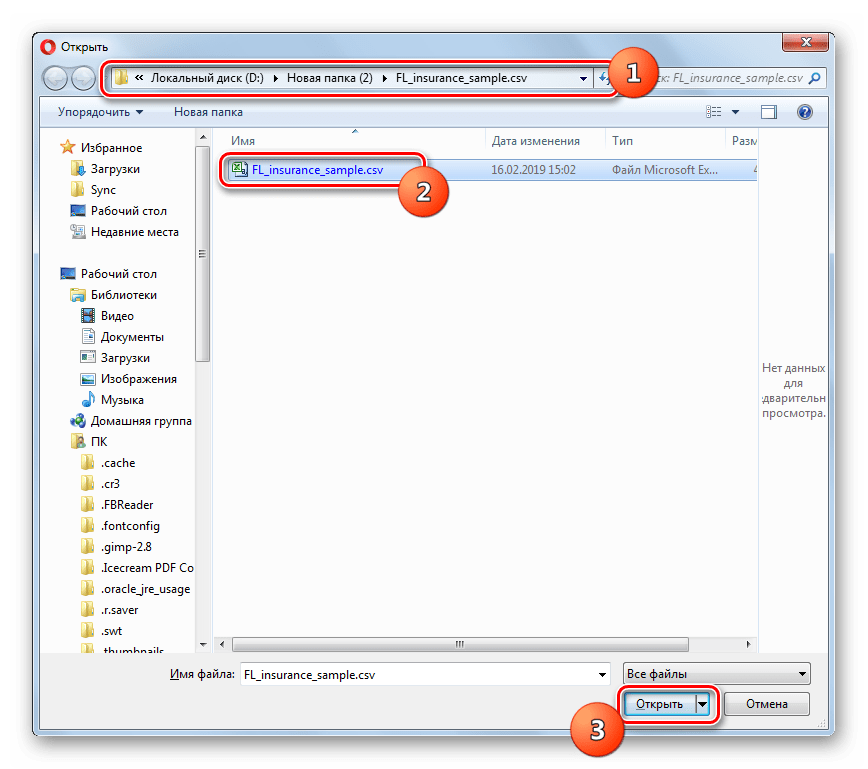
После того как вы щелкнули по вышеуказанной кнопке, объект будет загружен на сайт и его содержимое отобразится в табличном виде прямо на странице.
Если же вы желаете просмотреть содержимое файла, который размещен во всемирной паутине, в этом случае напротив опции «Enter an URL» введите полный его адрес и щелкните по кнопке «Load URL». Результат будет представлен в табличном виде, как и при загрузке CSV с компьютера.
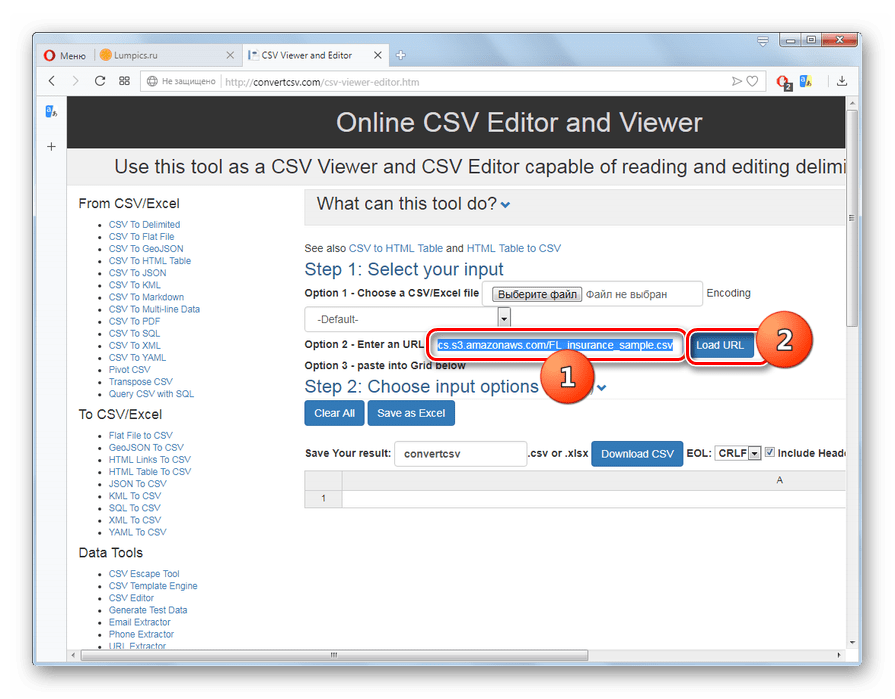
Из двух рассмотренных веб-сервисов ConvertCSV является несколько более функциональным, так как позволяет производить не только просмотр, но и редактирование CSV, а также выполнять загрузку исходника из интернета. Но для простого просмотра содержимого объекта возможностей сайта BeCSV тоже будет вполне достаточно.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Чтение CSV-файла при помощи csv.reader(). Метод 1
Пример 1. Использование запятой в качестве разделителя
Допустим, у нас есть файл с именем sample1, содержащий некоторые данные. Такой файл можно создать с помощью любого текстового редактора или путем передачи значений в какую-нибудь программу для записи файла CSV. Как это делается, мы расскажем чуть позже.
Текст в этом файле разделен запятыми. Наши данные — сведения о различных книгах (порядковый номер, название, имя автора).
Переходим к коду. Чтобы прочитать файл CSV, нам нужен объект reader для выполнения функции чтения. Первым делом импортируем модуль (встроенный модуль Python). Далее укажем имя файла, который нужно открыть (или путь к нему). Затем инициализируем объект . Он будет перебираться в цикле .
reader = csv.reader(файл)
Данные из указанного файла выводятся построчно.
Запустим наш код. Можем увидеть, что наши данные автоматически преобразовались в списки, состоящие из элементов данных каждой строки.
Пример 2. Использование табуляции в качестве разделителя
В первом примере текст разделяется запятой. Однако мы можем сделать наш код более настраиваемым, добавив различные функции.
Возьмём код из предыдущего примера и сделаем лишь одно изменение: напрямую укажем разделитель (). В предыдущем примере не было никакой необходимости его указывать, потому что запятая — разделитель по умолчанию.
reader = csv.reader(file, delimiter = ‘\t’)
Как видите, результат немного изменился. Теперь все элементы строки являются одним элементом списка. Так произошло потому, что в этот раз мы указали в качестве разделителя не запятую, а .
Метод # 4: анализ с помощью библиотек Python
Когда вы работаете с файлом .csv с миллионами строк данных, вы, очевидно, не сможете понять его вручную. Вероятно, вы захотите отфильтровать данные и выполнить определенные запросы, чтобы понять тенденции.
Так почему не написать код Python сделать именно это?
Опять же, это не самый удобный метод. В то время как Python — не самый сложный язык программирования для изучения, это кодирование, поэтому он может быть не лучшим подходом для вас. Тем не менее, если вам приходится ежедневно анализировать действительно большие файлы CSV, вы можете захотеть автоматизировать задачу с помощью некоторого кода Python.
Теперь усложним задачу
Метод экранирования запятых внутри полей вводит необходимость в экранировании другого символа: кавычек. Что будет, если, например, в исходных данных были кавычки, как показано в табл. 1?
Табл. 1. Исходные данные с кавычками
{Для верстки: таблица не переводится, так как это просто исходные данные}
| Office Division | Employees | Unit Sales | Office Motto |
| New York, NY | 73 | 8300 | “We sell great products” |
| Richmond, VA | 42 | 3000 | “Try it and you’ll want to buy it” |
| San Jose, CA | 35 | 4250 | “Powering Silicon Valley!” |
| Chicago, IL | 18 | 1200 | “Great products at great value” |
Исходный текст в самом CSV-файле выглядел бы так:
Один символ кавычек (“) после экранирования превращается в три символа кавычек (“””), что добавляет алгоритму интересную особенность. Конечно, сразу же возникает резонный вопрос: почему одна кавычка превращается в три? Как и в поле Office Division, содержимое этого поля заключается в кавычки. Чтобы экранировать символы кавычек, которые являются частью контента, они удваиваются. Поэтому “ становится “”.
Другой пример (табл. 2) более наглядно продемонстрирует этот процесс.
Табл. 2. Данные цитат
{Для верстки: то же самое — таблица не переводится, так как это просто исходные данные, причем нужно сохранить дефисы именно так, как есть в оригинале}
| Quote |
| «The only thing we have to fear is fear itself.» -President Roosevelt |
| «Logic will get you from A to B. Imagination will take you everywhere.» -Albert Einstein |
Данные из табл. 2 были бы представлены в CSV следующим образом:
Quote
Теперь должно быть понятнее, что поле заключается в кавычки и что индивидуальные кавычки в содержимом поля удваиваются.
Указание разделителя¶
Иногда в качестве разделителя используются другие значения. В таком
случае должна быть возможность подсказать модулю, какой именно
разделитель использовать.
Например, если в файле используется разделитель (файл
sw_data2.csv):
hostname;vendor;model;location sw1;Cisco;3750;London sw2;Cisco;3850;Liverpool sw3;Cisco;3650;Liverpool sw4;Cisco;3650;London
Достаточно просто указать, какой разделитель используется в reader (файл
csv_read_delimiter.py):
import csv
with open('sw_data2.csv') as f
reader = csv.reader(f, delimiter=';')
for row in reader
print(row)
Побеждаем порчу данных правильным импортом
Если серьезно, в бедах виноват не Excel целиком, а неочевидный способ импорта данных в программу. По умолчанию Excel применяет к данным в загруженном CSV-файле тип «General» — общий. Из-за него программа распознает цифровые строки как числа. Такой порядок можно победить, используя встроенный инструмент импорта.
Запускаю встроенный в Excel механизм импорта.
В меню это «Data → Get External Data → From Text».
Выбираю CSV-файл с данными, открывается диалог.
В диалоге кликаю на тип файла Delimited (с разделителями). Кодировка — та, что в файле, обычно определяется автоматом. Если первая строка файла — шапка, о.
Перехожу ко второму шагу диалога.
Выбираю разделитель полей (обычно это точка с запятой — semicolon). Отключаю «Treat consecutive delimiters as one», а «Text qualifier» выставляю в «{none}». (Text qualifier — это символ начала и конца текста. Если разделитель в CSV — запятая, то text qualifier нужен, чтобы отличать запятые внутри текста от запятых-разделителей.)
На третьем шаге выбираю формат полей
, ради него все и затевалось. Для всех столбцов выставляю тип «Text». Кстати, если кликнуть на первую колонку, зажать шифт и кликнуть на последнюю, выделятся сразу все столбцы. Удобно.
Дальше Excel спросит, куда вставлять данные из CSV — можно просто нажать «OK», и данные появятся в открытом листе.

Перед импортом придется создать в Excel новый workbook
Но! Если я планирую добавлять данные в CSV через Excel, придется сделать еще кое-что.
После импорта нужно принудительно привести все-все ячейки на листе к формату «Text». Иначе новые поля приобретут все тот же тип «General».
- Нажимаю два раза Ctrl+A, Excel выбирает все ячейки на листе;
- кликаю правой кнопкой мыши;
- выбираю в контекстном меню «Format Cells»;
- в открывшемся диалоге выбираю слева тип данных «Text».

Чтобы выделить все ячейки, нужно нажать Ctrl+A два раза. Именно два, это не шутка, попробуйте После этого, если повезет, Excel оставит исходные данные в покое. Но это не самая твердая гарантия, поэтому мы после сохранения обязательно проверяем файл через текстовый просмотрщик.
Метод # 2: разделить на несколько частей
Вся проблема при попытке открыть большие CSV-файлы в том, что они слишком большие. Но что, если бы вы разбили их на несколько файлов меньшего размера?
Это популярное решение, поскольку обычно не требует изучения интерфейса нового текстового редактора. Вместо этого вы можете использовать один из многих разделителей CSV, доступных в Интернете чтобы разбить большой файл на несколько легко открываемых файлов. После этого можно будет получить доступ к каждому из этих файлов в обычном режиме.
Однако это не лучший способ сделать это. Разделение большого файла часто может приводить к странным опечаткам или неправильно настроенным файлам. Более того, открытие каждого фрагмента по отдельности предотвращает фильтрацию всех данных сразу.
Устранение неполадок
Частые проблемы с открытием CSV
Microsoft Excel Исчез
При двойном щелчке CSV-файла может появиться диалоговое окно операционной системы с сообщением о том, что он «Не удается открыть этот тип файла». Когда это происходит, это обычно связано с отсутствием Microsoft Excel в %%os%%. Поскольку ваша операционная система не знает, что делать с этим файлом, вы не сможете открыть его двойным щелчком мыши.
Наконечник: Если у вас не установлен Microsoft Excel, и вы знаете другую программу, чтобы открыть файл CSV, вы можете попробовать открыть его, выбрав из программ, перечисленных в разделе «Показать приложения».
Неверная версия Microsoft Excel
Иногда может быть установлена устаревшая версия Microsoft Excel, несовместимая с типом Comma Separated Values File. Рекомендуется установить последнюю версию Microsoft Excel из Microsoft Corporation. Эта проблема в основном возникает, когда файл Comma Separated Values File был создан более новой версией Microsoft Excel, чем на компьютере.
Совет . Найдите подсказки о правильной версии программного обеспечения, щелкнув правой кнопкой мыши CSV-файл и выбрав «Свойства».
Сводка. Наличие правильной версии Microsoft Excel на компьютере может вызвать проблемы с открытием CSV-файлов.
В большинстве случаев установка правильной версии Microsoft Excel решит вашу проблему. Если у вас по-прежнему возникают проблемы с открытием файлов CSV, могут возникнуть другие проблемы с компьютером. К числу этих вопросов относятся:
Методы для группировки данных по полю,полям в Таблице Значений на примере универсального метода списания по партиям, а также отбора строк в ТЗ по произвольному условию. Для 8.x и 7.7 Промо
Я очень часто использую группировку данных по полю и полям, как в восьмерке, так и в семерке. Это аналог запроса Итоги, но там строится дерево, а в большинстве случаев нужны «плоские данные». Да и делать запрос в большинстве случаев более накладный процесс, чем работа с ТЗ.
Все достоинства такого подхода приведены на примере метода универсального списания по париям, а так же отбора строк в ТЗ по произвольному условию.
Для 7.7 еще отчеты сравнения двух ТЗ. Работая с различными базами для упрощения сравнения номенклатуры, или как аналог джойнов(join), сделал сравнение двух таблиц значений по нескольким полям. Пока группировки полей должны быть уникальны.
Часто приходится искать дубли, для универсального поиска есть ДублиВТзПоПолю и пример в Тест.ert.
1 стартмани


