Кей коллектор: инструкция по работе и настройке программы
Содержание:
- Экспорт групп ключевых фраз
- Главное меню программы
- Выполнение поиска и работа с результатами
- Аналоги Key Collector
- Запуск программы и кластеризация
- Что это может значить на практике?
- Минусация
- Первичный сбор частотности ключевых фраз
- Как собрать запросы в группы на основе выдачи Google
- Переименование и цветовая маркировка
- Дополнительно
- Работа с группировками запросов
- Вывод
Экспорт групп ключевых фраз
Для экспорта нам потребуется:
Объединить все группы в одну мульти-группу, для этого:
Выделяем все группы которые нам нужны.
И нажимаем на значек Включения мульти-группы
Мульти-группы в Key Collector
После этого в верхнем меню программы нажимаем на значок экспорта в виде Excel страницы.
CSV файл из Key Collector
И сохраняем его в нужном нам месте.
Вот и всё!
В получившемся файле можно скопировать в шаблон для составления объявлений столбцы с названием групп – наши будущие названия групп объявлений и столбец с ключевыми фразами входящие в эти группы.
Таким образом, с помощью прокси-серверов, первичного сбора статистики, мы максимально уменьшаем количество времени затраченного на сбор семантического ядра.
Главное меню программы
Для того, чтобы попасть в меню нам нужно в верхнем правом углу выбрать “Файл”.

Добро пожаловать в Key Collector!
В появившемся меню вы можете создать новый файл или открыть уже ранее существующий проект, импортировать данные из другого проекта или файла в формате CSV.
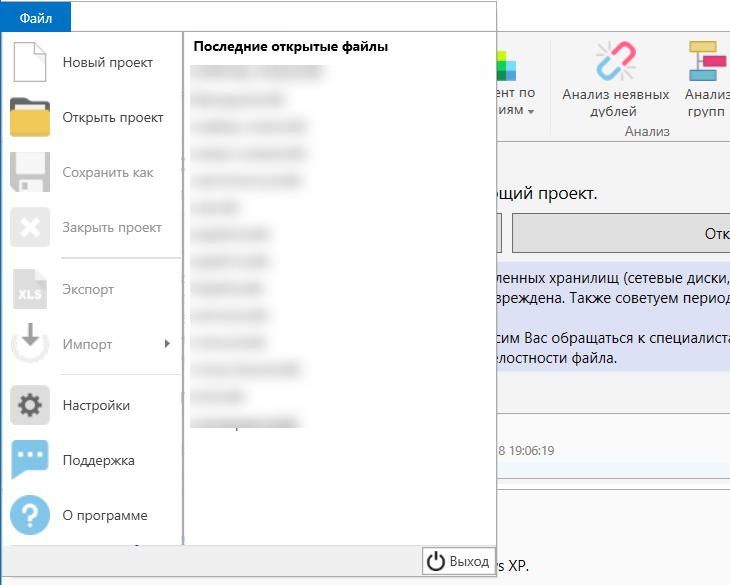
Загрузка проекта
Меню быстрого доступа
Используя меню быстрого доступа вы можете добавить наиболее часто используемые кнопки.
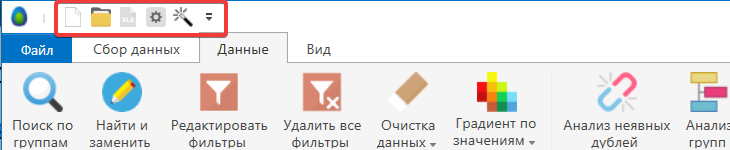
Меню быстрого доступа
Для добавления новых элементов нужно правой кнопкой мышки нажать на интересующий значок. После чего в появившемся окне выбрать пункт “Добавить в панель быстрого доступа”
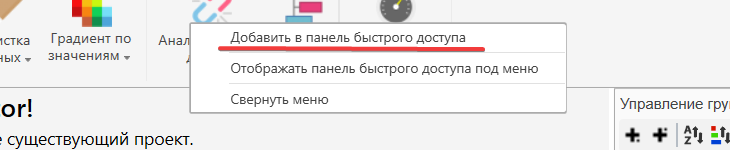
Добавить в палень быстрого доступа
Теперь данный элемент будет добавлен в меню. Если вы захотите удалить кнопку из меню быстрого доступа, тогда проделайте аналогичные действия: нажмите правой кнопкой мышки на иконку и дальше в меню выберите “Удалить с панели быстрого доступа”.
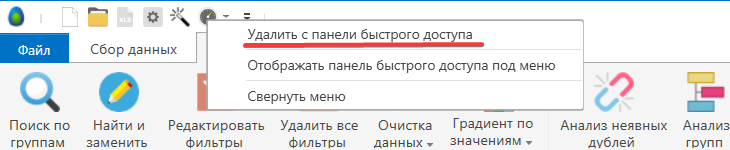
Удалить с панели быстрого доступа
Основная рабочая область
Основную рабочую область используют для отображения пользовательских групп и экрана приветствия после запуска программы. В ней вы можете ознакомиться со свежими новостям относительно программы, увидеть статистику хода выполнения работы и т.д.
Область новостей, журнала событий и статистика

Область новостей, журнала событий и статистика
Данная вкладка предназначена для:
-
Отображения журнала событий.
-
Получения последних новостей программы.
-
Просмотра статистики по текущему выполнению задач.
-
Просмотра дополнительных данных статистики: отображение списка релевантных страниц, графиков истории позиций, сезонности, поисковой выдачи и тд.
Под просмотром дополнительной статистики имеется в виду просмотр тех данных, которые не могут быть показаны в стандартных таблицах и выводятся для каждой фразы в отдельности. К дополнительной статистике принадлежит:
-
Просмотр количества акноров с помощью сервиса Solomono. Используем кнопку “Количество анкоров Solomono”.
-
Просмотр с помощью графика или в виде таблицы истории позиций. Для этого нажимаем “Позиция Yandex” и “Позиция Google”.
-
Просмотр состава поисковой выдачи по какому-либо запросу: адреса страниц, заголовки, сниппеты. Для этого используем «Кол-во вхождений в заголовок «, «Кол-во вхождений в заголовок » и «Кол-во вхождений в заголовок «.
-
Просмотр релевантных страниц — колонки «Рел. страница » и «Рел. страница «.
-
Просмотр частотности слов по месяцам для Google Adwors — колонка «Частотность (регионы) »
-
Просмотр частотности для Yandex Wordstats по неделям и месяцам. Для этого переходим в раздел «Сезонность «.
Для того, чтобы увидеть данную статистику надо выбрать нужную фразу и перейти во вкладку “Дополнительная статистика”. В этом меню будет доступна интересующая подвкладка с дополнительной статистикой.
Отображение вкладок можно настроить на свое усмотрение. Для этого надо зажать левую кнопку мышки на заголовок с вкладкой и перетащить в нужную сторону.

Отображение вкладок
Панель состояния
Панель состояния нужна для показа информации о количестве отмеченных строк и информацию об использовании автоматической капчи.

Панель состояния
Выше выделена кнопка принудительного обновления содержимого активной таблицы.
Выполнение поиска и работа с результатами
Итак, после выбора группы минус-слов, формирования списка минусации и установки настроек вы можете выполнить поиск.
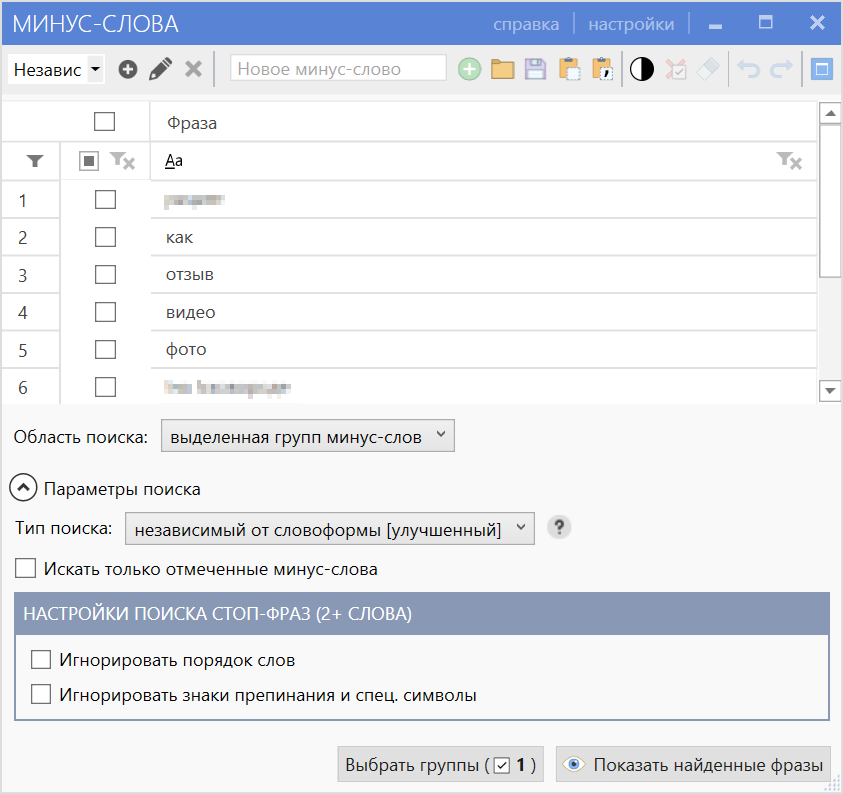
По завершении поиска открывается временная мультигруппа с результатами.
В ленте инструментов при этом будет добавлена контекстная вкладка «Предпросмотр», которая позволит управлять временной мультигруппой.
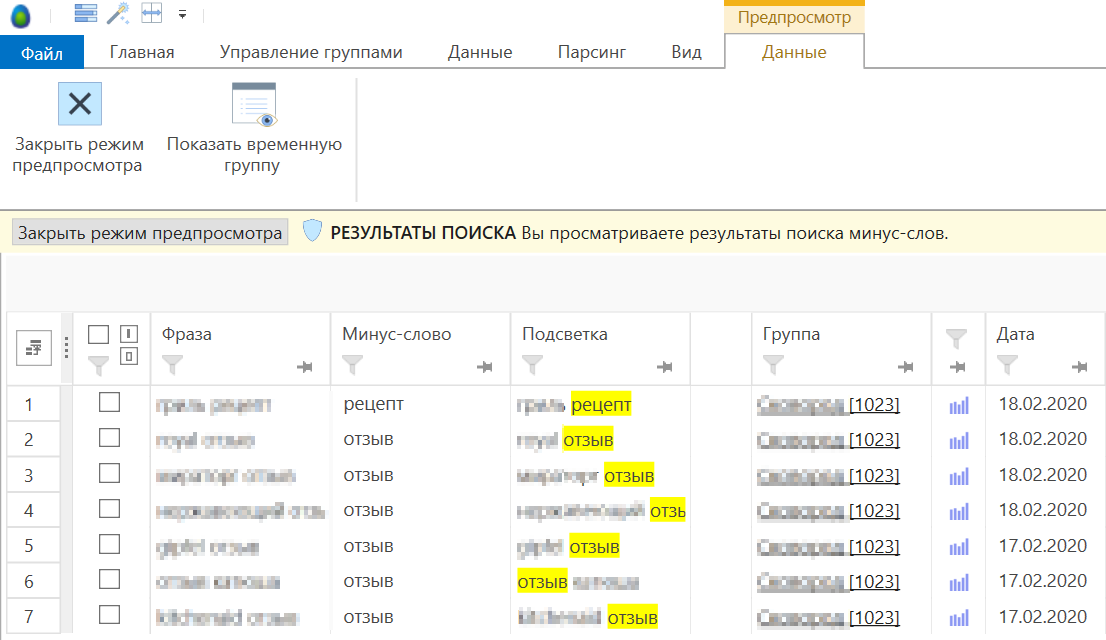
Таблица результатов содержит колонку подсветки, где отображается подсказка по найденному минус-слову в исходной фразе, а само найденное минус-слово отображается в колонке «Минус-слово».
Вы можете работать с результатами поиска в мультигруппе как с обычной мультигруппой: сортировать данные, применять фильтры, отмечать и удалять строки, запускать парсинг и т.д.
В колонке«Группа»отображается название целевой группы, где была найдена фраза из указанных групп-источников. Вы можете перейти внутрь этой целевой группы, зажав клавишуCtrlи кликнув по ее названию.
Аналоги Key Collector
Существует несколько программ, схожих с Кей Коллектором по своему функционалу и свойствам, вот перечень некоторых из них:
- SLovoeb — бесплатная копия KC, в которой срисован даже дизайн. Основные отличия заключаются в том, что Слово*б имеет ряд ограничений в плане количества опций. А именно, потенциал программы сопряжен с поисковыми системами Рунета, такими как Яндекс. Прочие настройки и опции почти ничем не отличаются от KC.
- Rush Ananlytics — программа, направленная на сбор аналитических сведений по ключевым словам. С ее помощью вы можете проводить сбор и дальнейшую кластеризацию запросов в группы. Данный сервис интегрирован с Вордстатом, следовательно, он может собирать сведения из WordStat и находить схожие по значению запросы. Затем вы можете группировать ключевые фразы исходя из полученных сведений по выдаче поисковой системы. К тому же с его помощью можно снимать позиции сайта в поисковой выдаче Гугл и Яндекс.
- Мутаген — очень простой и понятный в использовании сервис. С его помощью вы сможете без труда спарсить ключевые фразы для сайта по которым большое количество запросов и почти нет конкуренции. Расчет количества конкурентов происходит исходя из ТОП 30 ресурсов. Численность показов рассчитывается за последние 30 дней. Следовательно, используя данную программу, вы будете располагать актуальными сведениями.
Запуск программы и кластеризация
После запуска программы KeyClusterer пользователю предоставляется область для работы с ключевыми запросами, состоящая из двух панелей, а также набор дополнительных настроек и инструментов для сбора семантики и действий с семантическим ядром.
Для добавления нового проекта необходимо нажать копку «Добавить проект» через меню программы или тулбар, ввести его название, выбрать регион, выбрать число сайтов в поисковой выдаче по которым будет происходить кластеризация и указать домен (опционально).
Пункт «Сбор данных» – это число документов, которое будет получено из поисковой системы Яндекс или Google. В последующем по ним будет производиться группировка запросов. Мы рекомендуем брать первые 10 документов выдачи.
Яндекс
При выборе региона Яндекса имеется возможность быстрого поиска региона по его названию или числовому идентификатору.
В отличие от Яндекса, для которого указывается лишь регион выдачи, для Google необходимо указывать более подробное местоположение:
- домен (google.com, google.ru, google.com.ua…)
- язык (Russian, English, Ukrainian…)
- страна (Russian Federation, United States, Ukraine…)
- место («Moscow,Russia», «New York,United States», «Kyiv city,Ukraine»…)
Например, при указании в поисковой системе Google домена «google.com.ua», поисковик будет производить поиск только в украинском сегменте интернета, а при дополнительном указании региона «Kyiv city,Ukraine», будет получать данные с учетом указанного местоположения.
Добавление запросов
После создания проекта становится возможным добавление поисковых запросов для кластеризации. Добавление запросов возможно 3-мя способами:
- Добавление запросов из буфера обмена.
- Добавление запросов из текстового файла.
- Импорт данных из CSV.
- Импорт данных из Key Collector 4 (*.kc4).
При добавлении запросов через буфер обмена или из текстового файла, все они сначала отобразятся не сгруппированными, так как по ним еще не собраны необходимые данные.
После нажатия кнопки «Собрать данные» происходит сбор данных из ТОП поисковой выдачи Яндекс, после чего становится доступной функция автоматической кластеризации запросов (кнопка «Кластеризовать»).
Импорт данных из CSV / Key Collector
Смысл импорта заключается в загрузке ранее собранных данных по частоте и результатам поисковой выдачи. Это может быть обычный CSV-файл, либо данные, импортированные из программы Key Collector.
После указания имени импортируемого файла программа KeyClusterer сама автоматически попытается определить наличие нужных полей в CSV-файле для импорта данных. При необходимости, можно вручную указать поля из которых будут взяты данные для импорта. Все остальные несопоставленные поля в импортируемом файле будут проигнорированы.
После импорта, запросы будут сгруппированы исходя из текущего содержимого импортируемого файла, после чего их можно будет кластеризовать непосредственно через программу.
Формат CSV-файла импорта:
- Запрос
- Частотность запроса
- URL сайтов выдачи по ТОП
- Группа
- Посадочная страница
- Позиция запроса в ТОП
|
Получение поисковой выдачи в Key Collector
|
Кластеризация
После того, как были собраны все необходимые данные по ключевым фразам, можно переходить к процессу кластеризации (кнопка «Кластеризовать»).
При необходимости, в этом же окне можно скорректировать силу группировки и метод кластеризации и перекластеризовать запросы заново.
После окончания процесса группировки, в левой панели программы KeyClusterer список фраз заменится папками со сгруппированными в них запросами. Названия папок определяются автоматически по одной из ключевых фраз группы (обычно это самая частотная фраза). Запросы, которые не смогли автоматически сгруппироваться с другими фразами по текущим настройкам кластеризации будут находиться в папке под названием «».
Что это может значить на практике?
На практике в теории могут самые разные ситуации.
Могут возникнуть ошибки при взаимодействии программы и сторонних сервисов, в результате которых сервис может потребовать с пользователя средства за предоставления услуг, а в программе из-за сбоя, ошибки, недоработки и непредусмотренной логики данные «потеряются», пользователь не сможет их увидеть или сохранить для ручной обработки.
Если коротко, то деньги могут списать, а результата не будет.
Мы не можем гарантировать 100% корректность при работе со сторонними сервисами. Если вы хотите получить 100% результат, используйте только официальные программные средства и ресурсы сторонних сервисов. Не используйте для этого любые неофициальные программные средства, в том числе Key Collector.
Если сторонние сервисы посчитают, что совершаемые вами запросы могут нанести им какой-либо вред, ущерб, то в целях защиты сервисы могут накладывать самые различные санкции, требования, выражающиеся в блокировках, капче или любых других санкций, требований, предусмотренных законодательством и/или условиями использования и соглашений с такими сервисами.
Если коротко, то могут заблокировать аккаунт, IP-адрес, потребовать плату за обращение к сервису, назначить штрафы, компенсации и т.д.
Если вы хотите гарантировать себе безопасность, строго соблюдайте все условия использования сервисов, заключенных соглашений, законодательство всех причастных к процессу использования таких сервисов стран.
Минусация
Для того, чтобы очистить от ненужных слов собранные поисковые запросы потребуется:
Зайти во вкладку «Данные»
Нажимаем на кнопку «Анализ групп»
Анализ групп в Кей Коллектор
С помощью инструмента анализ групп можно быстро как разгруппировать, так и определить минус слова из собранных ключевых фраз.
Инструмент разбивает полученные ключевые фразы на отдельные слова и объединяет фразы в которых они присутствуют.
Разберем на примере:
Анализ групп в Key Collector
На скриншоте показан анализ групп по натяжным потолкам.
Напротив каждого слова проставлено количество фраз встречаемых с этим словом и суммарная их частотность.
Представим, что в дальнейшем нам потребуется создать кампанию на поиске.
Мы видим, что в верху списка есть слово фото, явно это свидетельствует о том, что человек ищет не рекламный запрос в поиске а именно фотографии с натяжными потолками. Напрямую по этому запросу рекламироваться нет особого смысла, а следовательно фото мы должны отправить к минус словам.
Минус слово в Key Collector
Для этого напротив слова ставим галочку и продолжаем поиск таких слов.
Когда запросов много советую сначала выстроить таблицу по частотности и отметить самые высокочастотные минус слова, дальше сортировать по алфавиту и пробежаться по всему списку, лучше пару раз.
После определения всех минус-слов, нажимаем правой кнопкой мыши по одному из отмеченных и выбираем пункт «Отправить 1-е слово из определений целиком отмеченных групп в окно стоп-слов»
Добавление фразы в окно стоп-слов
В открывшемся окне снимаем галочки с тех слов, которые попали сюда по ошибке. Советую снять галочки со всех слов и заново отметить те слова, которые требуется занести в минусы.
Жмем «Добавить в стоп-слова»
Окно стоп-слов в Кей коллектор
После добавления фраз в стоп-слова сворачиваем анализ групп.
Переходим во вкладку «Сбор данных», затем нажимаем на кнопку перенос фраз в другую группу и выбираем папку корзина.
Добавления фраз в корзину Key collector
Не удаляйте ненужные ключевые фразы, а перемещайте их в корзину, потом всегда можно запарсить новые слова с учетом уже собранных или же слова могут подойти для РСЯ.
Разгруппировка
Заключительным этапом перед экспортом работы в Key Collector будет разгруппировка ключевых фраз.
Для разгруппировки отлично подойдет карта мыслей, которую мы составляли в самом начале.
Легче всего начинать с общих названий услуг.
К примеру:
- Глянцевый
-
Матовый
Многоуровневый
- Тканевый
- Пвх
Дальше разгруппируйте еще более точней
- Глянцевый
- кухня
- ванная
- гостинная
- спальня
- Матовый
- кухня
- ванная
- гостиная
- спальня
И так далее, главное помнить, что в Яндексе статус «Мало показов» распространяется на группу объявлений и появляется при общей частотности группы меньше 20, из этого правила группируйте низкочастотные запросы с небольшим запасом на группу.
Для Google AdWords низкочастотные запросы не подойдут, так как там статус присваивается для ключевого слова, а не группы.
Для начала разгруппировки заходим в «Анализ Групп»
Отмечаем нужное нам слово галочкой и нажимаем правой кнопкой мыши по нему.
Выбираем пункт предпоследний пункт выпадающего меню.
Разгруппировка слов в Key Collector
В нашей группе автоматически создается новая папка с названием слова, которые мы выбрали и все слова, в которых это слово входило перенеслись в эту группу.
После разгруппировки основной группы переходим к тем, которые мы создали и также их дробим на подгруппы.
Таким образом, нам будет проще прописать текст объявлений в будущем.
По такому аналогу и распределяем на группы всё семантическое ядро.
В дальнейшем, названия этих папок будут служить нам как названия групп объявлений как в Директе так и в AdWords.
Первичный сбор частотности ключевых фраз
Вернемся к нашей карте мыслей и нашим пересечениям запросов.
Сейчас требуется скопировать все пересечения и добавить их в key collector.
Для этого создаем новый проект.
Создание проекта в Кей Коллектор
В открывшемся окне переходим во вкладку «Сбор данных» и нажимаем на кнопку «Добавить фразы»
Вставляем полученные фразы при пересечении запросов из карты мыслей.
Жмём кнопку «Добавить в таблицу»
Добавление ключевых фраз в Key Collector
Нажимаем на значок директа (Сбор статистики Яндекс Директ)
В открывшемся окне задаем требуемый регион.
Проверяем наличие галочки в пункте «Целью запуска сбора статистики является заполнение колонок частот Yandex.Wordstat»
И нажимаем получить данные.
Настройки сбора частотности через Яндекс Директ
Первичный сбор статистики производить лучше именнотаким образом, так как этот метод гораздо быстрее, чем сбор статистики с помощью только одного wordstat.
Для увеличения скорости сбора семантического ядра, изначально требуется отбросить заведомо пустые запросы, чтобы лишний раз не обращаться к серверу яндекс вордстат при парсинге, что существенно экономит время.
На скриншоте с Журнала событий Key Collector отчетливо видно, что сбор занял всего минуту при 1 аккаунте. Было проверено 42 слова и большую часть из этого времени заняла авторизация.
Скорость сбора статистики в Кей Коллектор
После сбора статистики в столбце «Базовая частота » появится число отражающие количество запросов в заданном регионе за месяц.
Далее требуется отсечь те слова, у которых по этой статистике 0 запросов.
Для этого их надо отфильтровать, нажимаем на значок воронки (фильтр) рядом с названием столбца.
В открывшемся окне, выбираем условие отображения «Больше» 0.
И нажимаем «Применить».
Настройки фильтра в Key Collector
Перед нами все фразы с частотность больше нуля.
Скопируем их.
Для этого правой клавишей мыши щелкаем по названию столбца и жмем «Скопировать колонку в буфер обмена»
Копирование слов из Key Collector
Готово! Теперь можно перейти к самому важному — Парсингу.
Парсинг запросов
Первым делом создаем новую папку, комбинацией shift+t или нажатием на значок плюса в меню с группами.
Новая папка для парсинга
Для добавления скопированных ранее слов в парсинг, нажимаем на «Пакетный Сбор слов из левой колонки Yandex.Wordstat» (Красный значок статистики).
Проверяем, что не установлено отслеживание повторов.
Парсинг запросов из левой колонки Wordstat
Вставляем слова в открывшееся окно и нажимаем кнопку «Начать сбор»
Парсинг в Key Collector.png
Вот и всё, ждем окончания парсинга и продолжаем работа.
После сбора семантического ядра потребуется разгруппировать и отобрать минус слова.
Как собрать запросы в группы на основе выдачи Google
Чтобы выполнить пакетный сбор для конкретной поисковой системы, необходимо сделать следующее:
- определить конкретный регион и интересующий поисковик;
- собрать KEI для нужной зоны;
- сгруппировать запросы.
Первым делом на верхней панели инструментов надо выбрать кнопку «KEI». В выпадающем списке отметить необходимость получения данных для ПС Google.
После запуска поиска до момента получения результатов может пройти немало времени. К тому же, придется столкнуться с большим количеством капчи. А когда процесс отбора будет завершен, останется собрать запросы в группы. На верхней панели есть кнопка «Анализ групп». После ее активации откроется окно для настроек. Тут нужно задать актуальные параметры.
Есть смысл обратить внимание на пункт «сила связи SERP». Ее показатель можно менять, наблюдая за тем, как система формирует группы после внесенных изменений
Вместо 6 часто используют 4 или 5. Это оптимальные значения. Но окончательный и наиболее эффективный вариант зависит от специфики конкретной задачи.
Готовые группы можно сразу перенести в Excel для удобства пользования ключами. В той же вкладке на верхней панели с правой стороны есть соответствующий значок программы. Кликнув по нему, вы запускаете экспорт. В результате получится информативная таблица.
В целом, работать с Кей Коллектором довольно удобно и просто. К тому же, программа полностью бесплатная. А если рассматривать отзывы ее активных пользователей, то по 10-бальной шкале ПО получает уверенную и твердую 8.
Переименование и цветовая маркировка
Для переименования группы дважды кликните по ее заголовку или воспользуйтесь соответствующим пунктом в контекстном меню.
Для массового редактирования заголовков можно воспользоваться функциями в меню «Формат заголовков» на вкладке «Управление группами».
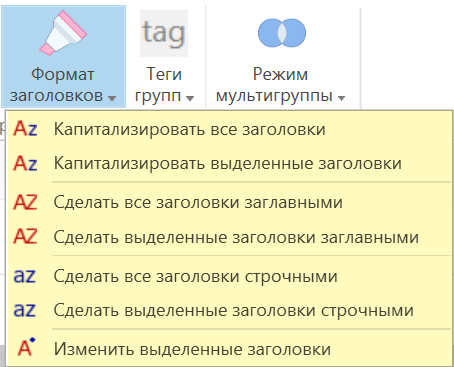
Вы также можете помечать цветами заголовки групп. Для пометки нескольких выделенных групп зажмите клавишу Ctrl.
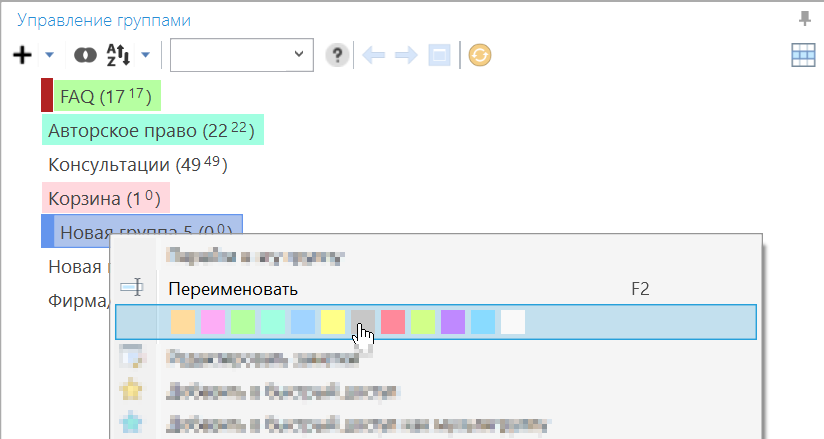
В «Настройках — Интерфейс — Управление группами» можно задать список цветов в формате цветов HTML (HEX ARGB).
Массовое переименование групп по маске
Функция изменения выделенных групп позволяет массово изменить заголовки выделенных групп по заданному пользователем шаблону. Например, можно не только назначить нескольким группам новый единый заголовок, но и сохранить в нем значения прошлых заголовков.
Группы «кастрюли», «сковородки», «чашки» могут быть переименованы в «кастрюли Москва», «сковородки Москва», «чашки Москва» (в существующему заголовку добавлено слово «Москва»). Или же можно выполнить замену части заголовка: «кабель 2.5», «провод 2.5» на «кабель 1.75», «провод 1.75» (выполнена замена 2.5 на 1.75).
Простые замены
Простая замена может использовать в маске макрос {HEADER}, который вставит на место {HEADER} прошлое значение заголовка группы.
Например, маска «купить {HEADER} Москва» превратит группы «носки», «колготки» в «купить носки Москва», «купить колготки Москва».
Слайсинг в стиле numpy
Помимо простой замены с сохранением полного прошлого заголовка иногда требуется модифицировать прошлый заголовок: отрезать какую-то его часть с начали или конца, использовать какую-то информацию из середины и т.п.
Для этих нужд используется широко известный синтаксис слайсинга в numpy (библиотека Python), поэтому если вы его освоите, то это пригодится не только при работе с Key Collector, но и для решения других задач.
Вы можете извлекать наборы символов (подстроки), задавая границы и длину строк с начала или с конца. Приведем несколько примеров.
Отрезать начало строки — {HEADER}N:
Можно указать индекс начала строки N с начала или с конца.
- {HEADER}4: — взять подстроку, начиная с 4-го символа с начала и до конца
- мск интернет —> интернет
- {HEADER}-5: — взять подстроку, начиная с 5-го символа с конца и до конца
-
блин 25 кг
—> 25 кг
Отрезать конец строки — {HEADER}:M
Можно указать индекс конца строки M с начала или с конца.
- {HEADER}:8 — взять подстроку, начиная с начала и до 8-го символа
- интернет мск —> интернет
- {HEADER}:-6 — взять подстроку, начиная с начала и заканчивая 6-м символом с конца
- саженцы москва —> саженцы
Взять из середины строки — {HEADER}N:M
Здесь можно указать индекс начала N и конца M подстроки. Аналогично можно указывать индексацию с начала или с конца строки, но индекс конца M должен быть расположен в абсолютном значении дальше индекса начала N.
- {HEADER}4:6 — взять подстроку, начиная с 4-го символа и заканчивая 6-м символом
- 122.65 частота —> 65
Функции замены
Поддерживается функция замены значения в заголовке на новое значение REPLACE(«old»;»new»). Использовать дополнительную индексацию или маску в параметрах функции не допускается (т.е. в кавычках должны быть заданы обычные слова или части слов.
- REPLACE(«мск»;»спб») — заменить в заголовке «мск» на «спб»
- ворота мск —> ворота спб
Также поддерживается расширенная функция замены по регулярному выражению REPLACERG(«pattern»;»replacement»). Опытные пользователи могут выполнять более сложные замены, используя синтаксис регулярных выражений.
Дополнительно
ТОП сайтов по видимости
Данный список поможет выявить наиболее популярные сайты в вашей тематике (сайты в списке отсортированы по числу запросов, входящих в ТОП-10 по каждому сайту).
Данные для анализа берутся берутся из поисковой выдачи, собранной по каждому запросу, соответственно, для отображения статистики, данные SERP должны изначально присутствовать (должны быть собраны тем или иным способом).
При желании есть возможность выгрузки данных в Excel (CSV-формат).
Работа через прокси
Помимо добавления прокси-серверов есть возможность проверки списка прокси на работоспособность. В остальном, работа через прокси ничем не отличатся от работы в других программах.
Отмена последних действий
Данная функция позволяет отменить последние действия, произведенные при ручной кластеризации запросов.
Будь это перемещение запросов или кластеров, создание групп, переименование или удаление запросов – все это теперь можно отменить и вернуться на тот или иной момент ручной кластеризации без необходимости начинать все сначала.
История запоминает последние 100 действий.
Автосохранение
В программе реализовано автоматическое сохранение данных.
Вы можете быть уверены, что каждый раз при добавлении или удалении проекта, после кластеризации запросов и ручной манипуляции с запросами все данные сохранятся в программе автоматически.
Удаление проекта и сжатие данных
Пункт меню «Сжать базу данных» предназначен для выполнения операции очистки и упаковки имеющихся баз данных (аналог дефрагментации данных на персональных компьютерах).
Данная процедура эффективна в случае, когда например, из программы был удален крупный проект, содержащий большое количество записей. В целом рекомендуется проводить периодическое сжатие данных для избавления от избыточных данных и уменьшения объема базы.
Работа с группировками запросов
Группировка запросов
После того, как запросы были кластеризованы (результат кластеризации будет виден все в той же левой панели программы), вы можете их экспортировать в файлы Excel и CSV формата.
Однако, как известно, какой бы качественной не была автоматическая группировка запросов, она все также будет нуждаться в «ручной» доработке, так как на данный момент, лучше человека понимать тонкости продвижения отдельных запросов и групп искусственный алгоритм еще не научился.
Дополнительно, в ручном режиме есть возможность посредством правой панели создавать произвольные группы любой вложенности и, таким образом, перенося в них кластеры из левой панели, создавать структуру вашего сайта прямо в программе с последующей возможностью экспорта итоговой структуры в Excel и сохранением форматирования относительно вложенности групп запросов.
Помимо переноса фраз, есть возможность удаления запросов, создание и переименование кластеров и групп.
Все эти манипуляции доступны через контекстное меню панелей группировки фраз.
Список стоп-слов
При помощи данного функционала можно выделять ключевые слова в левой или правой панели по определенным правилам и проводить над ними дальнейшие действия: удаление, перемещение и т.п.
Параметры действий при поиске запросов:
- Полное вхождение (ищем «я пил молоко», находим «молоко я пил вчера»).
- Частичное соответствие (ищем «ил моло», находим «я пил молоко»).
- Точное соответствие (ищем «я пил молоко», находим «я пил молоко»).
Это бывает удобно, например, для удаления ключевых слов из семантического ядра по списку стоп-слов, либо для поиска ключевых фраз по вхождению определенного слова, которые затем можно переместить в ту или иную группу.
Сортировка запросов и фильтрация
Отсортировать запросы можно при помощи нажатия на заголовки соответствующих столбцов. При нажатии на колонку «Частотность», запросы будут отсортированы по частоте запроса внутри каждой группы. Аналогично, при нажатии на заголовок колонки с запросами – они будут отсортированы по алфавиту. Группы запросов сортируются через пункт в контекстном меню.
Фильтрация данных позволяет фильтровать запросы по фразам, группам и частоте (если указана).
При фильтрации данных, найденные части слова из первого фильтра выделяются желтым цветом, а из второго – зеленым.
Вывод
Кей Коллектор — это непростой и мультифункциональный инструмент, который не получится освоить за один день при всем желании. Как правило, для углубленного понимания функционала программы и порядка применения опций, пользователи проходят определенные курсы по обучению или тратят несколько недель на изучение всех тонкостей по работе с сервисом.
В основном, данную программу используют в сборе семантики для дальнейшего SEO-продвижения сайта или его страниц, а также, для настройки контекстной рекламы.
Мы постарались дать вам базовые знания по использованию этого парсера на основе простых примеров. Точнее говоря, мы продемонстрировали примерно 15% от всего функционала. Дальше «дело за вами». Но сбор семантики — это непростая работа, требующая существенных затрат времени и сил, поскольку ни один сервис не станет выполнять за вас абсолютно все.
Рассматривая КК, вам придется потратить немало времени на его настройку. Ошибка некоторых людей в том, что первоначально они не удаляют внимания этому и, в результате, имеют неправильно собранное семантическое ядро. Поэтому мы рекомендуем вам не наступать на грабли множества своих предшественников, а потратить чуть больше времени и сил на изучение тонкостей этой программы. Если у вас остались вопросы по прочитанному материалу или вы хотите поделиться своим мнением по данной статье, напишите нам в комментарии, и мы обязательно вам ответим.



