The ultimate guide to the meta robots tag
Содержание:
- Как с помощью расширения обнаружить статьи с мета-тегом?
- Причины для запрета попадания пагинации в индекс
- Types of robots meta directives
- Использование структурированных данных
- Зачем нужен файл robots.txt
- Как еще можно использовать robots.txt?
- Что такое noindex
- Тег
- Что такое nofollow
- How Can I Combine Noindex and Disallow?
- Влияние внутренних ссылок на индексацию сайта
- How to set up the robots meta tag
- Как создать и где разместить robots.txt?
- Какими бывают поисковые роботы?
- SEO benefits of using robots and X-Robots-Tag
- Правила для конкретных поисковых систем
- Support across search engines
Как с помощью расширения обнаружить статьи с мета-тегом?
Значок грустного робота на странице канала
При установленном расширении проверка главной страницы канала производится автоматически. Если канал отмечен как неиндексируемый, то в меню расширения пункт «Неиндексируемые» заменяется значением «Канал не индексируется».
Если в меню расширения в редакторе указано «Канал не индексируется», значит в коде страницы канала присутствует <meta property=»robots» content=»none» />
Ещё раз подчеркну, что наличие этого кода, а значит и соответствующего оповещения в меню — норма для новых каналов.
Значок «грустного робота» на странице публикации
При установленном расширении на странице публикации может отображаться значок грустного робота.
Если в публикации есть такой значок, значит в коде страницы есть <meta name=»robots» content=»noindex» />
Соответственно, для того чтобы его увидеть нужно зайти на страницу публикации. Но зато не нужно изучать исходный код страницы.
Поиск публикаций с мета-тегом
Если вы решите проверить не одну, а десяток публикаций, то придётся заходить в каждую и проверять наличие мета-тега в каждой из них. Вручную это неудобно, поэтому в расширении предусмотрена возможность автоматической проверки.
Для того чтобы начать поиск нужно выбрать пункт меню «Неиндексируемые».
Правда, этот пункт меню будет недоступен, если весь канал отмечен, как неиндексируемый — нет смысла запускать проверку, теги будут обнаружены на всех публикациях.
При первом запуске будет отображено большое страшное предупреждение о том, что процедура поиска производится на страх и риск пользователя.
Дело в том, что стандартной процедуры поиска публикаций с мета-тегом в Дзене не предусмотрено, и расширению приходится буквально открывать каждую проверяемую публикацию и заглядывать в код страницы.
Теоретически это может быть воспринято как DDOS-атака или как попытка накрутить просмотры. На практике с этим проблем не было, но предупредить я вас обязан.
Можно проверить все публикации на канале, а можно проверить лишь 20 последних.
Процедура поиска может занять продолжительное время, по завершении вы получите список публикаций, на которых обнаружен мета-тег.
На моём канале только на одной публикации есть этот мета-тег.
Причины для запрета попадания пагинации в индекс
В случае, если ваш шаблон поддерживает формирования пагинации и для нее не прописан noindex, то она будет формироваться автоматически, без участия админ-панели WordPress. Несмотря на правильную цель, с учетом реализации, попадание таких страниц в выдачу (к примеру Яндекса) только пессимизирует проект. Для коммерции это спровоцирует падение в органике товаров.
Эта ВордПресс рубрика не привносит ничего нового, не добавляет ценности ресурсу, но имеет канонические адреса и содержит много внутренних ссылок с заимствованных из других материалов вырезками.
Говоря про простановку title & description надо знать также и то, что они созданы автоматически и по большей части нечитабельны и содержат кучу ключей и предлогов. В самой системе нельзя запрещать их автоматическое генерирование.
Types of robots meta directives
There are two main types of robots meta directives: the meta robots tag and the x-robots-tag. Any parameter that can be used in a meta robots tag can also be specified in an x-robots-tag.
We’ll talk about both the meta robots and x-robots tag directives below.
Meta robots tag
The meta robots tag, commonly known as «meta robots» or colloquially as a «robots tag,» is part of a web page’s HTML code and appears as code elements within a web page’s section:

Code sample:
<meta name="robots" content="">
While the general tag is standard, you can also provide directives to specific crawlers by replacing the «robots» with the name of a specific user-agent. For example, to target a directive specifically to Googlebot, you’d use the following code:
<meta name="googlebot" content="">
Want to use more than one directive on a page? As long as they’re targeted to the same «robot» (user-agent), multiple directives can be included in one meta directive – just separate them by commas. Here’s an example:
<meta name="robots" content="noimageindex, nofollow, nosnippet">
This tag would tell robots not to index any of the images on a page, follow any of the links, or show a snippet of the page when it appears on a SERP.
If you’re using different meta robots tag directives for different search user-agents, you’ll need to use separate tags for each bot.
Использование структурированных данных
Метатеги robots определяют, какое количество контента Google может автоматически извлекать с веб-страниц и показывать в результатах поиска. Однако многие издатели также применяют структурированные данные schema.org, чтобы показывать в результатах поиска нужную им информацию. Заданные в метатегах robots ограничения не распространяются на структурированные данные, кроме значений и , которые указываются для творческих работ. Чтобы задать максимальную длину текстового фрагмента в результатах поиска с учетом этих значений , используйте метатег robots с директивой . К примеру, если на странице есть структурированные данные для рецептов (), определенный ими контент может показываться в карусели рецептов независимо от ограничения длины текстового фрагмента. Длину текстового фрагмента можно ограничить при помощи , однако эта директива метатега robots не действует, когда информация предоставляется с применением структурированных данных для расширенных результатов.
Вы можете редактировать типы структурированных данных и их значения на веб-страницах. Добавляйте или удаляйте информацию, чтобы роботу Google были доступны только нужные сведения
Обратите внимание, что структурированные данные могут использоваться в Поиске, даже если они объявлены внутри элемента с атрибутом .
Зачем нужен файл robots.txt
Файл robots.txt содержит правила-исключения, а также служебные директивы для поисковых роботов. Правильная настройка позволяет решать основные задачи для корректной индексации сайта:
- закрытие сайта/страниц/файлов,
- указание служебной информации.
Закрытие сайта/страниц/файлов
Полное закрытие веб-проекта чаще всего реализуется в случаях:
- мультирегиональной настройки ПС для поддоменов,
- создания тестового сайта-клона.
Закрытие страниц и файлов сайта реализуется в случаях, когда они:
- дублируют контент,
- содержат служебные данные,
- содержат тестовые данные,
- не несут пользы в индексе ПС.
Указание служебной информации
Ранее, для ПС Яндекс можно было указывать адрес основного хоста (директива host — неактуально), задержку между обращениями бота к сайту (crawl-delay — неактуально). Сегодня достаточно указывать адрес sitemap.xml, директиву host вытеснили канонические адреса.
Как еще можно использовать robots.txt?
Содержимое robots.txt может включать не только список директив для обращения к поисковым системам. Поскольку файл является общедоступным, некоторые компании подходят к его созданию творчески и с юмором. Иногда там можно обнаружить картинку, логотип бренда и даже предложение о работе. Реализация нестандартного robots.txt осуществляется с помощью комментариев # и других символов.
Пользователи, которых заинтересовал robots.txt сайта, вероятнее всего разбираются в оптимизации. Поэтому документ может быть дополнительным способом поиска SEO-специалистов.
На сайте TripAdvisor:
На сайте маркетплейса Esty:
Что такое noindex
«Ноиндекс» – тег и атрибут HTML-страницы. Можно пометить им страницу целиком, придав ей определенные свойства, либо выбрать отдельный участок кода и применить атрибут к нему.
Функция noindex заключается в «сокрытии» контента от поисковых роботов, машин, анализирующих и индексирующих веб-сайты. Они собирают базу данных для поисковых служб и предоставляют пользователям релевантные результаты поиска.
Если какая-то часть контента на странице помечена тегом noindex, то робот ее проигнорирует и в поиске она учтена не будет, что прямо повлияет на SEO-продвижение ресурса, на котором были произведены соответствующие изменения.
На самом деле, робот, конечно же, посмотрит все, что есть на сайте. Просто не будет заносить это в индексную базу.
Какой контент помечается этим тегом?
Любой. В зависимости от помеченной информации и поискового робота тег будет восприниматься по-разному.
Обычно в noindex заворачивают четыре типа текстового контента:
- Информацию с низкой уникальностью, чтобы избежать проблем с антиплагиатом.
- Коды счетчиков (типа метрики и других аналитических систем), ненужные поисковику.
- Контактные данные, номера и ссылки, которые не стоило бы показывать в поисковой выдаче.
- Постоянно меняющийся текст, индексация которого не принесет никакой пользы.
Как использовать тег?
Тег можно вставить в <head> страницы как мету (атрибутом), увеличив область его действия на всю страницу.
С таким кодом индексация страницы разрешается:
<meta name="robots" content="index"/>
А с таким индексация запрещается:
<meta name="robots" content="noindex"/>
Такое правило можно указать для конкретного робота. Например, поискового бота Google:
<meta name="googlebot" content="noindex"/>
Еще один способ — встраивание тегов в текст и оборачивание в него ссылок.
<noindex>кусок текста, который хотелось бы скрыть от индексации поисковиками</noindex>
Правда, такая разметка может нагородить ошибок из-за того, что многие поисковики не понимают тег <noindex> и считают его наличие в тексте ошибкой. Поэтому приходится исползать его вариацию <!–noindex–>. В таком виде роботы, понимающие тег, считывают его без проблем и задают нужные свойства, а непонимающие попросту игнорируют.
Независимо от типа скрываемого контента, принцип остается тем же. Поэтому, если нужно скрыть от индексации код счетчика, ничего специфичного делать не придется. Так же оборачиваем его в <noindex> и все.
Тег
Noindex – тег, с помощью которого можно управлять функцией индексации поискового робота. Если выделить отдельный фрагмент текста и закрыть его тегом noindex, он не будет проиндексирован поисковой системой и, соответственно, не попадет в ее кэш. Впервые данный инструмент был предложен специалистами Яндекса, чтобы у веб-мастеров появился простой способ отделения части текстового контента, которая не несет смысловой нагрузки и не должна учитываться при оценке страницы.
<noindex>Здесь находится закрытый для индексации контент</noindex>
Тег noindex учитывает только Яндекс. Google игнорирует его присутствие и проводит полную индексацию текстового содержания страницы. Для задействования блокировки индексации, актуальной для всех поисковиков, следует прописывать соответствующий метатег для отдельных страниц или всего сайта в файле robots.txt. Недостаток данного способа очевиден: запрет на индексацию возможен только по отношению ко всей странице, но не отдельному текстовому фрагменту.
Преимущества тега noindex
- Сокрытие второстепенной информации позволяет повысить релевантность индексируемой страницы за счет возрастания относительной плотности ключевых фраз.
- С помощью noindex можно спрятать содержимое сквозных блоков, информация в которых будет дублироваться на нескольких страницах, что отразится на пессимизации сайта в поисковой выдаче Yandex.
- В некоторых случаях в сниппет может попасть нежелательная или служебная информация, которую проще всего скрыть тегом noindex.
Принцип действия noindex
Noindex может находиться в любом месте HTML-кода вне зависимости от уровня вложенности.
Несмотря на тот факт, что noindex был изначально предложен разработчиками Yandex, использование данного инструмента может быть расценено в качестве серого метода оптимизации. Это связано с тем, что некоторые веб-мастера применяют его не по прямому назначению. В частности, от робота прячется неуникальный контент или качественный текст, не содержащий ключевых слов, рассчитанный на прочтение посетителем сайта. Одновременно поисковику предлагается насыщенный ключевыми фразами текст, тяжелый для восприятия человека.
Для борьбы с подобными методами оптимизации Yandex анализирует текст, закрытый тегом noindex, проводя его индексацию, но впоследствии отфильтровывая скрытое содержимое. В результате изучения контента страницы поисковик может принять решение о наложении санкций на сайт, если сочтет, что его владелец использует неправомерные способы влияния на результаты поисковой выдачи.
Что такое nofollow
Атрибут, вставляющийся перед ссылками и запрещающий по ним переходить.
Вес страницы — это своего рода уровень авторитетности сайтов, один из факторов, учитываемых при ранжировании страниц в поисковых запросах. Чтобы не передавать вес страницы другим сайтам по размещенным на них ссылкам, данные ссылки оборачивают в тег nofollow.
Какой контент помечается этим атрибутом?
Ссылки. Но не все ссылки, а те, что могут как-то негативно повлиять на вес ресурса. Это касается автоматических ссылок, появляющихся в тех или иных участках сайта. Атрибут nofollow стоило бы приписывать любым внешним ссылкам, за которые вы не можете ручаться. Добавленные на ресурс другими пользователями через секцию комментариев или в графу профиля БИО.
Как прописывать тег?
С таким тегом индексирование страницы разрешается, но запрещается переход по всем ссылкам:
<meta name="robots" content="nofollow"/>
Как и в случае с <noindex>, правило можно задать для конкретного поискового робота:
<meta name="googlebot" content="nofollow"/>
Если мы говорим о конкретных ссылках, то переход на них можно запретить прямо внутри разметки.
<a href=“page.html” rel=“nofollow”>Гиперссылка</a>
How Can I Combine Noindex and Disallow?
Noindex (page) + Disallow: Disallow can’t be combined with noindex on the page, because the page is blocked and therefore search engines won’t crawl it to know that they’re not supposed to leave the page out of the index.
Noindex (robots.txt) + Disallow: This prevents pages appearing in the index, and also prevents the pages being crawled. However, remember that no PageRank can pass through this page.
To combine a disallow with a noindex in your robots.txt, simply add both directives to your robots.txt file:
Disallow: /example-page-1/
Disallow: /example-page-2/
Noindex: /example-page-1/
Noindex: /example-page-2/
Влияние внутренних ссылок на индексацию сайта
Внутренние ссылки являются основной и практически единственной причиной того, что нам приходится закрывать ненужные и попавшие в индекс страницы разными метатегами и директивами robots.txt. Однако реальность такова, что ненужные роботам страницы очень даже нужны пользователям сайта, а следовательно должны быть и ссылки на эти самые страницы.
А что же делать? При любом варианте запрета индексации ссылок (rel=”nofollow”) и страниц (robots.txt, meta robots), вес сайта просто теряется, утекает на закрытые страницы.
Вариант №1. Большинство распространенных CMS имеют возможность использования специальных тегов (в DLE точно это есть, я сам этим очень активно пользуюсь) при создании шаблонов оформления, которые позволяют регулировать вывод определенной информации. Например, показывать какой-либо текст только гостям или группе пользователей с определенным id и т.д. Если таких тегов вдруг нет, то наверняка на помощь придут логические конструкции (такие конструкции есть в WordPress, а так же форумных движках IPB и vbulletin, опять же, я сам пользуюсь этими возможностями), представляющие из себя простейшие условные алгоритмы на php.
Так вот, логично было бы скрывать неважные и ненужные ссылки от гостей (обычно эту роль играют и роботы при посещении любого сайта), а так же скрывать ссылки на страницы, которые выдают сообщение о том, что вы не зарегистрированы, не имеете прав доступа и все такое. При необходимости можно специально для гостей выводить блок с информацией о том, что после регистрации у них появится больше прав и возможностей, а значит и соответствующие ссылки появятся 😉
Но бывают такие моменты, что ссылку нельзя скрыть или удалить, потому что она нужна, и нужна сразу всем – гостям, пользователям… А вот роботам не нужна. Что делать?
Вариант №2. В редких случаях (хотя последнее время все чаще и чаще) бывает необходимо, чтобы ссылки или даже целые блоки сайта были недоступны и невидны роботам, а вот людям отображались и работали в полной мере, вне зависимости от групп и привилегий. Вы уже, наверное, догадались, что я говорю про сокрытие контента при помощи JavaScript или AJAX. Как это делается технически, я не буду расписывать, это очень долго. Но есть замечательный пост Димы Dimox’а о том, как загрузить часть контента с помощью AJAX на примере WordPress (линк). В примере рассказывается про подгрузку целого сайдбара, но таким же методом можно подгрузить одну только ссылку, например. В общем, немного покопаетесь и разберетесь.
Так вот, если хочется какую-то часть контента роботам не показывать, то лучший выбор – JavaScript. А после того как провернете всю техническую часть, проверить это на работоспособность поможет замечательный плагин для FireFox под названием QuickJava. Просто с помощью плагина отключите для браузера обработку яваскрипта и перезагрузите страницу, весь динамически подгружаемый контент должен пропасть 😉 Но помните, что тут тоже надо знать меру!
И, кстати, еще парочка интересных моментов, которые необходимо знать:
Яндексу в индексации сайтов помогает Яндекс.Метрика, которая автоматически пингует в индекс все посещенные страницы, на которых установлен код Метрики. Но эту функцию можно отключить при получении кода счетчика, установив соответсвующую галочку.
Возможно как то в индексации замешаны Яндекс.Бар и сборка браузера Хром от Яндекса, но в этом я не уверен.
Но вот для Гугла есть информация, что роль поискового робота выполняет сам браузер Google Chrome. Такие уж они хитрецы.
Так что, как видим, скрыть информацию от роботов почти невозможно, если не предпринимать специальные меры.
How to set up the robots meta tag
Now that you know what all these directives do and look like, it’s time to get to the actual implementation on your website.
Robots meta tags belong into the section of a page. It’s pretty straightforward if you edit the code using HTML editors such as Notepad++ or Brackets. But what if you’re using a CMS with SEO plugins?
Let’s focus on the most popular option out there.
Go to the “Advanced” section below the editing block of each post or page. Set up the robots meta tag according to your needs. The following settings would implement “noindex, nofollow” directives.
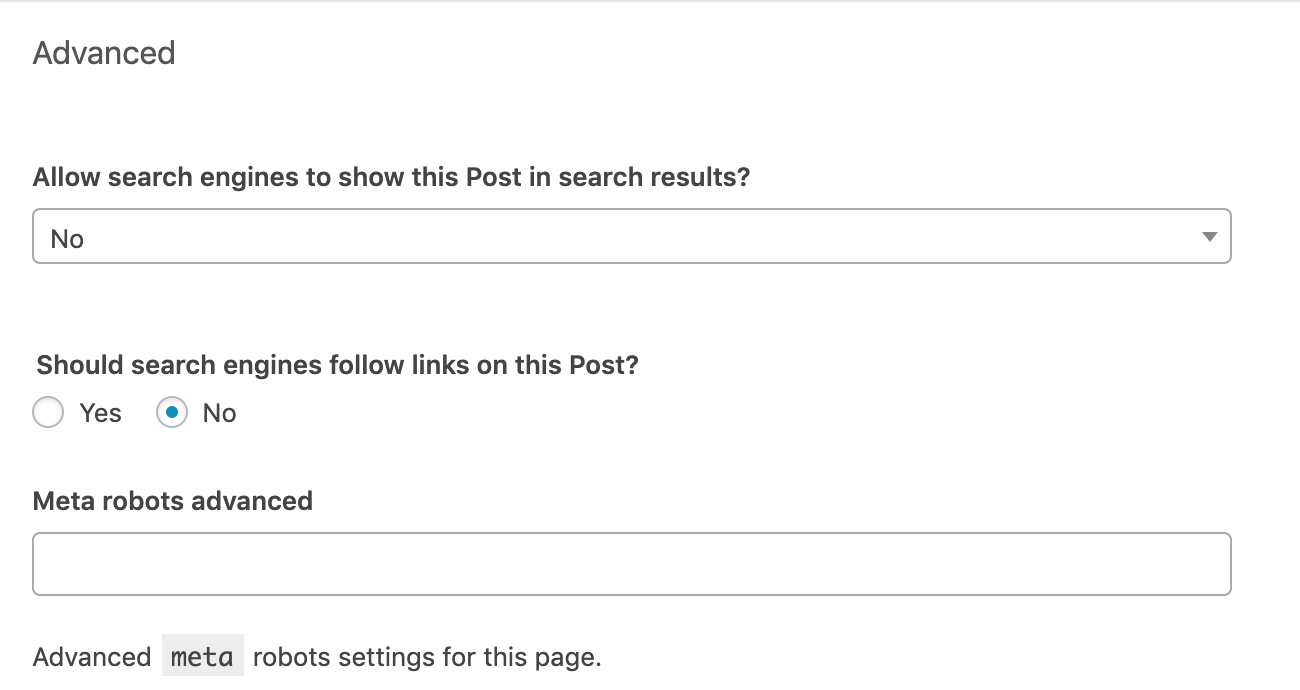
The “Meta robots advanced” row gives you the option to implement directives other than noindex and nofollow, such as noimageindex.
You also have the option to apply these directives sitewide. Go to “Search Appearance” in the Yoast menu. There you can set up meta robots tags on all posts, pages, or just on specific taxonomies or archives.
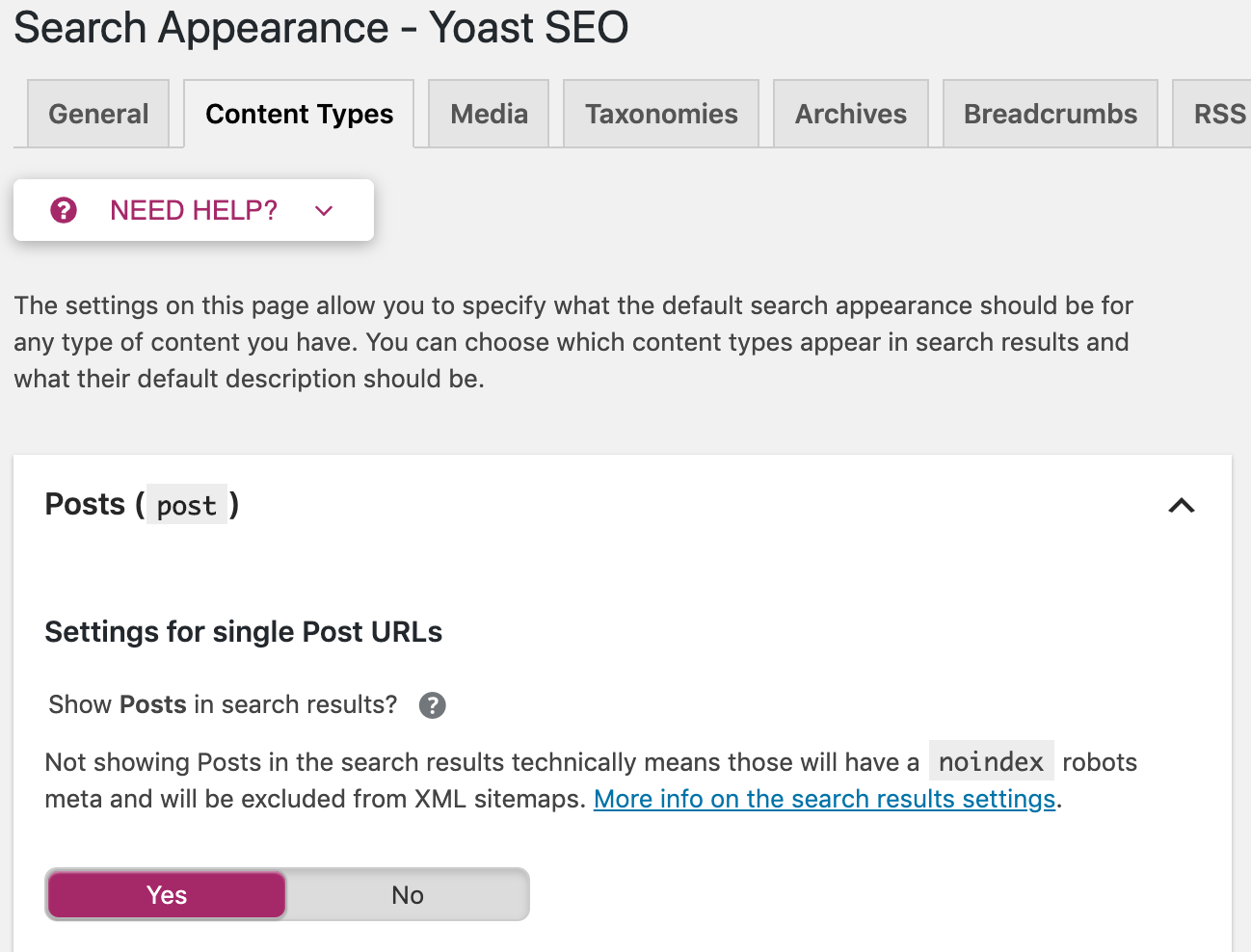
Sidenote. Yoast isn’t the only way to control meta robots tags in WordPress. There are plenty of other WordPress SEO plugins with similar functionality.
Как создать и где разместить robots.txt?
Инструменты для настройки robots txt
Поскольку документ имеет расширение .txt, для его создания подойдет любой текстовый редактор с поддержкой кодировки UTF-8. Самый простой вариант — Блокнот (Windows) или TextEdit (Mac).
Также можно использовать генератор robots.txt. Некоторые сайты предоставляют бесплатные инструменты создания на основании заданных вами условий.
Название и размер документа
Имя файла robots.txt должно выглядеть именно так, без использования заглавных букв. Допустимый размер документа согласно рекомендациям и Яндекса — 500 КиБ. При превышении лимита робот может обработать документ частично, воспринять как полный запрет сканирования или, наоборот, пройтись по всему содержимому ресурса.
Где разместить файл
Документ находится в корневом каталоге на хостинге и доступ к нему возможен через FTP. Перед внесением изменений рекомендуется сначала скачать robots.txt в исходном виде.
Какими бывают поисковые роботы?
Поисковой робот — это специальная программа, которая сканирует страницы ресурса и заносит их в базу данных поисковой системы. В Google и Яндексе есть несколько ботов, которые отвечают за разные типы контента.
Виды роботов Google
- Googlebot: бот для сканирования сайтов для ПК и мобильный устройств
- Googlebot Image: отвечает за показ изображений сайта в разделе «Картинки»
- Googlebot Video: отвечает за сканирование и отображение видео
- Googlebot News: отбирает самые полезные и качественные статьи для раздела «Новости»
- AdSense: оценивает сайт как рекламную платформу с точки зрения релевантности объявлениям
Полный список роботов Google (агентов пользователей) перечислен в официальной Справке.
Виды роботов Яндекс
- YandexBot: основной робот, отвечающий за сканирование страниц ресурсов
- YandexImages: сканирует изображения
- YandexNews: влияет за наполнение раздела Яндекс.Новости.
- MirrorDetector: робот, определяющий зеркала сайтов
- YandexDirect: робот рекламной сети, анализирующий тематику ресурса
Кроме поисковых роботов сайт могут сканировать краулеры аналитических ресурсов, например, Ahrefs или Screaming Frog. Их программное обеспечение работает по тому же принципу, что и поисковик — парсинг URL для занесения в собственную базу.
Боты, от которых сайт следует закрыть:
- вредоносные парсеры (спам-боты, собирающие адреса электронной почты клиентов, вирусы, DoS- и DDoS-атаки и другие);
- боты других компаний, мониторящих информацию с целью дальнейшего использования в своих целях (цены, контент, SEO-методы и т.д.).
Если вы примите решения закрыть сайт от указанных выше роботов, лучше использовать не robots.txt, а файл .htaccess. Второй способ надежнее, так как он ограничивает доступ не в качестве рекомендации, а на уровне сервера.
Команду нужно указывать внизу файла .htaccess. Запрет сканирования для каждого робота должен быть указан в отдельной строке.
Если же все-таки решите использовать robots.txt, укажите в нем всех названия всех в таком формате:
User-agent:
Disallow: /
Таким образом вы ограничите доступ роботов ко всем страницам сайта.
В конце статьи вы найдете со списком роботов, которым вы возможно хотели бы ограничить доступ к своему сайту, чтобы они не собирали информацию о вашем ресурсе. Список не исчерпывающий — вы можете добавить в него других ботов.
Решение блокировать определенного бота и нет рекомендуем принимать исходя из ваших индивидуальных потребностей. Например, если вы пользуетесь каким-то сервисом, конечно же, вам стоит дать его боту возможность сканировать ваш сайт.
SEO benefits of using robots and X-Robots-Tag
Let’s examine how the robots meta tag and the X-Robots-Tag help in search engine optimization and when you should use them.
1. Choosing what pages to index
Not all website pages can attract organic visitors. If indexed, some of them might actually harm the site’s search visibility. These are the types of pages that are usually blocked from indexing with the help of noindex:
- duplicated pages
- sorting options and filters
- search and pagination pages
- technical pages
- service notifications (about a sign up process, completed order, etc.)
- landing pages designed for testing ideas
- pages that are in progress of development
- information that isn’t up-to-date yet (future deals, announcements, etc.)
- outdated pages that don’t bring any traffic
- pages you need to block from certain search crawlers
3. Keeping the link juice
Blocking links from crawlers with the help of nofollow, you can keep the page’s link juice because it won’t be passed to other sources though external or internal links.
4. Optimizing the crawl budget
The bigger a site is, the more important it is to direct crawlers to the most valuable pages. If search engines crawl a website inside and out, the crawl budget will simply end before bots reach the content helpful for users and SEO. This way, important pages won’t get indexed or will get to the index behind the desired schedule.
Правила для конкретных поисковых систем
Иногда вам может потребоваться предоставить конкретные инструкции для конкретной поисковой системы, исключая других роботов. Или вы можете составить совершенно разные инструкции для разных поисковых систем.
В этих случаях вы можете изменить значение content атрибута для конкретной поисковой системы (например, googlebot для Google или yandex для Яндекс).
Примечание. Учитывая, что поисковые системы будут просто игнорировать инструкции, которые они не поддерживают или не понимают, очень редко нужно использовать несколько тегов мета-роботов для установки инструкций для определенных сканеров.
Support across search engines
It’s not just the interpretation of conflicting robots directives that can differ per search engine. The directives supported and the support for their delivery method (HTML or HTTP Header) can vary too. If a cell in the table below has a green checkmark (), both HTML and HTTP header implementations are supported. If there’s a red cross (), none are supported. If only one is supported, it’s explained.
| Directive | Bing/Yahoo | Yandex | |
|---|---|---|---|
| all | Only meta robots | ||
| index | Only meta robots | ||
| follow | Only meta robots | ||
| noindex | |||
| nofollow | |||
| none | |||
| noarchive | |||
| nosnippet | |||
| max-snippet |
And now, on to the less important ones:
| Directive | Bing/Yahoo | Yandex | |
|---|---|---|---|
| unavailable_after | |||
| noimageindex | |||
| max-image-preview | |||
| max-video-preview | |||
| notranslate |