Сортировка массива методом пузырька — алгоритм и задачи
Содержание:
- Пример работы алгоритма[править]
- Пузырьковая сортировка и её улучшения
- Динамическое выделение памяти[править]
- Программа упорядочения строк в алфавитном порядке[править]
- Программа упорядочения строк в алфавитном порядке
- Функция qsort из библиотеки stdlib[править]
- Модификации[править]
- В чём хитрость сортировки расчёской
- Внешние ссылки [ править ]
- Используйте [ редактировать ]
- Простые сортировки
- Анализ [ править ]
- Варианты алгоритма
Пример работы алгоритма[править]
Возьмём массив и отсортируем значения по возрастанию, используя сортировку пузырьком. Выделены те элементы, которые сравниваются на данном этапе.
Первый проход:
| До | После | Описание шага |
|---|---|---|
| 5 1 4 2 8 | 1 5 4 2 8 | Здесь алгоритм сравнивает два первых элемента и меняет их местами. |
| 1 5 4 2 8 | 1 4 5 2 8 | Меняет местами, так как 5 > 4 |
| 1 4 5 2 8 | 1 4 2 5 8 | Меняет местами, так как 5 > 2 |
| 1 4 2 5 8 | 1 4 2 5 8 | Теперь, ввиду того, что элементы стоят на своих местах (8 > 5), алгоритм не меняет их местами. |
Второй проход:
| До | После | Описание шага |
|---|---|---|
| 1 4 2 5 8 | 1 4 2 5 8 | |
| 1 4 2 5 8 | 1 2 4 5 8 | Меняет местами, так как 4 > 2 |
| 1 2 4 5 8 | 1 2 4 5 8 | |
| 1 2 4 5 8 | 1 2 4 5 8 |
Теперь массив полностью отсортирован, но неоптимизированный алгоритм проведет еще два прохода, на которых ничего не изменится, в отличие от алгоритма, использующего вторую оптимизацию, который сделает один проход и прекратит свою работу, так как не сделает за этот проход ни одного обмена.
Пузырьковая сортировка и её улучшения
Сортировка пузырьком

Сортировка пузырьком — один из самых известных алгоритмов сортировки. Здесь нужно последовательно сравнивать значения соседних элементов и менять числа местами, если предыдущее оказывается больше последующего. Таким образом элементы с большими значениями оказываются в конце списка, а с меньшими остаются в начале.
Этот алгоритм считается учебным и почти не применяется на практике из-за низкой эффективности: он медленно работает на тестах, в которых маленькие элементы (их называют «черепахами») стоят в конце массива. Однако на нём основаны многие другие методы, например, шейкерная сортировка и сортировка расчёской.
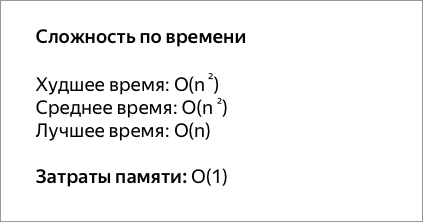
void BubbleSort(vector<int>& values) {
for (size_t idx_i = 0; idx_i + 1 < values.size(); ++idx_i) {
for (size_t idx_j = 0; idx_j + 1 < values.size() - idx_i; ++idx_j) {
if (values < values) {
swap(values, values);
}
}
}
}
Сортировка перемешиванием (шейкерная сортировка)
Шейкерная сортировка отличается от пузырьковой тем, что она двунаправленная: алгоритм перемещается не строго слева направо, а сначала слева направо, затем справа налево.
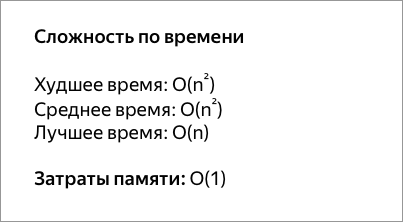
void ShakerSort(vector<int>& values) {
if (values.empty()) {
return;
}
int left = 0;
int right = values.size() - 1;
while (left <= right) {
for (int i = right; i > left; --i) {
if (values > values) {
swap(values, values);
}
}
++left;
for (int i = left; i < right; ++i) {
if (values > values) {
swap(values, values);
}
}
--right;
}
}
Сортировка расчёской
Сортировка расчёской — улучшение сортировки пузырьком. Её идея состоит в том, чтобы «устранить» элементы с небольшими значения в конце массива, которые замедляют работу алгоритма. Если при пузырьковой и шейкерной сортировках при переборе массива сравниваются соседние элементы, то при «расчёсывании» сначала берётся достаточно большое расстояние между сравниваемыми значениями, а потом оно сужается вплоть до минимального.
Первоначальный разрыв нужно выбирать не случайным образом, а с учётом специальной величины — фактора уменьшения, оптимальное значение которого равно 1,247. Сначала расстояние между элементами будет равняться размеру массива, поделённому на 1,247; на каждом последующем шаге расстояние будет снова делиться на фактор уменьшения — и так до окончания работы алгоритма.

void CombSort(vector<int>& values) {
const double factor = 1.247; // Фактор уменьшения
double step = values.size() - 1;
while (step >= 1) {
for (int i = 0; i + step < values.size(); ++i) {
if (values > values) {
swap(values, values);
}
}
step /= factor;
}
// сортировка пузырьком
for (size_t idx_i = 0; idx_i + 1 < values.size(); ++idx_i) {
for (size_t idx_j = 0; idx_j + 1 < values.size() - idx_i; ++idx_j) {
if (values < values) {
swap(values, values);
}
}
}
}
Динамическое выделение памяти[править]
Ниже приведена программа, где память под массив выделяется динамически:
#include<stdio.h>
#include<stdlib.h>
#include<malloc.h>
intcmp(constvoid*a,constvoid*b){
return*(int*)a-*(int*)b;
}
intmain(){
intn,i;
int*a;
scanf("%d",&n);
a=(int*)malloc(sizeof(int)*n);
for(i=;i<n;i++){
scanf("%d",&ai]);
}
qsort(a,n,sizeof(int),cmp);
for(i=;i<n;i++){
printf("%d ",ai]);
}
free(a);
return;
}
Функция malloc (от англ. memory allocation — выделение памяти) делает запрос к ядру операционной системы по выделению заданного количества байт. Единственный аргумент этой функции — число байт, которое вам нужно. В качестве результата функция возвращает указатель на начало выделенной памяти. Указатель на начало выделенной памяти &mbsah — это адрес ячейки памяти, начиная с которого идут N байт, которые вы можете использовать под любые свои нужды. Всю память, которая была выделена с помощью функции malloc, нужно освобождать с помощью функции free. Аргумент функции free — это указатель на начало выделенной когда-то памяти.
Программа упорядочения строк в алфавитном порядке[править]
#include<stdlib.h>
#include<string.h>
#include<stdio.h>
#define N 100
#define M 30
intmain(intargc,char*argv[]){
charaN];
intn,i;
scanf("%d",&n);
for(i=;i<n;i++)
scanf("%s",&ai]);
qsort(a,n,sizeof(charM]),(int(*)(constvoid*,constvoid*))strcmp);
for(i=;i<n;i++)
printf("%s\n",ai]);
return;
}
Обратите внимание на сложное приведение типов.
Функция strcmp, объявленная в файле string.h имеет следующий прототип:
int strcmp(const char*, const char*);
То есть функция получает два аргумента — указатели на кусочки памяти, где хранятся элементы типа char,
то есть два массива символов, которые не могут быть изменены внутри функции strcmp (запрет на изменение задается с помощью модификатора const).
В то же время в качестве четвертого элемента функция qsort хотела бы иметь функцию типа
int cmp(const void*, const void*);
В языке Си можно осуществлять приведение типов являющихся типами функции. В данном примере тип
int (*)(const char*, const char*); // функция, получающая два элемента типа 'const char *' и возвращающая элемент типа 'int'
приводится к типу
int (*)(const void*, const void*); // функция, получающая два элемента типа 'const void *' и возвращающая элемент типа 'int'
Программа упорядочения строк в алфавитном порядке
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
#define N 100
#define M 30
int main(int argc, char* argv[]) {
char a;
int n, i;
scanf("%d", &n);
for (i=0; i<n; i++)
scanf("%s", &a);
qsort(a, n, sizeof(char), (int (*)(const void *,const void *)) strcmp);
for (i=0; i<n; i++)
printf("%s\n", a);
return 0;
}
Обратите внимание на сложное приведение типов. Функция strcmp, объявленная в файле string.h имеет следующий прототип:
Функция strcmp, объявленная в файле string.h имеет следующий прототип:
int strcmp(const char*, const char*);
То есть функция получает два аргумента — указатели на кусочки памяти, где хранятся элементы типа char, то есть два массива символов, которые не могут быть изменены внутри функции strcmp (запрет на изменение задается с помощью модификатора const).
В то же время в качестве четвертого элемента функция qsort хотела бы иметь функцию типа
int cmp(const void*, const void*);
В языке Си можно осуществлять приведение типов являющихся типами функции. В данном примере тип
int (*)(const char*, const char*); // функция, получающая два элемента типа 'const char *' и возвращающая элемент типа 'int'
приводится к типу
int (*)(const void*, const void*); // функция, получающая два элемента типа 'const void *' и возвращающая элемент типа 'int'
Функция qsort из библиотеки stdlib[править]
Два оператора for, в которых происходит сортировка, можно заменить на одну строку:
qsort(a,n,sizeof(int),cmp);
Это функция, описанная в стандартной библиотеке ANSI C и объявлена в заголовочном файле stdlib.h.
Поэтому в начале программы нужно добавить
#include<stdlib.h>
Функцией можно упорядочивать объекты любой природы. По сути, она предназначена упорядочивать множества блоков байтов равной длины.
Второй аргумент функции — это число таких блоков, третий аргумент — длина каждого блока.
Первый аргумент — это адрес, где находится начало первого блока (предполагается, что блоки в памяти расположены друг за другом подряд).
Четвёртый аргумент функции qsort — это имя функции, которая умеет сравнивать
два элемента массива. В нашем случае это
intcmp(constvoid*a,constvoid*b){
return*(int*)a-*(int*)b;
}
В силу указанной универсальности функции сортировки, функция сравнения получает в качества аргумента адреса двух блоков, которые нужно сравнить и возвращает 1, 0 или -1:
- положительное значение, если a > b
- 0, если a == b
- отрицательное значение, если a < b
Поскольку у нас блоки байт — это целые числа (в 32-битной архитектуре это четырёхбайтовые блоки), то
необходимо привести данные указатели типа (const void*) к типу (int *) и осуществляется это с помощью дописывания
перед указателем выражения «(const int*)». Затем нужно получить значение переменной типа int, которая лежит по этому адресу.
Это делается с помощью дописывания спереди звездочки.
Таким образом, мы получили следующую программу
#include<stdio.h>
#include<stdlib.h>
#define N 1000
intcmp(constvoid*a,constvoid*b){
return*(int*)a-*(int*)b;
}
intmain(){
intn,i,j;
intaN];
scanf("%d",&n);
for(i=;i<n;i++){// ЧИТАЕМ ВХОД
scanf("%d",&ai]);
}
qsort(a,n,sizeof(int),cmp);// СОРТИРУЕМ
for(i=;i<n;i++){// ВЫВОДИМ РЕЗУЛЬТАТ
printf("%d ",ai]);
}
return;
}
Модификации[править]
Сортировка чет-нечетправить
Сортировка чет-нечет (англ. odd-even sort) — модификация пузырьковой сортировки, основанная на сравнении элементов стоящих на четных и нечетных позициях независимо друг от друга. Сложность — .
Псевдокод указан ниже:
function oddEvenSort(a):
for i = 0 to n - 1
if i mod 2 == 0
for j = 2 to n - 1 step 2
if a < a
swap(a, a)
else
for j = 1 to n - 1 step 2
if a < a
swap(a, a)
Преимущество этой сортировки — на нескольких процессорах она выполняется быстрее, так как четные и нечетные индексы сортируются параллельно.
Сортировка расческойправить
Сортировка расческой (англ. comb sort) — модификация пузырьковой сортировки, основанной на сравнении элементов на расстоянии. Сложность — , но стремится к . Является самой быстрой квадратичной сортировкой. Недостаток — она неустойчива. Псевдокод указан ниже:
function combSort(a):
k = 1.3
jump = n
bool swapped = true
while jump > 1 and swapped
if jump > 1
jump /= k
swapped = false
for i = 0 to size - jump - 1
if a < a
swap(a, a)
swapped = true
Пояснения: Изначально расстояние между сравниваемыми элементами равно , где — оптимальное число для этого алгоритма. Сортируем массив по этому расстоянию, потом уменьшаем его по этому же правилу. Когда расстояние между сравниваемыми элементами достигает единицы, массив досортировывается обычным пузырьком.
Сортировка перемешиваниемправить
Сортировка перемешиванием (англ. cocktail sort), также известная как Шейкерная сортировка — разновидность пузырьковой сортировки, сортирующая массив в двух направлениях на каждой итерации. В среднем, сортировка перемешиванием работает в два раза быстрее пузырька. Сложность — , но стремится она к , где — максимальное расстояние элемента в неотсортированном массиве от его позиции в отсортированном массиве. Псевдокод указан ниже:
function shakerSort(a):
begin = -1
end = n - 2
while swapped
swapped = false
begin++
for i = begin to end
if a > a
swap(a, a)
swapped = true
if !swapped
break
swapped = false
end--
for i = end downto begin
if a > a
swap(a, a)
swapped = true
В чём хитрость сортировки расчёской
Раз у нас большие элементы могут тормозить весь процесс, то можно их перекидывать не на соседнее место, а подальше. Так мы уменьшим количество перестановок, а с ними сэкономим и процессорное время, нужное на их обработку.
Но отправлять каждый большой элемент сразу в конец массива будет недальновидно — мы же не знаем, насколько этот элемент большой по сравнению с остальными элементами. Поэтому в сортировке расчёской сравниваются элементы, которые отстоят друг от друга на каком-то расстоянии. Оно не слишком большое, чтобы сильно не откидывать элементы и возвращать потом большинство назад, но и не слишком маленькое, чтобы можно было отправлять не на соседнее место, а чуть дальше.
Опытным путём программисты установили оптимальное расстояние между элементами — это длина массива, поделённая на 1,247 (понятное дело, расстояние нужно округлить до целого числа). С этим числом алгоритм работает быстрее всего.
Внешние ссылки [ править ]
| В Викибука есть страница по теме: |
| Викискладе есть медиафайлы по теме . |
| В Викиверситете есть учебные ресурсы о |
- Мартин, Дэвид Р. (2007). . Архивировано из на 2015-03-03. — графическая демонстрация
- . (Анимация Java-апплета)
- OEIS
| vтеАлгоритмы сортировки | |
|---|---|
| Теория |
|
| Обменные сорта |
|
| Выборочные сорта |
|
| Вставки |
|
| Сортировка слияния |
|
| Виды распространения |
|
| Параллельные сортировки |
|
| Гибридные сорта |
|
| Другой |
|
Используйте [ редактировать ]
Пузырьковая сортировка — алгоритм сортировки, который непрерывно просматривает список, меняя местами элементы, пока они не появятся в правильном порядке. Список был построен в декартовой системе координат, где каждая точка ( x , y ) указывает, что значение y хранится в индексе x . Затем список будет отсортирован пузырьковой сортировкой по значению каждого пикселя
Обратите внимание, что сначала сортируется самый большой конец, а меньшим элементам требуется больше времени, чтобы переместиться в правильное положение.
Хотя пузырьковая сортировка является одним из простейших алгоритмов сортировки для понимания и реализации, ее сложность O ( n 2 ) означает, что ее эффективность резко снижается в списках из более чем небольшого числа элементов. Даже среди простых алгоритмов сортировки O ( n 2 ) такие алгоритмы, как сортировка вставкой , обычно значительно более эффективны.
Из-за своей простоты пузырьковая сортировка часто используется для ознакомления с концепцией алгоритма или алгоритма сортировки для начинающих студентов- информатиков . Тем не менее, некоторые исследователи, такие как Оуэн Астрахан , пошли на многое, чтобы осудить пузырьковую сортировку и ее неизменную популярность в образовании по информатике, рекомендуя даже не преподавать ее.
Жаргон Файл , который лихо звонков bogosort «архетипический извращенно ужасный алгоритм», также вызывает пузырьковую сортировку «общий плохой алгоритм». Дональд Кнут в книге «Искусство компьютерного программирования» пришел к выводу, что «пузырьковая сортировка, похоже, не имеет ничего, что могло бы ее рекомендовать, кроме броского названия и того факта, что она приводит к некоторым интересным теоретическим проблемам», некоторые из которых он затем обсуждает. .
Пузырьковая сортировка асимптотически эквивалентна по времени работы сортировке вставкой в худшем случае, но эти два алгоритма сильно различаются по количеству необходимых перестановок. Экспериментальные результаты, такие как результаты Astrachan, также показали, что сортировка вставкой работает значительно лучше даже в случайных списках. По этим причинам многие современные учебники алгоритмов избегают использования алгоритма пузырьковой сортировки в пользу сортировки вставкой.
Пузырьковая сортировка также плохо взаимодействует с современным аппаратным обеспечением ЦП. Он производит как минимум вдвое больше записей, чем сортировка вставкой, вдвое больше промахов в кеш и асимптотически больше ошибочных прогнозов переходов . [ необходима цитата ] Эксперименты по сортировке строк Astrachan в Java показывают, что пузырьковая сортировка примерно в пять раз быстрее сортировки вставкой и на 70% быстрее сортировки по выбору .
В компьютерной графике пузырьковая сортировка популярна благодаря своей способности обнаруживать очень маленькие ошибки (например, перестановку всего двух элементов) в почти отсортированных массивах и исправлять их с линейной сложностью (2 n ). Например, он используется в алгоритме заполнения многоугольника, где ограничивающие линии сортируются по их координате x в определенной строке сканирования (линия, параллельная оси x ), а с увеличением y их порядок изменяется (два элемента меняются местами) только при пересечения двух линий. Пузырьковая сортировка — это стабильный алгоритм сортировки, как и сортировка вставкой.
Простые сортировки
Сортировка вставками

При сортировке вставками массив постепенно перебирается слева направо. При этом каждый последующий элемент размещается так, чтобы он оказался между ближайшими элементами с минимальным и максимальным значением.

void InsertionSort(vector<int>& values) {
for (size_t i = 1; i < values.size(); ++i) {
int x = values;
size_t j = i;
while (j > 0 && values > x) {
values = values;
--j;
}
values = x;
}
}
Сортировка выбором
Сначала нужно рассмотреть подмножество массива и найти в нём максимум (или минимум). Затем выбранное значение меняют местами со значением первого неотсортированного элемента. Этот шаг нужно повторять до тех пор, пока в массиве не закончатся неотсортированные подмассивы.
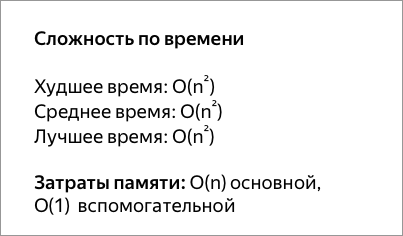
void SelectionSort(vector<int>& values) {
for (auto i = values.begin(); i != values.end(); ++i) {
auto j = std::min_element(i, values.end());
swap(*i, *j);
}
}
Эффективные сортировки
Быстрая сортировка
Этот алгоритм состоит из трёх шагов. Сначала из массива нужно выбрать один элемент — его обычно называют опорным. Затем другие элементы в массиве перераспределяют так, чтобы элементы меньше опорного оказались до него, а большие или равные — после. А дальше рекурсивно применяют первые два шага к подмассивам справа и слева от опорного значения.
Быструю сортировку изобрели в 1960 году для машинного перевода: тогда словари хранились на магнитных лентах, а сортировка слов обрабатываемого текста позволяла получить переводы за один прогон ленты, без перемотки назад.

int Partition(vector<int>& values, int l, int r) {
int x = values;
int less = l;
for (int i = l; i < r; ++i) {
if (values <= x) {
swap(values, values);
++less;
}
}
swap(values, values);
return less;
}
void QuickSortImpl(vector<int>& values, int l, int r) {
if (l < r) {
int q = Partition(values, l, r);
QuickSortImpl(values, l, q - 1);
QuickSortImpl(values, q + 1, r);
}
}
void QuickSort(vector<int>& values) {
if (!values.empty()) {
QuickSortImpl(values, 0, values.size() - 1);
}
}
Сортировка слиянием

Сортировка слиянием пригодится для таких структур данных, в которых доступ к элементам осуществляется последовательно (например, для потоков). Здесь массив разбивается на две примерно равные части и каждая из них сортируется по отдельности. Затем два отсортированных подмассива сливаются в один.

void MergeSortImpl(vector<int>& values, vector<int>& buffer, int l, int r) {
if (l < r) {
int m = (l + r) / 2;
MergeSortImpl(values, buffer, l, m);
MergeSortImpl(values, buffer, m + 1, r);
int k = l;
for (int i = l, j = m + 1; i <= m || j <= r; ) {
if (j > r || (i <= m && values < values)) {
buffer = values;
++i;
} else {
buffer = values;
++j;
}
++k;
}
for (int i = l; i <= r; ++i) {
values = buffer;
}
}
}
void MergeSort(vector<int>& values) {
if (!values.empty()) {
vector<int> buffer(values.size());
MergeSortImpl(values, buffer, 0, values.size() - 1);
}
}
Пирамидальная сортировка
При этой сортировке сначала строится пирамида из элементов исходного массива. Пирамида (или двоичная куча) — это способ представления элементов, при котором от каждого узла может отходить не больше двух ответвлений. А значение в родительском узле должно быть больше значений в его двух дочерних узлах.

Пирамидальная сортировка похожа на сортировку выбором, где мы сначала ищем максимальный элемент, а затем помещаем его в конец. Дальше нужно рекурсивно повторять ту же операцию для оставшихся элементов.

void HeapSort(vector<int>& values) {
std::make_heap(values.begin(), values.end());
for (auto i = values.end(); i != values.begin(); --i) {
std::pop_heap(values.begin(), i);
}
}
Ещё больше интересного — в соцсетях Академии
Анализ [ править ]
Пример пузырьковой сортировки. Начиная с начала списка, сравните каждую соседнюю пару, поменяйте их местами, если они не в правильном порядке (последняя меньше первой). После каждой итерации необходимо сравнивать на один элемент меньше (последний), пока не останется больше элементов для сравнения.
Производительность
Пузырьковая сортировка имеет наихудший случай и среднюю сложность О ( n 2 ), где n — количество сортируемых элементов. Большинство практических алгоритмов сортировки имеют существенно лучшую сложность в худшем случае или в среднем, часто O ( n log n ). Даже другое О ( п 2 ) алгоритмы сортировки, такие как вставки рода , как правило , не работать быстрее , чем пузырьковой сортировки, а не более сложным. Следовательно, пузырьковая сортировка не является практическим алгоритмом сортировки.
Единственное существенное преимущество пузырьковой сортировки перед большинством других алгоритмов, даже быстрой сортировкой , но не сортировкой вставкой , заключается в том, что в алгоритм встроена способность определять, что список сортируется эффективно. Когда список уже отсортирован (в лучшем случае), сложность пузырьковой сортировки составляет всего O ( n ). Напротив, большинство других алгоритмов, даже с лучшей средней сложностью , выполняют весь процесс сортировки на множестве и, следовательно, являются более сложными. Однако сортировка вставкой не только разделяет это преимущество, но также лучше работает со списком, который существенно отсортирован (с небольшим количеством инверсий).). Кроме того, если такое поведение желательно, его можно тривиально добавить к любому другому алгоритму, проверив список перед запуском алгоритма.
В случае больших коллекций следует избегать пузырьковой сортировки. Это не будет эффективно в случае коллекции с обратным порядком.
Кролики и черепахи
Расстояние и направление, в котором элементы должны перемещаться во время сортировки, определяют производительность пузырьковой сортировки, поскольку элементы перемещаются в разных направлениях с разной скоростью. Элемент, который должен двигаться к концу списка, может перемещаться быстро, потому что он может принимать участие в последовательных заменах. Например, самый большой элемент в списке будет выигрывать при каждом обмене, поэтому он перемещается в свою отсортированную позицию на первом проходе, даже если он начинается с начала. С другой стороны, элемент, который должен двигаться к началу списка, не может двигаться быстрее, чем один шаг за проход, поэтому элементы перемещаются к началу очень медленно. Если наименьший элемент находится в конце списка, он займет n −1проходит, чтобы переместить его в начало. Это привело к тому, что эти типы элементов были названы кроликами и черепахами соответственно в честь персонажей басни Эзопа о Черепахе и Зайце .
Были предприняты различные попытки уничтожить черепах, чтобы повысить скорость сортировки пузырей. Сортировка коктейлей — это двунаправленная сортировка пузырьков, которая идет от начала до конца, а затем меняет свое направление, идя от конца к началу. Он может довольно хорошо перемещать черепах, но сохраняет сложность наихудшего случая O (n 2 ) . Комбинированная сортировка сравнивает элементы, разделенные большими промежутками, и может очень быстро перемещать черепах, прежде чем переходить к все меньшим и меньшим промежуткам для сглаживания списка. Его средняя скорость сопоставима с более быстрыми алгоритмами вроде быстрой сортировки .
Пошаговый пример
Возьмите массив чисел «5 1 4 2 8» и отсортируйте его от наименьшего числа к наибольшему, используя пузырьковую сортировку. На каждом этапе сравниваются элементы, выделенные жирным шрифтом . Потребуется три прохода;
- Первый проход
- ( 5 1 4 2 8) → ( 1 5 4 2 8). Здесь алгоритм сравнивает первые два элемента и меняет местами, поскольку 5> 1.
- (1 5 4 2 8) → (1 4 5 2 8), поменять местами, поскольку 5> 4
- (1 4 5 2 8) → (1 4 2 5 8), поменять местами, поскольку 5> 2
- (1 4 2 5 8 ) → (1 4 2 5 8 ). Теперь, поскольку эти элементы уже упорядочены (8> 5), алгоритм не меняет их местами.
- Второй проход
- ( 1 4 2 5 8) → ( 1 4 2 5 8)
- (1 4 2 5 8) → (1 2 4 5 8), поменять местами, поскольку 4> 2
- (1 2 4 5 8) → (1 2 4 5 8)
- (1 2 4 5 8 ) → (1 2 4 5 8 )
Теперь массив уже отсортирован, но алгоритм не знает, завершился ли он. Алгоритм нужен один весь проход без какой — либо свопа знать сортируется.
- Третий проход
- ( 1 2 4 5 8) → ( 1 2 4 5 8)
- (1 2 4 5 8) → (1 2 4 5 8)
- (1 2 4 5 8) → (1 2 4 5 8)
- (1 2 4 5 8 ) → (1 2 4 5 8 )
Варианты алгоритма
Сорт коктейлей
Производной пузырьковой сортировки является сортировка коктейлей или шейкерная сортировка. Этот метод сортировки основан на следующем наблюдении: при пузырьковой сортировке элементы могут быстро перемещаться в конец массива, но перемещаются в начало массива только по одной позиции за раз.
Идея сортировки коктейлей состоит в чередовании направления маршрута. Получается несколько более быстрая сортировка, с одной стороны, потому что она требует меньшего количества сравнений, с другой стороны, потому что она перечитывает самые последние данные при изменении направления (поэтому они все еще находятся в кэш-памяти ). Однако количество обменов, которые необходимо произвести, идентично (см. Выше). Таким образом, время выполнения всегда пропорционально n 2 и, следовательно, посредственно.
Три прыжка вниз
Код для этой сортировки очень похож на пузырьковую сортировку. Подобно пузырьковой сортировке, при этой сортировке первыми отображаются самые крупные элементы. Однако это не работает с соседними элементами; он сравнивает каждый элемент массива с тем, который находится на месте большего, и обменивается, когда находит новый, больший.
tri_jump_down(Tableau T)
pour i allant de taille de T - 1 à 1
pour j allant de 0 à i - 1
si T < T
échanger(T, T)
Сортировка combsort
Вариант пузырьковой сортировки, называемый гребенчатой сортировкой ( combsort ), был разработан в 1980 году Влодзимежем Добосевичем и вновь появился в апреле 1991 года в журнале Byte Magazine . Он исправляет главный недостаток пузырьковой сортировки, которой являются «черепахи», и делает алгоритм столь же эффективным, как и быстрая сортировка .


