Как озвучить книгу при помощи speechkit api yandex.cloud
Содержание:
- Installation
- Звоним из «1С». Универсальный софтфон для стандартных конфигураций «1С» с открытым кодом для платформ 8.2, 8.3 для Asterisk и не только.
- Вопросы
- Подсистема «Показатели объектов»
- Как подключаться к сервисам Яндекса
- Достоинства
- Бесплатный перевод текстов в звук
- Регистрация в «Облаке»
- Синтез речи с Yandex SpeechKit на Python
- Работа с файлами телефонных звонков
- Как масштабироваться при больших количествах звонков
- Навигатор по конфигурации базы 1С 8.3 Промо
- Знакомство с API Yandex SpeechKit
- Faster — многофункциональный ускоритель работы программиста 1С и других языков программирования Промо
Installation
There are several ways to add SpeechKit to a project.
Installing with CocoaPods
$ gem install cocoapods
Podfile
To integrate SpeechKit into your project using CocoaPods, create a file in the project directory:
source 'https://github.com/CocoaPods/Specs.git' platform :ios, '8.0' target 'TargetName' do pod 'YandexSpeechKit', '~> 3.12.2' end
Then run the command:
$ pod install
Adding SpeechKit directly
You can add SpeechKit directly to a project as a static library, without using a dependency manager.
In the Xcode project settings, choose -> , then click -> and choose SpeechKit. Also add all the frameworks and libraries required by SpeechKit in the same section. For a complete list, see .
In -> , add the bundle with the resources, which is located in the directory.
In -> -> , set the path to the directory that contains SpeechKit.
Звоним из «1С». Универсальный софтфон для стандартных конфигураций «1С» с открытым кодом для платформ 8.2, 8.3 для Asterisk и не только.
Уважаемые господа, представляю Вашему вниманию внешнюю обработку — софтфон для стандартных конфигураций «1С» с открытым кодом. Это две реализации с претензией на универсальность для обычных и управляемых приложений. Универсальность имеет свои минусы (на них укажу позже, если кто сам не увидит), которые легко «побеждаются» интеграцией в необходимую конфигурацию с внесением в последнюю соответствующих небольших изменений. Хотя, и с минусами, как мне кажется, как-то можно жить. Мне не удалось найти оператора или PBX, с которыми звонилка не работала бы (разве что Skipe) . Некоторые коллеги почему-то отдельно отмечали факт успешного взаимодействия с Mango, хотя, по правде сказать, я не очень понимаю, почему могут возникать сложности с этим оператором при использовании других инструментов. Вообще, этап тестирования был очень сжатым, и могу предположить, что будет найдено, какое-то количество негативных моментов (всегда хочется, чтобы их было немного.)., которые надо будет поправить. Буду рад любым вашим замечаниям и благодарен за здравую критику. Я думаю, что для нее в данном случае будет достаточно места. Этап тестирования, хоть и был сжатым, но все же был. Прежде всего, проверил на Asterisk, мне это показалось наиболее актуальным. MasterTel любезно предоставил для тестирования свои ресурсы, включая городской номер, Callobok.ru создал для меня экаунт на своем сервере, четвертым был провайдер sipnet. Во всех четырех случаях был положительный результат, больше нигде проверять не стал, т.к. все используют один и тот же протокол (кроме skype). Ах, ну да! Конечно же, на собственном сервере проверял, похоже тоже «жужжит».
Что касается конфигураций, проверил работоспособность обычного приложения на «Бухгалтерии предприятия 2.0», «Управление торговлей 10.3», «Комплексная автоматизация», «Розница 1.0», управляемое приложение — «Управление торговлей 11», «Бухгалтерия предприятия 3.0», «Управление небольшой фирмой 1.4» (1.5 тоже должна работать), «Розница 2.0».
4 стартмани
Вопросы
-
Почему вы используете консольные команды, а не REST-запросы по API?
-
В первых версиях этой обработки я использовал запросы напрямую из 1С. Но поскольку при распознавании коротких аудиозаписей мне приходилось запускать базу 1С в несколько потоков, четыре базы 1С, запущенные на одном компьютере, существенно съедали память. Из-за этого и перешли на Curl.
-
Разве у вас файловая база? В клиент-серверной базе можно пользоваться фоновыми заданиями, сделать REST-запрос на сервере. Такая возможность есть очень давно. У меня тоже используется подобное решение, правда для других целей – стартует несколько фоновых потоков, каждый из которых что-то выполняет. В вашем случае это дало бы очень сильный выигрыш.
-
Как вы решаете случаи, когда одно слово отправлено в разных кусках – будет ли оно распознано?
-
У нас есть исходная расшифровка и есть расшифровка менеджера, который приводит исходную расшифровку в более читаемый текстовый вид, потому что все равно исходное распознавание получается не стопроцентное – аналоговая АТС вносит свои коррективы. Например, при проверке онлайн-распознавания на сайте Яндекса, слова, сказанные в микрофон с ноутбука, распознаются лучше, чем загруженные из файла телефонного разговора, записанного через обычный аналоговый аппарат АТС. Соответственно, менеджеру приходится исправлять за Яндексом ошибки. Так эта проблема и решается.
-
Сколько времени заняла реализация проекта и какое количество суммарно сотрудников менеджеров телефонных звонков у такая статическая информация о понять масштабы?
-
Я на слайде приводил статистику – с 2017 года было обработано 118 тысяч звонков. У нас работает где-то 45 менеджеров, в месяц они наговаривают 5 гигабайт этих телефонных разговоров. Такое количество звуковой информации можно спокойно распознать в четырех потоках. Яндекс предоставляет 20 потоков, соответственно, еще есть куда расти.
-
Когда вы конвертируете wav-файлы в OggOpus, вы не пробовали играться, на каком битрейте уже распознавание хуже?
-
Я пробовал менять частоту дискретизации. Соответственно, сейчас он по умолчанию там на 11000 0,25 герц я пробовал увеличить в два раза до 22000. Размер файла увеличился в два раза, стоимость распознавания увеличилась, но качество не очень увеличилась. Скажу по опыту, что легче поставить хорошие телефонные аппараты, убрать фоновое звучание музыки – сделать тихий кабинет. Тогда все распознается идеально. Допустим, когда распознается автоответчик, что-то наговаривает, то когда Яндекс пытается это преобразовать в текст все идеально получается. Когда менеджер комкает слова либо быстро говорит – соответственно, возможны проблемы. То есть легче поменять оборудование и просить менеджеров следить за четким произнесением ключевых слов. Например, еси нужно, чтобы зафиксировалась слово «Заказ», то они должны четко сказать «Заказ», тогда это слово точно отделится пробелами от всех остальных слов и можно будет делать по нему поиск.
-
Что делать с переадресацией звонков на мобильный, звонки с мобильных, в WhatsApp и так далее? Или у вас все только через корпоративную АТС и других вариантов нет?
-
Если в компании используется мобильная телефония, то лучше перейти на цифровые АТС, например, на MANGO. Нашими силами это не решить – если звонок ушел с АТС, SPRecord его не запишет, и он не будет расшифрован.
*************
Данная статья написана по итогам доклада (видео), прочитанного на INFOSTART MEETUP Saint Petersburg.Online. Больше статей можно прочитать здесь.
Подсистема «Показатели объектов»
Если вашим пользователям нужно вывести в динамический список разные показатели, которые нельзя напрямую получить из таблиц ссылочных объектов, и вы не хотите изменять структуру справочников или документов — тогда эта подсистема для вас. С помощью нее вы сможете в пользовательском режиме создать свой показатель, который будет рассчитываться по формуле или с помощью запроса. Этот показатель вы сможете вывести в динамический список, как любую другую характеристику объекта. Также можно будет настроить отбор или условное оформление с использованием созданного показателя.
2 стартмани
Как подключаться к сервисам Яндекса

В Яндекс.Облаке очень много сервисов, я в своей работе использовал только два:
-
Yandex Object Storage – для хранения звуковых файлов;
-
Yandex SpeechKit – для преобразования звука в текст.
Вначале, в 2017 году, Yandex Object Storage был не нужен, мы использовали Yandex SpeechKit напрямую – отправляешь wav-файл, ждешь в режиме онлайн и получаешь в текстовом виде расшифровку.

Переходим к Яндекс.Облаку.
Чтобы работать с Облаком, нужно установить тоже командный интерфейс Curl, нужно зарегистрироваться и пройти авторизацию.
Сейчас я более подробно расскажу про каждый из пунктов.

Вначале ставим Curl – это кроссплатформенная служебная программа командной строки.
Ничего сложного тут нет – просто заходим по гиперссылке https://cloud.yandex.ru/docs/cli/quickstart, скачиваем и устанавливаем.
Это нам дает возможность прямо из 1С в командной строке вызывать системные функции для работы с Яндекс.Облаком.

Далее мы:
-
Регистрируемся, получаем имя пользователя и пароль
-
В 2017 году этого было достаточно, чтобы начать работать. Сейчас, чтобы начать распознавать аудио-звонки, нам нужно создать платежный аккаунт и закинуть туда определенную сумму денег – бесплатного распознавания уже нету.
-
Далее мы создаем сервисный аккаунт, это связано с безопасностью – с каталогами Яндекс.Облака нельзя работать под общим аккаунтом, там для каждого объекта создается свой сервисный аккаунт и ему назначаются нужные права конкретно на эти объекты. В принципе, это правильно, но это немного усложнило работу.

Когда мы зарегистрировались, получаем OAuth-токен.
Как было показано предыдущих слайдах, мы установили Curl, и с его помощью запускаем команду yc init, которая привязывает профиль CLI на данном компьютере к Облаку.
В этой команде мы задаем, куда привязать профиль:
-
к какому облаку;
-
к какому каталогу;
-
и в какой зоне доступности будут происходить наши вычисления – у Яндекса на данный момент есть три зоны доступности (Владимирская, Рязанская и Московская область), где происходит расшифровка звонков.
После того как мы получили OAuth-токен, мы в принципе можем начать работать.
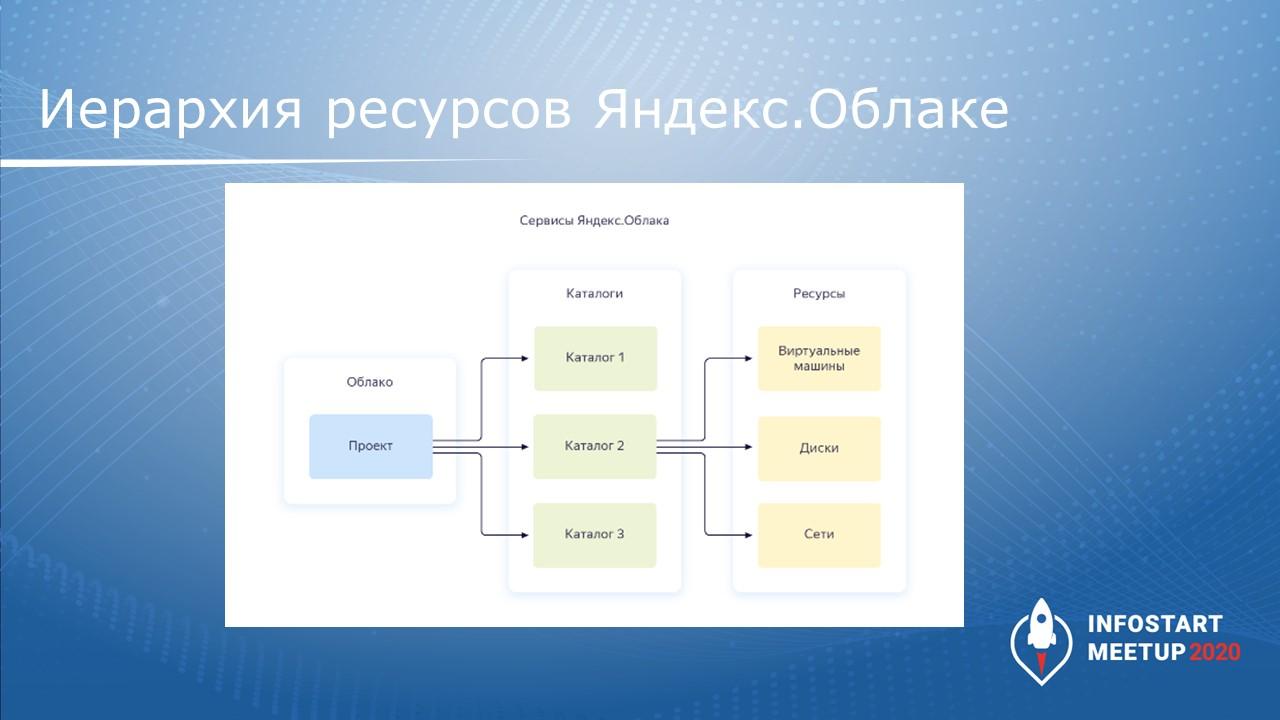
На данном слайде показано, для чего нужно создавать сервисный аккаунт – сервисному аккаунту мы назначаем права на использование ресурсов и каталогов.
У Яндекса есть ограничение – с одного компьютера можно запускать не более 20 потоков.
Поскольку я укладывался во все лимиты Яндекс.Облака, у меня было:
-
одно облако;
-
один каталог;
-
и два ресурса – расшифровка звонков и хранение в Yandex Object Storage.
Если если вам нужна более масштабная расшифровка звонков, то необходимо поднимать, допустим, две виртуальных машины и на них на Яндексе регистрировать два облака – это позволит масштабироваться.

Итак, мы зарегистрировались, получили OAuth-токен, теперь нужно получить IAM-токен.
IAM-токен имеет ограниченное время жизни – не более 12 часов. Соответственно, 2 раза в сутки он меняется. Поэтому если он нужен при работе, допустим, в 1С, его можно получить программно вызовом команды
yc iam create-token > » + IAMtoken
Достоинства
Во вложении обработка Yandex speech в которой реализована функция проверки новых звуковых wav файлов в каталоге SpRecord , подгрузка их в 1С, далее получение доп. информации о длительности и номерах из SpRecord и далее нарезка файлов по 55 секунд и распознавание их в Yandex SpeechKit Cloud.
В обработке нужно:
— заполнить идентификатор каталога Yandex SpeechKit Cloud
— заполнить идентификатор OAuth
— путь к каталогу SOX.
— в каталог SOX установить дополнительно opusenc и cURL
— В функции ПолучитьМенеджера необходимо задать соответствие номера линии SpRecord и номера телефона менеджера.
— КаталогСФайлами путь к звуковым файлам разговоров программы SpRecord.
— СтрокаСоединения задать свои параметры подключения к SQl серверу
Бесплатный перевод текстов в звук
Как уже упоминалось, лучшие бесплатные синтезаторы речи – Гугл и Яндекс. Но можно встретить и другие достойные сервисы.
как озвучить текст
Чем выделяется:
- качественная, эмоционально окрашенная речь;
- выбор диктора;
- возможность создания списка озвучки;
- коррекция ударений;
- коррекция пауз;
- возможность сохранения звукового файла.
Запускать синтезатор речи лучше в Хроме, иначе может не получиться скачивание файла.
Кстати, возможность сохранения результатов озвучивания текста имеется даже не у всех платных сервисов. Для скачивания файла нужно нажать на значок настройки справа от линейки.
сохранение звукового файла
Недостатки:
- кошмарный дизайн;
- избыток рекламы;
- платный заказ озвучки больших текстов.
Этот сервис использует технологию TTS Яндекса, но настройки сделаны неплохо. Пранкеры бывают довольны.
Из зарубежных бесплатных онлайн синтезаторов речи нужно отметить Oddcast, который предоставляет прикольный интерфейс виртуальных дикторов и позволяет менять голос и скорость озвучки. Правда, качество текста на русском оставляет желать лучшего.
Онлайн озвучка текста на русском
Онлайн озвучка записанного текста на русском с помощью синтезаторов речи продолжает развиваться, так что качество компьютерной обработки звука будет расти с каждым годом.
Регистрация в «Облаке»
Для этого нам понадобится Яндекс-аккаунт: заведите новый, если его у вас нет, или войдите в него под своим логином.
Если аккаунт уже есть — переходим на страницу сервиса cloud.yandex.ru и нажимаем «Подключиться»:
На следующем шаге подтверждаем согласие с условиями, и мы у цели:
На главной странице «Облака» активируем пробный период, чтобы бесплатно использовать все возможности сервиса, в том числе и SpeechKit:
Единственное, что нам осталось из формальностей, — заполнить данные о себе и привязать банковскую карту. С неё спишут два рубля и сразу вернут их, чтобы убедиться, что карта активна. Она нужна для того, чтобы пользоваться сервисами после окончания пробного периода. Если вам это будет не нужно — просто удалите карту, когда закончите проект.
Когда подключите карту — нажмите «Активировать».
Когда всё будет готово, вы попадёте на главную страницу сервиса, где увидите что-то подобное:
Вместо статуса Active вы увидите статус «Пробный период» и баланс в 3000 ₽ без кредитного лимита.
Синтез речи с Yandex SpeechKit на Python
Ниже исходники кода из видео. В исходниках нет токенов и нет SOX, но посмотрите видео и поймете что нужно ещё сделать чтобы код заработал:
Python
import os
import subprocess
import time
from creds import token, folder_id
import requests
root_path = os.path.dirname(__file__)
target_path = ‘c:\\_tmp\\_speechkit\\’
«»»
Протухает через 12 часов не использования
yc iam create-token >> /home/web/token.txt
Кусок текста меньше 5000 симв
https://cloud.yandex.ru/docs/speechkit/tts/request#wav
https://cloud.yandex.ru/docs/speechkit/tts/request
https://cloud.yandex.ru/docs/speechkit/api-ref/grpc/tts_service
«»»
def synthesize(text):
url = ‘https://tts.api.cloud.yandex.net/speech/v1/tts:synthesize’
headers = {‘Authorization’: ‘Bearer ‘ + token,}
data = {
‘folderId’: folder_id,
‘text’: text,
‘lang’: ‘ru-RU’,
# ‘voice’:’alena’, # премиум — жрет в 10 раз больше денег
‘voice’:’jane’, # oksana
’emotion’:’evil’,
‘speed’:’1.1′,
# по умолчанию конвертит в oggopus, кот никто не понимает, зато занимат мало места
‘format’: ‘lpcm’,
‘sampleRateHertz’: 48000,
}
with requests.post(url, headers=headers, data=data, stream=True) as resp:
if resp.status_code != 200:
raise RuntimeError(«Invalid response received: code: %d, message: %s» % (resp.status_code, resp.text))
for chunk in resp.iter_content(chunk_size=None):
yield chunk
def write_file(text):
«»»
Пишет чанки в вайл
:param text:
:return:
«»»
filename = str(int(time.time()))
with open(target_path + filename + «.raw», «wb») as f:
for audio_content in synthesize(text):
f.write(audio_content)
time.sleep(2)
return filename
def convert(filename):
«»»
Для конверсии в wav
:param filename:
:return:
«»»
# собираю команду конвертации
cmd = » «.join()
# выполняю команду конвертации
subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.STDOUT, universal_newlines=True)
def read_text():
«»»
Читаю текстовый файл
:return:
«»»
with open(«text.txt», «r», encoding=»UTF-8″) as f:
text = f.read()
return text
convert(write_file(read_text()))
|
1 |
importos importsubprocess importtime fromcreds importtoken,folder_id importrequests root_path=os.path.dirname(__file__) target_path=’c:\\_tmp\\_speechkit\\’ defsynthesize(text) url=’https://tts.api.cloud.yandex.net/speech/v1/tts:synthesize’ headers={‘Authorization»Bearer ‘+token,} data={ ‘folderId’folder_id, ‘text’text, ‘lang»ru-RU’, # ‘voice’:’alena’, # премиум — жрет в 10 раз больше денег ‘voice»jane’,# oksana ’emotion»evil’, ‘speed»1.1’, # по умолчанию конвертит в oggopus, кот никто не понимает, зато занимат мало места ‘format»lpcm’, ‘sampleRateHertz’48000, } withrequests.post(url,headers=headers,data=data,stream=True)asresp ifresp.status_code!=200 raiseRuntimeError(«Invalid response received: code: %d, message: %s»%(resp.status_code,resp.text)) forchunkinresp.iter_content(chunk_size=None) yieldchunk defwrite_file(text) «»» Пишет чанки в вайл filename=str(int(time.time())) withopen(target_path+filename+».raw»,»wb»)asf foraudio_content insynthesize(text) f.write(audio_content) time.sleep(2) returnfilename defconvert(filename) «»» Для конверсии в wav # собираю команду конвертации cmd=» «.join( root_path+»\sox\sox.exe», «-r 48000 -b 16 -e signed-integer -c 1», target_path+filename+».raw», target_path+filename+».wav», ) # выполняю команду конвертации subprocess.Popen(cmd,stdout=subprocess.PIPE,stderr=subprocess.STDOUT,universal_newlines=True) defread_text() «»» Читаю текстовый файл withopen(«text.txt»,»r»,encoding=»UTF-8″)asf text=f.read() returntext convert(write_file(read_text())) |
Работа с файлами телефонных звонков
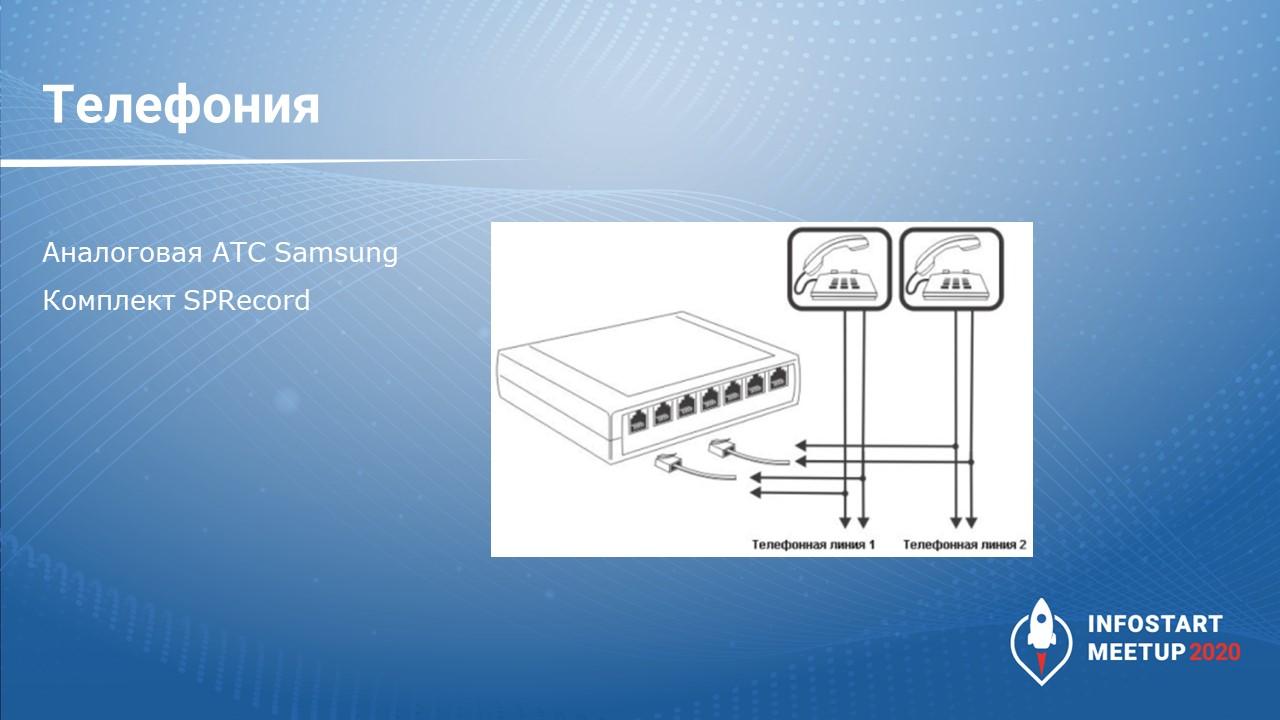
Какая ситуация с телефонией у нас была на предприятии:
-
У нас аналоговая АТС – аналоговые линии.
-
Дополнительно мы докупили комплекты SPRecord – можно перейти на сайт SPRecord, посмотреть, что это за устройство. Оно вешается параллельно аналоговой линии, записывает разговор и преобразует его в цифру – все звуковые файлы у него хранятся в формате *.wav без сжатия.
Соответственно, то, о чем я рассказываю, подходит для старых телефонных сетей. В новых цифровых сетях это уже решается гораздо проще – например, у MANGO есть отдельный сервис расшифровки телефонных звонков и отправка их на на почту.
Итак, у нас на фирме была аналоговая АТС, и все звонки записывались в формате *.wav.
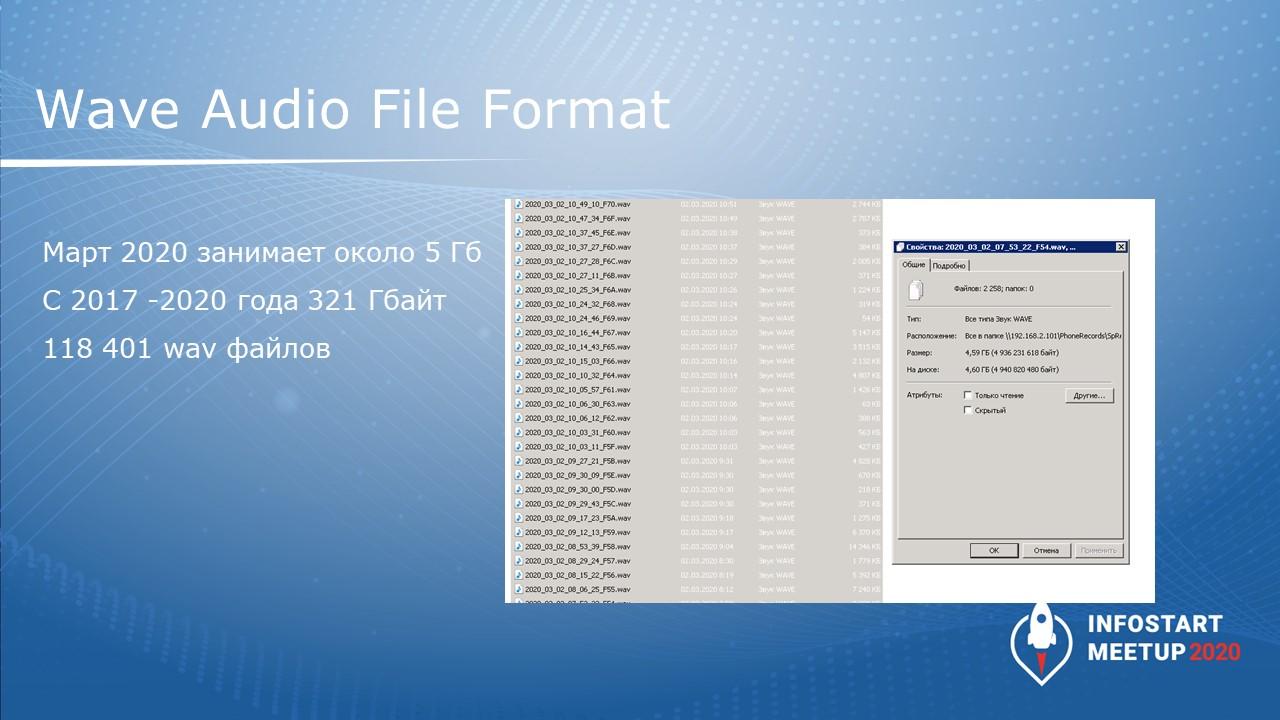
Начинали мы это делать еще в 2017 году, и за это время по текущую дату записано 118 тысяч звонков.
Объем файлов за месяц занимает примерно 5 гигабайт (по данным марта 2020 года).

Что нужно сделать, чтобы как-то обработать эти файлы? Я использовал бесплатную кросс-платформенную утилиту Sox Sound eXchange. Она вызывается из командной строки и с ее помощью можно прямо из 1С выполнить следующие действия:
-
получить длительность аудио – по команде
sox —i -d input.wav > output.txt -
поменять дискретизацию – по команде
sox —i -r » input.wav > output.txt -
обрезать файл – по команде
sox input.wav output.wav trim 20
Обрезку я использовал для исходящих звонков, где у нас обычно 20 секунд занимает дозвон – эти 20 секунд можно спокойно обрезать, чтобы сэкономить на расшифровке звонка.
У Яндекса расшифровка кратна 15 секундам, соответственно даже если вы отправляете одну секунду, вы платите за 15. Обрезав 20 секунд мы экономим на одном такте распознавания.
С аналоговой телефонии мы снимаем файлы в несжатом виде, в формате *.wav, а в Yandex их нужно отправлять в специальном формате OggOpus.
Соответственно, используем бесплатную консольную конвертацию с помощью утилиты opensenc, которую можно скачать с сайта https://opus-codec.org/
Команда выглядит так:
На входе даем wav-формат, и получаем сжатые аудиоданные.
Как масштабироваться при больших количествах звонков

Вначале, в 2017 году, у меня была обработка, которая распознавала короткие аудиозаписи.
В дальнейшем я перешел на распознавание длинных аудио – сейчас расскажу, почему.
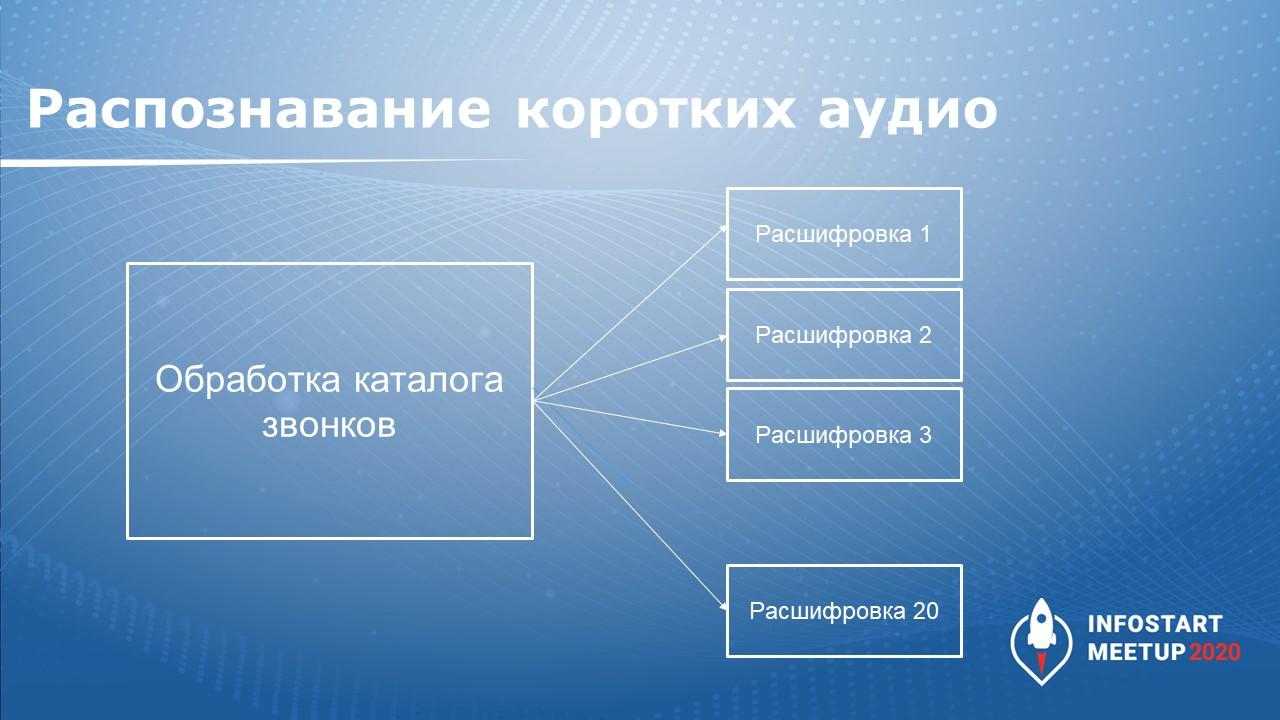
Короткие аудиозаписи распознаются следующим образом:
-
сначала одна обработка ожидания проходит по списку звуковых файлов, назначает им, в каком потоке они будут отправлены в Яндекс, и завершает свою работу;
-
далее запускается обработка каждого потока, которая берет только звонки, которые принадлежат этому потоку – это позволяет масштабироваться.
При моей нагрузке мне было достаточно четыре потока отправки на Яндекс-расшифровку.
Напомню, что это распознавание коротких аудио.
Чем различаются короткие аудио от длинных? Короткие аудио-файлы распознаются онлайн – это стоит дороже и размер файла коротких аудио должен быть не больше одного мегабайта (не больше 30 секунд).
Соответственно, берется звуковой файл телефонного звонка, он нарезается на кусочки по 30 секунд с помощью программы sox, о которой я говорил выше, и далее каждый кусочек отправляется на Яндекс-расшифровку.
Отправляется он последовательно:
-
сначала отправляется первый кусочек, дожидается ответ и записывается в поле расшифровки справочных звонков;
-
далее отправляется второй кусочек, и далее третий – и так, пока не распознали весь звонок.
-
если все хорошо и ни один из кусочков не вернул ошибок, тогда помечаем звонок как обработанный.
Все это хорошо работало где-то с 2017 года по осень 2019, когда начались проблемы с тем, что при обработке телефонного звонка, нарезанного на шесть кусков, два из них могли вернуть ошибку. При повторной отправке через несколько минут снова один кусок мог вернуть ошибку и т.д.
Проблему долго решали со службой поддержки Яндекса, но так и не смогли решить. Так как мне не требовалось именно онлайн-распознавание, они предложили перейти на офлайн-расшифровку длинных аудиозаписей.
Распознавание длинных аудиозаписей происходит вот так:
-
одна обработка перебирает телефонные звонки и создает элементы в справочнике «Звонки» «1С:Управление торговлей»;
-
далее она же отправляет эти звонки в Yandex Object Storage, получает на ссылку на загруженные файлы;
-
далее она же отправляет эти ссылки на расшифровку – у Yandex SpeechKit есть ограничение, что одна минута расшифровки занимает около 10 секунд;
-
при следующей итерации эта же обработка проверяет, расшифровались эти звонки или нет – если расшифровка готова, этот текст получается и записывается в элемент справочника.
Поскольку в данном случае расшифровка производится не в онлайн-режиме, общение с Яндексом происходит очень быстро.
Единственная нагрузка – когда заливаешь звуковой телефонный разговор на Yandex Object Storage. Но в принципе, при 30 мегабит интернета это занимает несколько секунд. Напомню, что размеры wav-файлов и так достаточно маленькие, тем более что менеджеры у нас обычно общаются по 10-15 минут, не больше.
У распознавания длинных аудио есть свои лимиты – один гигабайт на размер файла или не более 4 часов. Но у нас ни один из менеджеров данный лимит не превысил.
Первоначально при распознавании коротких аудио у меня возникла проблема с нагрузкой на систему – отправка кусочков аудио у меня на тот момент была реализована через функции 1С, мне нужно было запускать 1С в четырех потоках, и каждый из потоков общался с Яндексом. Потоки могли подвисать, их нужно было перезапускать.
В дальнейшем я перешел на Curl – я в 1С запускаю Curl, он кушает меньше памяти, соответственно, он уже общается с Яндексом по отправке кусочков данных. В этом варианте зависания были решены.
При распознавании длинных аудио я тоже все общение с Яндексом вынес в Curl – 1С только запускает внешнюю команду, а все дальнейшие действия уже осуществляется через Curl.
Навигатор по конфигурации базы 1С 8.3 Промо
Универсальная внешняя обработка для просмотра метаданных конфигураций баз 1С 8.3.
Отображает свойства и реквизиты объектов конфигурации, их количество, основные права доступа и т.д.
Отображаемые характеристики объектов: свойства, реквизиты, стандартные рекизиты, реквизиты табличных частей, предопределенные данные, регистраторы для регистров, движения для документов, команды, чужие команды, подписки на события, подсистемы.
Отображает структуру хранения объектов базы данных, для регистров доступен сервис «Управление итогами».
Платформа 8.3, управляемые формы. Версия 1.1.0.85 от 10.10.2021
3 стартмани
Знакомство с API Yandex SpeechKit
Представьте простую, максимально идеальную ситуацию без подводных камней типа “а если..”. Вы организуете закрытую вечеринку и хотите общаться с гостями, ни на что не отвлекаясь. Тем более на тех, кого вы не ждали.
Давайте попробуем создать виртуального дворецкого, который будет встречать гостей и открывать дверь только приглашенным.
Синтез текста через cURL
С помощью встроенной в bash команды export запишем данные в переменные:
Теперь их можно передать в POST-запрос с помощью cURL:
Рассмотрим параметры запроса:
speech.raw – файл формата LPSM (несжатый звук). Это и есть озвученный текст в бинарном виде, который будет сохранен в текущую папку.
lang=ru-RU – язык текста.
emotion=good – эмоциональный окрас голоса. Пусть будет дружелюбным.
voice=ermil – текст будет озвучен мужским голосом Ermil. По умолчанию говорит Оксана.
https://tts.api.cloud.yandex.net/speech/v1/tts:synthesize – url, на который отправляется post-запрос на синтез речи дворецкого.
Бинарный файл послушать не получится, тогда установим утилиту SoX и сделаем конвертацию в wav:
speech.wav – приветствие готово и сохранено в текущую папку.
Для проигрывания wav внутри кода Python, можно взять, например, библиотеку simpleaudio. Она простая и не создает других потоков:
Итак, наш первый гость стоит перед входом на долгожданную party. Пытается открыть дверь, и вдруг слышит голос откуда-то сверху:
«Привет, чувак! Назови-ка мне свои имя и фамилию?» (или ваш вариант)
Отлично! Вы научили дворецкого приветствовать гостей, используя командную строку и cURL. А пока гость вспоминает ответ, научимся работать с API на языке Python.
Распознавание текста с помощью requests
Мы могли бы снова воспользоваться cURL для отправки ответа гостя на распознавание. Но мы пойдем дальше и напишем небольшую программу, основанную на подобных запросах.
Создайте готовый аудио-файл с ответом гостя. Сделать это можно через встроенный микрофон на вашем ноутбуке разными инструментами. Для macos подойдет Quick Time Player. Сконвертируйте аудио в формат ogg: name_guest.ogg. Можно онлайн, например, тут
Итак, пишем код на Python:
Для отправки запросов в Python воспользуемся стандартной библиотекой requests:
Импортируем в код:
Зададим параметры, которые мы получили в командной строке:
Аудио необходимо передавать в запрос в бинарном виде:
Давайте обернем весь процесс распознавания в функцию recognize:
Итак, чтобы дворецкий смог проверить гостя по списку, вызовем функцию и распознаем ответ:
Теперь очередь за дворецким. В нашем случае, он вежлив ко всем. И прежде чем открыть или не открыть гостю дверь, он обратится лично. Например, так:
“Мы вам очень рады, <имя_и фамилия_гостя>, но вас нет в списке, сорян”
Для последующего синтеза вы можете снова воспользоваться CURL или так же написать функцию на Python. Принцип работы с API для синтеза и распознавания речи примерно одинаков.
Faster — многофункциональный ускоритель работы программиста 1С и других языков программирования Промо
Программа Faster 9.4 позволяет ускорить процесс работы программиста
(работает в любом текстовом редакторе).
Подсказка при вводе текста на основе ранее введенного текста и настроенных шаблонов.
Программа Faster позволяет делится кодом с другими программистами в два клика или передать ссылку через QR Код.
Исправление введенных фраз двойным Shift (с помощью speller.yandex). Переводчик текста. Переворачивает текст случайно набранный на другой раскладке.
Полезная утилита для тех, кто печатает много однотипного текста, кодирует в среде Windows на разных языках программирования.
Через некоторое время работы с программой у вас соберется своя база часто используемых словосочетаний и кусков кода.
Настройка любых шорткатов под себя с помощью скриптов.
Никаких установок и лицензий, все бесплатно.
1 стартмани


