Семантическое ядро
Содержание:
- Уточняем список
- Шаг 5. Побеждаем коварный Google AdWords
- Семантическое ядро что это?
- Бесплатный парсинг запросов конкурентов
- Группировка семантического ядра для информационного сайта
- Основные характеристики поисковых запросов
- Сервисы и инструменты для работы с семантикой
- Краткая инструкция по добавлению семантического ядра в Topvisor
- Общий процесс сборки СЯ
- Что такое семантическое ядро простыми словами
- Расширение семантического ядра
- Кратко: как не допустить ошибок при создании ядра
Уточняем список
Составить первичный список не означает создать семантическое ядро. Это основа, но само ядро будет намного больше. И расширяется оно за счет уточнений — второстепенных запросов, которые уточняют базовые запросы.
На этом этапе начните просмотр сайта, изучите каталог продукции и услуг и выберите подходящие ключевые фразы. Для удобства продолжайте последовательно заносить данные в таблицу, добавляя в нее новые столбцы, определяющие ваши товары и услуги.
 Пример таблицы для создания первичного списка семантического ядра
Пример таблицы для создания первичного списка семантического ядра
В примере транзакция — это оформление доставки цветов, а действие — то, что потенциальный клиент может совершить. Что можно сделать с цветами? Их можно доставить или заказать.
Наш клиент осуществляет доставку цветов только в Москве, поэтому в четвертый столбец, характеризующий географическое положение, заносим «Москва» и не забываем, что пользователь может указать свою принадлежность к городу при помощи сокращения «Мск».
В следующих столбцах мы сосредоточимся на стоимости услуги и ценовом сегменте. Так мы сможем показывать более релевантное рекламное объявление для целевой аудитории, заинтересованной в оформлении доставки по невысокой цене
Здесь важно правильно определить, к какой нише относится ваш клиент. Если это премиум-сегмент, слова «дешево» и «недорого» должны быть использованы в качестве минус-слов, чтобы исключить нецелевые запросы, поэтому будьте внимательны при изучении продуктов и услуг, которые вы предлагаете.
Услуга имеет определенный параметр «срочность», поэтому добавим дополнительный столбец с этим свойством. Как пользователь может выражать свою потребность в срочной доставке? Задавая запросы «срочная доставка букетов», «доставка цветов быстро», «экспресс-доставка цветов». Все возможные синонимы заносим в таблицу.
Кстати, про синонимы — их можно придумать самостоятельно или же воспользоваться словарем синонимов, например, Synonymonline.
 Автоматический подбор синонимов на портале synonymonline.ruНазвание
Автоматический подбор синонимов на портале synonymonline.ruНазвание
В следующем столбце будут содержаться характеристики услуги — какая она? Ответим на вопрос: какой может быть доставка? В нашем случае клиент готов доставить букет круглосуточно, а заказ можно оформить онлайн. Продумайте все варианты и отразите их в таблице. Помните про использование синонимов, сленговых и профессиональных названий.
В последнем столбце мы отвечаем на вопрос: куда мы можем осуществить доставку, указываем возможные места: «доставка цветов в офис», «заказать букет на дом».
Откуда брать варианты запросов? Сперва из головы. Устройте мозговой штурм, изучите сайт компании, придумывайте различные варианты, по которым пользователи могут искать продукт или услугу, занесите данные в таблицу, добавьте новые столбцы. Таким образом мы собираем основное семантическое ядро для дальнейшего парсинга ключей в ширину и глубину. Начните с «широких» ключевых фраз и затем конкретизируйте их.
Шаг 5. Побеждаем коварный Google AdWords
Первое правило при работе в Google AdWords — минус-слова должны быть во всех возможных словоформах. Для склонения минус-слов мы используем сервис от HTraffic. Зачем нужно склонять слова? Дело в том, что Google останавливает показ объявлений только по конкретным словоформам ключевиков. Например, если вы добавили минус-слово «бесплатный», показ рекламного объявления по словам «бесплатная», «бесплатные» и т.п. по-прежнему будет идти.
Второе правило — очищайте ключевые запросы от предлогов. Если вы указали в точном соответствии фразу с предлогом, например, , то ваше объявление по запросу «кредиты Санкт-Петербург» показано не будет. Поэтому лучше использовать ключевую фразу .
Наш способ составления семантического ядра позволяет найти большое количество низкочастотных и среднечастотных запросов, но может отнять немало времени. Чтобы ускорить этот процесс, я сделала шаблон для составления семантического ядра.
Делитесь в комментариях своими фишками и способами сбора семантики!
Семантическое ядро что это?
Семантическое ядро — это просто набор слов и словосочетаний, по которым мы хотим получать посетителей из поисковых систем на свой сайт.
Чтобы вы понимали, — просто так, Яндекс и Гугл не будут пригонять к вам на сайт бесплатный трафик, так, как они (поисковики) по умолчанию не понимают, для кого и для каких целей сделан ваш сайт. Соответственно наша задача, дать им (поисковикам) понять по каким поисковым запросам мы хотим получать посетителей.
Для этого, с помощью специальных инструментов (о них расскажу ниже) мы подбираем подходящие поисковые запросы и создаем на нашем сайте одноименные страницы под них. Так, мы даем поисковым системам понять, какая тема у данной страницы и по каким поисковым запросам на нее должны попадать пользователи.
Резюмируя сказанное:Семантическое ядро — это просто набор подходящих запросов пользователей по которым мы хотим получать бесплатный трафик и под которые будем создавать страницы на своем сайте.
Пример моего семантического ядра с пояснениями
Вот так выглядит мое семантическое ядро для сайта, возможно вам покажется, что оно сложное, но это совершенно не так. Для наглядности давайте чуть его разберем. Какие важные части есть в данном семантическом ядре:
Столбец «Запрос» — в этот столбик попадают поисковые запросы пользователей, под которые я написал или только собираюсь написать статью для своего блога.— Зеленый цвет — означает, что статья вышла в топ и ее не нужно переписывать;— Желтый цвет — означает, что статья движется к топу;— Красный цвет — означает, что статья не в топе, нужно подождать или переписать ее.
Столбец «Конкуренция» — в нем отображается конкуренция по выбранной поисковой фразе, т.е. сколько примерно сайтов продвигаются по этому запросу и как сложно будет по нему выйти в топ (чем больше число, тем сложнее выйти).
Столбец «Частотность» — показывает сколько раз в месяц запрашивают эту фразу в Яндексе.
Столбец «Хвост» — отображает количество хвостов к выбранной фразе. — Хвост это дополнение к основному запросу. Например я хочу написать статью под запрос «купить ноутбук в Питере» и все слова, которые будут добавляться к этому запросу, будут для меня хвостами. Например во фразе «купить ноутбук в Питере в рассрочку» — словосочетание «в рассрочку» будет для меня хвостом, также слово «хороший» будет хвостом во фразе «купить хороший ноутбук в Питере».
Почти такая же таблица с поисковыми запросами должна получиться и у вас. И именно благодаря ей вы будете наполнять сайт подходящим контентом и получать бесплатный трафик.
Зачем нужно делать сбор семантического ядра для сайта
Что такое СЯ мы разобрали, теперь давайте разберем на кой фиг оно нужно и почему без него будет сложно.
Грубо говоря СЯ — это план по продвижению сайта. Конечно мы можем наполнять сайт и так, «на глазок», добавляя на него разные ключевые слова, которые по нашему мнению приведут нам посетителей, но сразу скажу, это заведомо провальный вариант.
Имейте в виду, хоть Яндекс и Гугл говорят о том, что качество контента важно (и это действительно так), но они не будут пригонять к вам трафик, если не смогут понять для какой поисковой фразы подходит ваш контент. Не забывайте, что поисковики — это всего лишь машины, которые работают по определенным алгоритмам и не могут оценить вашу статью/страницу с точки зрения человека
И знаете, что самое ироничное в этом всем? У вас может быть нереально качественная и полезная статья, но она будет очень далеко от первого места в поисковой выдаче. А у какого-нибудь конкурента/коллеги, который написал откровенный бред, но оптимизировал его под поисковую фразу, будет большое количество бесплатного трафика и его статья будет занимать первые места в выдаче. Несправедливо? Да, но с этим придется считаться.
Поэтому, чтобы не делать работу в холостую, а получать стабильный, положительный результат, нам нужно заранее собрать семантическое ядро и наполнить его подходящими поисковыми запросами, под которые мы будем писать статьи или оптимизировать страницы.
Бесплатный парсинг запросов конкурентов
Чтобы парсить конкурентов, их надо знать. В анализе ниш я уже рассказывал, как определить своих конкурентов.
Выписываем всех ваших конкурентов, если вы еще этого не сделали. Надо брать только прям точных конкурентов. Например, у вас сайт по диабету, вам надо брать только сайты по диабету. Сайты, которые посвящены всей медицине с разделом диабета не подойдут, потому что у вас напарсятся другие разделы сайта, которые посвящены не диабету, и вы запаритесь их чистить.
Wizard.Sape
Заходите в KeyCollector во вкладку Wizard.Sape. Выбираем анализ доменов.Вводим логин, пароль. Любой тематический url и своих конкурентов списком. Нажимаем начать сбор.После сбора, в колонке частотность wordstat, появляются цифры сервиса их необходимо очистить.
Так же можно еще собрать “сбор расширений ключевых фраз” в той же самой вкладке в KeyCollector.
Megaindex
Заходим в KeyCollector во вкладку Megaindex. Вводим логин и пароль, указываем Москва, потому что Россию нельзя указать. Выбираем последнюю дату, раньше можно было парсить за весь период, но сейчас почему-то не работает, можно выбирать только определенную дату. Вбиваем домены конкурентов. И начинаем парсинг.
Rookee
Выбираем Rookee в Keycollector, составление семантического ядра.Здесь все проще, выбираем Москва, топ 10 и вводим конкурентов с http://
Можно отдельно собрать по Яндексу, потом по Гуглу.Так же можно собрать “сбор расширений ключевых фраз” в той же самой вкладке в KeyCollector.
Top.Mail.ru
Здесь все сложнее. Необходимо перейти в рейтинг https://top.mail.ru/, и там найти ваших конкурентов с открытым счетчиком. Обычно что-то узконишевое там сложно найти, но все равно расскажу про этот способ для общего кругозора.
Вводим вашу тематику в поле поиска рейтинга.Получаем сайты. Как видим нашей тематики тут нет. Замочек напротив сайта – стата закрыта. Значок рейтинга – стата открыта.Так вот, если бы мы делали сайт не по диабету, а по косметике, то первый сайт бы нам подошел. У него открыта стата и мы можем спарсить её. Переходим на него и смотрим его id.В KeyCollector щелкаем на значок mail, сбор статистики из счетчиков TOP.MailУказываем id счетчика и выставляем самый большой срок данных, 3 года.Есть так же пакетный анализ, где можно указывать сразу много счетчиков.
Так же можно спарсить глобальный рейтинг top.mail по ключевым словам, в той же самой вкладке в KeyCollector.
На этом бесплатный сбор ключевых слов у конкурентов закончен. Теперь его надо очистить и оставить только нужное.
В итоге получаем готовый список ключевых слов конкурентов, которыми можем дополнить наше ядро.
Группировка семантического ядра для информационного сайта
При группировке семантического ядра я руководствуюсь здравой логикой, сравнивая её с выдачей.
Для информационных сайтов я не вижу смысла прибегать к кластеризации и четко следовать её требованиям. Поисковая система постоянно обучается и совершенствуется. Сегодня она показывает, что запросы “черный хлеб” и “ржаной хлеб” это разные продукты, а завтра покажет правильно, что это одно и тоже.
Итак, в KeyCollector у нас есть чистенький список запросов и мы собрали по нему данные из поисковой выдачи. Чтобы облегчить работу, группируем ядро средствами KeyCollector.
Заходим в анализ групп, ставим по поисковой выдаче Яндекс, сила 2. Обновляем группировку и экспортируем результаты в Excel.Таким способом у нас получилась группировка исходя из данных поисковой системы Яндекс. Но, как я писал уже выше, что надо следовать преимущественно логике и свои предположения проверять в поисковой системе, поэтому в некоторых группах могут быть запросы, которые вообще никак к ней не относятся. Их надо все пересмотреть и доработать.
Чтобы легче было дорабатывать, лучше всего оставить несколько столбцов только с нужными данными. Обычно я оставляю: базовую частотность, точную, KEI по полноте охвата, конкуренцию.
Покажу группировку на примере, чтобы было наглядно. Например, мы создаем сайт посвященный рецептам блинов. Мы увидели, что есть множество запросов связанные с молоком. Решаем, что будем делать отдельную рубрику “Рецепты блинов на молоке”. На примере этой рубрики и рассмотрим группировку.
Смотрим первую группу:Видим, что в группу “простого рецепта” попал общий запрос “тесто для блинов на молоке рецепт” – этим запросом человек не обязательно хочет найти простой рецепт. По логике, лучше всего этот запрос перенести в общую группу, которая будет вести на категорию со всеми рецептами блинов на молоке.
Но так же следует и глянуть выдачу в яндексе, что там вообще находится. Смотрим и видим, что действительно в выдаче по этому запросу есть пара страниц, которые ведут не на один рецепт, а на множество. Так же видим, что в выдаче большинство страниц ведут на один рецепт, при этом на рецепты тонких блинов. Но это же тупо, человек не обязательно хочет тонкие блины. Если бы он хотел тонкие блины, то он ввёл это в запрос. А у нас общий запрос, мы должны показать ему общую страницу, а он уже на ней должен определиться какие блины он хочет на молоке – с простым рецептом или тонкие блины или в дырочку или еще какие-то. В общем я мыслю так.
Переносим лишний запрос в другую группу, а точнее создаем выше новую “Рубрика рецепты блинов на молоке” отмечаем её другим цветом, потому что это рубрика, а в неё уже будут входить рецепты в нашем случае “простой рецепт блинов на молоке”. Тем самым у нас создается структура внутри семантики.
Все данные по группе суммируем. Бюджет можно выводить средним числом, так как это взаимодополняемые запросы, вы все их продвигаете на одной странице, а не по отдельности.
KEI1 (полнота охвата) выводим по уже известной нам формуле:
/*100
Получается вот такая красота:Данные по «рубрике рецепты блинов на молоке» еще не суммируем, потому что скорее всего туда добавятся еще запросы. Но и не исключено, что в “простой рецепт блинов на молоке” тоже еще добавятся запросы.
К тому же тут еще и затесался запрос с “тонкие блины”. Его тоже отдельно, он будет страницей к рубрике “рецепт блинов на молоке и воде”
И таким вот способом перерабатываем все ядро, в итоге получается вот так:Красным шрифтом помечены дополнительные фразы, которые имеют приставки фото, видео. Для нас это не совсем актуальные фразы. Эти фразы конкурируют с сервисами поисковых систем и трафику по ним очень мало. Но эти фразы подходят по нашему смыслу, поэтому мы их добавляем в группу.
Каждая группа помечена своим цветом. Цвет является структурой сайта, то есть уровнем вложенности страницы.
Например, если бы у нас был запрос “простой рецепт блинов на скисшем молоке”. То он бы уже шёл, как подгруппа к группе “блины на скисшем молоке” и естественно был бы выделен другим цветом. Выглядело бы это вот так:Думаю, идея с цветом понятна. Вот так создается семантика и удобная, понятная структура сайта, где все логично и имеет свой уровень вложенности.
Новые или измененные рубрики добавляем в нашу структуру в xmind.
В общем, чтобы нормально разгруппировать ядро необходимо мыслить логически, вставать на место посетителя, отвечать на вопрос – что он хочет увидеть, введя этот запрос? А также смотреть выдачу по этому запросу и принимать решение, как поступить наилучшим образом.
Основные характеристики поисковых запросов
Частотность
Выделяют следующие виды запросов по частотности:
- Высокочастотные (ВЧ);
- Среднечастотные (СЧ);
- Низкочастотные (НЧ).
Градация достаточно условна и для разных тематик может варьироваться. Например, запрос «купить айфон» может в тысячи раз превышать по частоте поиска запрос «рассада», но оба могут быть высокочастотными в своей нише.
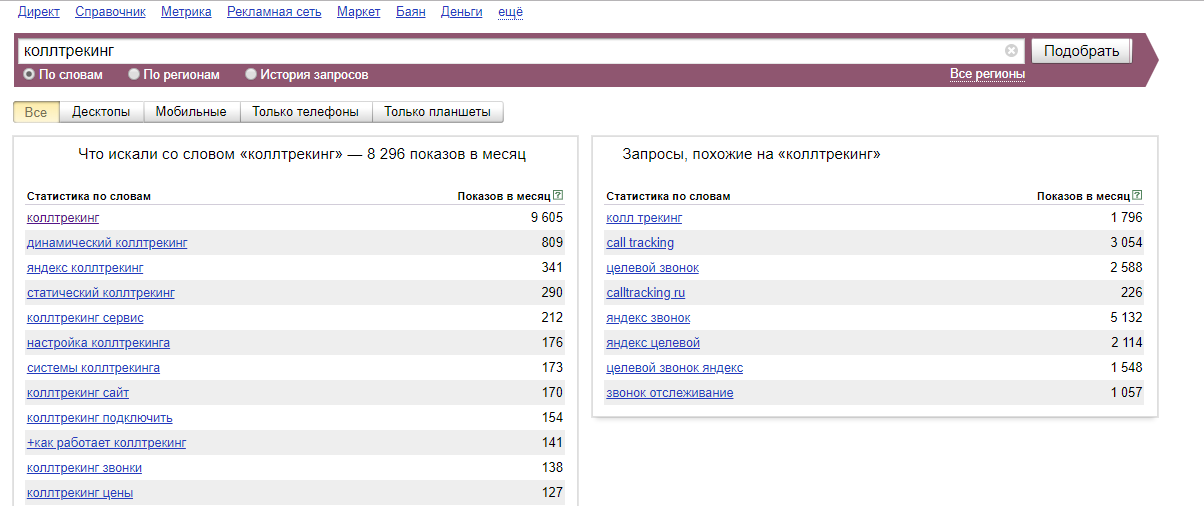
В нашем примере высокочастотным является запрос коллтрекинг. Остальные, скорее, относятся к СЧ, а НЧ остались вне списка — это длинные запросы с конкретными вопросами или требованиями к сервису.
В начале следует формировать средне- и низкочастотные запросы, так как высокочастотные являются также высококонкурентными. При этом, поисковики отдают приоритет тем, кто учитывает низкочастотные запросы как соответствующие реальным запросам аудитории.
Геозависимость
Результаты поиска могут различаться в зависимости от региона нахождения пользователя. Так происходит в случаях, если:
- Сайт имеет региональную привязку;
- Настроены рекламные кампании с привязкой к локации пользователя;
- Сайт включен в справочник Яндекс или Google и отображается его адрес на картах.
Если пользователь ищет определённый товар, поисковик предложит тех поставщиков, которые на текущий момент ближе всего к нему. Геозависимость определяется не формулировкой запроса, а привязкой результатов к географической местности.
По цели поиска
Информационные
Информационный ключ предполагает желание пользователя получить информацию по определённой теме, что-то узнать. Например, «как подключить коллтрекинг», «где пройти курсы digital маркетолога».
Транзакционные
Запросы, связанные с совершением некоторого действия, чаще всего — покупка, доставка, путешествия. То есть, преобладают коммерческие ключи.
Коммерческий ключ содержит такие слова, как «купить», «заказать», «с доставкой», «приобрести» и подобные.
Прочие
По нечётким ключам не удаётся точно понять конкретное намерение пользователя. Например, «сайт wordpress». Неясно, хочет ли человек создать сайт, заказать разработку или устранить ошибку. От этого зависит релевантность семантического ядра сайта.
Сервисы и инструменты для работы с семантикой
Профессиональные SEO-оптимизаторы и маркетологи пользуются рядом программ и сервисов для формирования семантического ядра. Инструменты помогают ускорить и облегчить рутинную работу, а также получить ценные сведения о конкурентах.
Rash-Analytics
Сервис является традиционным инструментом оптимизатора. Функционал включает проверку и мониторинг позиций сайта по запросам, автоматическое составление семантического ядра.
Преимущества сервиса Руш-аналитикс:
- интуитивно понятный интерфейс;
- детальный сбор поисковых подсказок;
- возможность выбирать алгоритм – указание маркеров вручную или полная автоматизация.
Сервис позволяет создать семантическое ядро сайта онлайн.
Key Collector
Десктопная программа используется всеми профессиональными контент-маркетологами и SEO-специалистами. Инструмент подбирает ключевые слова, отсекает ненужные запросы, ищет дублирующие фразы, фильтрует запросы по частоте.
В список задач, решаемых программой, входит сбор статистики сторонних сервисов, таких как Гугл ЭдВордс или Яндекс Метрика.
Преимущества программы:
- алгоритм постоянно обновляется, что позволяет более точно составлять семантическое ядро;
- набор инструментов заменяет функционал сразу нескольких программ и сервисов, необходимых маркетологу и SEO-оптимизатору.
Букварикс
Сервис представляет крупнейшую базу ключевых слов в рунете. Здесь легко сортировать запросы и формировать семантическое ядро для сайта.
Преимущества Букварикс:
- база включает более 2 млрд. ключей;
- можно выгружать семантику конкурентов по домену;
- есть бесплатная десктопная версия;
- понятный интерфейс.
Стоимость использования онлайн-сервиса 695 руб./мес.
Serpstat
Онлайн-сервис платный и стоит $69 в месяц. В нем легко подобрать низко- и среднечастотные ключи. Система анализирует поисковые системы Яндекс и Гугл. Анализ помогает определить частотность ключа, уровень конкуренции, стоимость клика по рекламе, список прямых конкурентов.
Преимущества:
- возможность отслеживать динамику запроса;
- удобная система «подсказок»;
- детальный анализ ТОПа поисковой выдачи.
Онлайн-сервис имеет раздел «Контент-маркетинг». Здесь можно увидеть длинноховстые ключи.
Мутаген
Сервис ориентирован на поиск ключей по частотности и уровню конкуренции. Для анализа ключей он анализирует ТОП-30 сайтов из выдачи Яндекса.
С помощью инструмента легко найти ключи с низкой конкуренцией и максимальной частотностью. Оптимизируя сайт под такие фразы, можно быстро продвинуться на первые строчки поисковой выдачи. Полезный для СЕО инструмент анализа стоит от 30 рублей за 100 проверок.
Краткая инструкция по добавлению семантического ядра в Topvisor
Ядро собрано и все тексты написаны? Теперь нужно добавить новые страницы в сервис Topvisor, чтобы следить за динамкой роста сайта. Постоянный мониторинг позиций и обновление ключей поможет вам вовремя реагировать на ухудшение позиций.
- Открываем сайт Topvisor и регистрируемся в сервисе.
- Переходим в «Мои проекты» и нажимаем «Добавить проект».
- Вводим адрес своего сайта и создаем проект.
- Выбираем поисковую систему и нажимаем «Добавить».
- Выбираем регион сайта.
- Переходим во вкладку «Поисковые запросы» и нажимаем на +, чтобы добавить группу запросов. Вставляем скопированные запросы в строку «Добавить запрос» и нажимаем на +.
- Когда все запросы будут добавлены, переходим во вкладку «Проверка позиций». Чтобы проверить позиции, нужно нажать на значок «Обновить».
Рекомендую делать срез позиций раз в неделю.
Общий процесс сборки СЯ
В общем виде сборку запросов можно представить так:
- придумать направления,
- дособрать направления,
- собрать запросы,
- очистить запросы.
Разберем данный процесс на примере, предположив что мы занимаемся доставкой воды.
Придумываем направления
Направления не должны пересекаться между собой. Т.е. если мы выбираем запрос:
вода
то добирать направление:
заказать воду
уже не имеет смысла, т.к. «заказать воду» уже будет включен в кластер «вода».
Для нашей цели, из головы на вскидку придумываем следующие направления:
вода доставка,вода заказать.
Сразу стоит отметить, что данные направления не полны. В рамках данной статьи процесс сборки упрощен с целью показа основных принципов и подходов при формировании СЯ. В действительно боевом проекте может получиться 50, 100 и даже 500 направлений.
Дособираем направления
Для того чтобы максимально подробно собрать необходимые нам запросы, идём на вордстат, вводим:
доставка вода
и смотрим в столбце «Запросы, похожие на «доставка вода» » (данный столбец называется некоторыми специалистами «ЭХО») какие еще направления могут быть полезны:

Кроме всего прочего проверяем другие направления и запросы которые потенциально могли бы нам подойти:

Так же можно вводить в поиске запросы, после чего пролистывать вниз страницы, где можно увидеть смежные направления:

После изучения статистики и мозгового штурма получаем подобный список:
вода доставка,вода заказать,вода офис,вода питьевая.
История с google несколько иная, здесь нельзя просто взять ввести направления и получить запросы, т.к. сервиса подобного яндекс вордстат у гугл нет. Однако можно взять уже собранные запросы из вордстат и с помощью планировщика запросов google проверить их.
Парсим/собираем запросы
Чтобы ускорить данный процесс можно использовать плагины-парсеры запросов яндекс вордстат, например:
- Yandex Wordstat парсер запросов,
- яндекс wordstat assistant.
Можно воспользоваться платной SEOшной программой keycollector, либо её бесплатным аналогом «словоёб».
Самый банальный подход — это копирование в ручном режиме всех запросов с каждой страницы выдачи по каждому из выбранных направлений. Следует копировать руками все запросы в таблицу, что является самым бесперспективным способом, т.к. через неделю подобной работы желание собирать запросы в ручном режиме отпадёт гарантированно.Воспользуемся keycollector’ом и для нашего примера создадим 4 папки, для каждого выбранного направления:

Это нужно для того чтобы структурированно хранить исходники, запросы и группы. Соберем данные из вордстат в соответствии с нашей геозависимостью (мы соберем для Санкт-Петербурга). Экспортируем проекты в csv формате, после чего пересохраняем в xlsx, удалив ненужные, пустые столбцы. После подобных манипуляций в каждой папке будет примерно следующее содержимое:

Содержимое документа «Вода доставка.xlsx»:

Очищаем запросы
Пожалуй самый трудоемкий процесс, который занимает максимум времени — очистка запросов. В зависимости от задач, поставленных перед специалистом, способы очистки могут отличаться, так например можно собирать семантическое ядро для решения различных задач:
- Настройка рекламы
- Распределение запросов по сайту
- Аналитика и прогнозирование
- Написание публикаций.
Для того чтобы сэкономить время, следует просмотреть списки запросов и в зависимости от целей и задач собрать список стоп слов (по др. минус-слова).
Стоп слова/минус-слова
Стоп слова (по др. минус-слова, минус-фразы) — это запросы, которые встречаются часто в большом количестве, при этом являются мусорными, пустыми, неподходящими, ненужными
Списки стоп-слов важно собирать для того, чтобы быстро и просто отсеивать ненужные запросы. Кроме всего прочего, обычно ядер несколько, а вот список минус-слов для каждого ядра один.
Для нашего примера, неподходящими запросами автоматически становятся те, которые содержат региональность отличную от СПБ.
Соответственно, один из списоков стоп слов будет содержать весь список городов и регионов России, за исключением Санкт-Петербурга, Ленинградской области, СПБ, Лен обл и пр. Т.е. следует оставить те запросы, которые нам потенциально полезны. В сети можно найти базы городов и регионов России с помощью которых заминусить ядро.
Что такое семантическое ядро простыми словами
Как это ни странно, но семантическое ядро – это обычный excel файл, в котором списком представлены ключевые запросы, по которым вы (или ваш копирайтер) будете писать статьи для сайта.
Вот как, например, выглядит мое семантическое ядро:
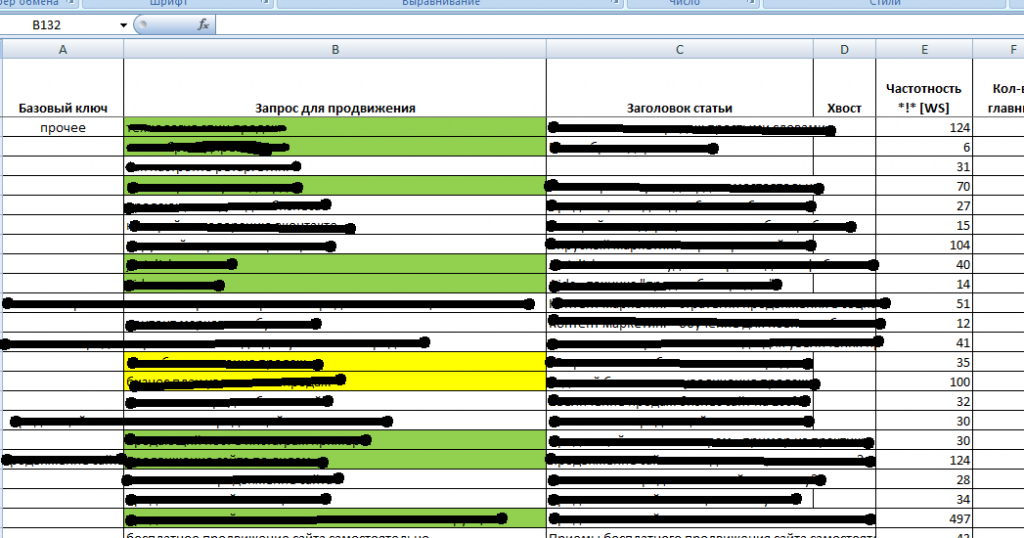
Зеленым цветом у меня помечены те ключевые запросы, по которым я уже написал статьи. Желтым – те, которым статьи собираюсь написать в ближайшее время. А бесцветные ячейки – это значит, что до этих запросов дело дойдет немного позже.
Для каждого ключевого запроса у меня определена частотность, конкурентность, и придуман “цепляющий” заголовок. Вот примерно такой же файл должен получиться и у вас. Сейчас у меня СЯ состоит из 150 ключевиков. Это значит, что я обеспечен “материалом” минимум на 5 месяцев вперед (если даже буду писать по одной статье в день).
Чуть ниже мы поговорим о том, к чему вам готовиться, если вы вдруг решите заказать сбор семантического ядра у специалистов. Здесь скажу кратко – вам дадут такой же список, но только на тысячи “ключей”
Однако, в СЯ важно не количество, а качество. И мы с вами будем ориентироваться именно на это
Зачем вообще нужно семантическое ядро?
А в самом деле, зачем нам эти мучения? Можно же, в конце концов, просто так писать качественные статьи, и привлекать этим аудиторию, правильно? Да, писать можно, а вот привлекать не получится.
Главная ошибка 90% блогеров – это как раз написание просто качественных статей. Я не шучу, у них реально интересные и полезные материалы. Вот только поисковые системы об этом не знают. Они же не экстрасенсы, а всего лишь роботы. Соответственно они и не ставят вашу статью в ТОП.
Здесь есть еще один тонкий момент с заголовком. Например, у вас есть очень качественная статья на тему “Как правильно вести бизнес в “мордокниге”. Там вы очень подробно и профессионально расписываете все про фейсбук. В том числе и то, как там продвигать сообщества. Ваша статья – самая качественная, полезная и интересная в интернете на эту тему. Никто и рядом с вами не валялся. Но вам это все равно не поможет.
Почему качественные статьи вылетают из ТОПа
Представьте, что на ваш сайт зашел не робот, а живой проверяльщик (асессор) с Яндекса. Он понял, что у вас самая классная статья. И рукам поставил вас на первое место в выдаче по запросу “Продвижение сообщества в фейсбук”.
Знаете, что произойдет дальше? Вы оттуда все равно очень скоро вылетите. Потому что по вашей статье, даже на первом месте, никто не будет кликать. Люди вводят запрос “Продвижение сообщества в фейсбук”, а у вас заголовок – “Как правильно вести бизнес в “мордокниге”. Оригинально, свежо, забавно, но… не под запрос. Люди хотят видеть именно то, что они искали, а не ваш креатив.
Соответственно, ваша статья будет вхолостую занимать место в ТОП выдачи. И живой асессор, горячий поклонник вашего творчества, может сколько угодно умолять начальство оставить вас хотя бы в ТОП-10. Но не поможет. Все первые места займут пустые, как шелуха от семечек, статейки, которые друг у друга переписали вчерашние школьники.
Зато у этих статей будет правильный “релевантный” заголовок – “Продвижение сообщества в фейсбук с нуля” (по шагам, за 5 шагов, от А до Я, бесплатно и пр.) Обидно? Еще бы. Ну так боритесь против несправедливости. Давайте составим грамотное семантическое ядро, чтобы ваши статьи занимали заслуженные первые места.
Еще одна причина начать составлять СЯ прямо сейчас
Есть еще одна вещь, о которой почему-то люди мало задумываются. Вам надо писать статьи часто – как минимум каждую неделю, а лучше 2-3 раза в неделю, чтобы набрать побольше трафика и побыстрее.
Все это знают, но почти никто этого не делает. А все потому, что у них “творческий застой”, “никак не могут себя заставить”, “просто лень”. А на самом деле вся проблема именно в отсутствие конкретного семантического ядра.
Наше СЯ – это как контент-план для социальных сетей. То есть там написано конкретно, что мы будем делать в ближайшие 2-3 месяца. Нам не надо будет садиться с утра и начать выдумывать тему для нового поста. У нас все придумано, продумано и прочитано.
Именно это и спасет вас от так называемого “творческого кризиса”. Когда вы точно знаете, что вам делать – становится гораздо легче. Поэтому ни в коем случае не пропускайте этап создания семантического ядра (каким бы муторным вам это дело не показалось). Потом вам все равно придется подбирать темы и запросы, но только потратите вы на это в десять раз больше времени и сил.
А теперь. собственно, давайте разберем, как правильно составить семантическое ядро с нуля.
Расширение семантического ядра
Использование платного приложения не позволяет расширить семантическое ядро еще больше. Оно создает готовые группы ключей. Вот примерный перечень (в скобках возьмем пример из сайта по продаже рубашек):
- Вид (белые льняные рубашки, черные котоновые рубашки);
- Стиль (официальные рубашки, в клетку, в полоску);
- Предназначение (рубашки на работу, рубашки в отпуск);
- Для кого (рубашки для мужчин, рубашки для женщин).
Однако, в большинстве случаев, этого не хватит, чтобы охватить определенную нишу полностью, особенно, если есть большой поток конкурентов. Поэтому, чтобы увеличить структуру и собрать микрочастотные ключи, следует объединить страницы между собой.
На выходе получится такая структура:
- Вид (белые льняные рубашки);
- Стиль (официальные рубашки);
- Для чего (рубашки на работу);
- Кому (рубашки для мужчин);
- Виды/Куда (белые льняные рубашки на работу);
- Виды/Кому (белые льняные рубашки для мужчин);
- Виды/Стиль (белые льняные официальные рубашки);
- Куда/Кому (рубашки на работу для мужчин);
- Куда/Стиль (официальные рубашки на работу);
- Виды/Куда/Кому (белые льняные рубашки на работу для мужчин);
- Виды/Стиль/Кому (белые официальные льняные рубашки для мужчин).
Также можно обозначить регион, если ниша распространяется на несколько городов. Проделав данную работу, мы можем подстроить сайт под любые запросы, которые могут возникнуть у пользователя. Единственным минусом оптимизированного сайта считается каннибализация ключей на страницах.
Кратко: как не допустить ошибок при создании ядра
Ищите любые способы пополнить СЯ качественными ключами. Если собирать только очевидные запросы и никак не расширять ядро, можно лишиться большой части трафика.
Тематика ключей не должна обманывать пользователя. Если юзер зашел на сайт по фразе «установка windows», вряд ли он останется на нем, если страница рассказывает об установке macOS.
Не стоит оставлять «пустые» ключи с крайне низкой или нулевой частотностью. Они почти неэффективны для продвижения ресурса.
Регулярно обновляйте ядро и учитывайте сезонность. Некоторые запросы эффективны только в определенный период. Если какой-то ключ сейчас не работает, это не значит, что так будет всегда.
Используйте несколько инструментов для создания СЯ. Когда вы ограничиваетесь каким-то одним сервисом, список запросов может оказаться неполным.
Обязательно делайте кластеризацию. Именно этот этап превращает тысячи ключей в грамотную структуру, которая разбита на категории, страницы, статьи и т. д.
Не используйте слишком много запросов на одной странице и не смешивайте разные тематики. Это снижает релевантность страницы и приводит нецелевой трафик
Важно, чтобы одна страница соответствовала одному интересу человека.


