Str python. строки в python
Содержание:
- Split Lists into Chunks Using Itertools
- Метод split()
- Примеры разделения строки в Python
- Python NumPy split columns
- Разделение строки при помощи последовательно идущих разделителей
- Ограничение одновременного доступа к ресурсам
- Python split examples
- Переназначение строк
- Узнайте, какие встроенные методы Python используются в строковых последовательностях
- Синхронизация потоков
- Индексация строк
- Split Lists into Chunks Using a For-Loop
- Метод join()
- Разделение строки с использованием разделителя
- Специфичные для потока данные
- Открытие и закрытие файла
- Что такое подстрока в Python?
- Объекты потоков
- Split Python Lists into Chunks Using a List Comprehension
Split Lists into Chunks Using Itertools
Let’s see how we can use library to split a list into chunks. In particular, we can use the function to accomplish this.
Let’s see how we can do this:
# Split a Python List into Chunks using itertools from itertools import zip_longest our_list = chunk_size = 3 chunked_list = list(zip_longest(**chunk_size, fillvalue='')) print(chunked_list) # Returns: chunked_list = *chunk_size, fillvalue=''))] print(chunked_list) # Returns: , , , ]
We can see here that we can have a relatively simple implementation that returns a list of tuples. Notice one of the things that’s done here is split the list into chunks of size n, rather than into n chunks.
Метод split()
Метод split() есть противоположностью методу join. С его помощью можно разбить строки по нужному вам разделителю и получить список строк.
Метод split() может принимать несколько параметров. Первый параметр — это разделитель, по которому будет разделяться строка. Если вы не указали разделитель, то любой символ (пробел или даже другая строка) уже автоматически считается новым разделителем. Другой параметр — это maxsplit. Он нужен для того, чтобы показать какое будет число разделений в строке. Если вы укажите maxsplit, то ваш список будет иметь maxsplit и еще один объект.
Пример кода:
food='Water, Bread, Bun, Grape'
#maxsplit:3
print(food.split (',', 3))
#maxsplit:4
print(food.split (',', 4))
Вывод программы:
Примеры разделения строки в Python
Разделение сроки по пробелу
Если не передать параметр разделителя, то выполнит разделение по пробелу.
Копировать
Код вернет: .
Обратите внимание, что мы не указали разделитель, который нужно использовать при вызове функции , поэтому в качестве разделителя используется пробел
Разделение строки по запятой
Разделителем может выступать запятая (). Это вернет список строк, которыеизначально были окружены запятыми.
Копировать
Вывод: . Результатом является список подстрок, разделенных по запятым в исходной строке.
Разделение строк по нескольким разделителям
В Python можно использовать даже несколько разделителей. Для этого просто требуется передать несколько символов в качестве разделителей функции split.
Возьмем в качестве примера ситуацию, где разделителями выступают одновременно и . Задействуем функцию .
Копировать
Вывод:
Здесь мы используем модуль re и функции регулярных выражений. Переменной была присвоена строка с несколькими разделителями, включая «\n», «;» и «,». А функция вызывается для этой строки с перечисленными выше разделителями.
Вывод — список подстрок, разделенных на основе оригинальной строки.
Python NumPy split columns
- In this section, we will discuss how to split columns in NumPy array by using Python.
- In this example, we are going to use the concept array transpose. In Python, the transpose matrix is moving the elements of the row to the column and the column items to the rows. In simple word, it will reverse the values in an array.
Syntax:
Here is the Syntax of array transpose
Example:
In the above code, we have created an array and declared variables named ‘col1′, ‘col2’, ‘col3’ in which we have assigned the array transpose arr.T. Once you will print ‘col1’, ‘col2’, ‘col3’ then the output will display the split elements.
You can refer to the below Screenshot

Python NumPy split columns
Python NumPy empty array with examples
Разделение строки при помощи последовательно идущих разделителей
Если вы для разделения строки используете метод и не указываете разделитель, то разделителем считается пробел. При этом последовательно идущие пробелы трактуются как один разделитель.
Но если вы указываете определенный разделитель, ситуация меняется. При работе метода будет считаться, что последовательно идущие разделители разделяют пустые строки. Например, .
Если вам нужно, чтобы последовательно
идущие разделители все-таки трактовались
как один разделитель, нужно воспользоваться
регулярными выражениями. Разницу можно
видеть в примере:
import re
print('Hello1111World'.split('1'))
print(re.split('1+', 'Hello1111World' ))
Результат:
Ограничение одновременного доступа к ресурсам
Как разрешить доступ к ресурсу нескольким worker одновременно, но при этом ограничить их количество. Например, пул соединений может поддерживать фиксированное число одновременных подключений, или сетевое приложение может поддерживать фиксированное количество одновременных загрузок. Semaphore является одним из способов управления соединениями.
import logging
import random
import threading
import time
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s (%(threadName)-2s) %(message)s',
)
class ActivePool(object):
def __init__(self):
super(ActivePool, self).__init__()
self.active = []
self.lock = threading.Lock()
def makeActive(self, name):
with self.lock:
self.active.append(name)
logging.debug('Running: %s', self.active)
def makeInactive(self, name):
with self.lock:
self.active.remove(name)
logging.debug('Running: %s', self.active)
def worker(s, pool):
logging.debug('Waiting to join the pool')
with s:
name = threading.currentThread().getName()
pool.makeActive(name)
time.sleep(0.1)
pool.makeInactive(name)
pool = ActivePool()
s = threading.Semaphore(2)
for i in range(4):
t = threading.Thread(target=worker, name=str(i), args=(s, pool))
t.start()
В этом примере класс ActivePool является удобным способом отслеживания того, какие потоки могут запускаться в данный момент. Реальный пул ресурсов будет выделять соединение для нового потока и восстанавливать значение, когда поток завершен. В данном случае он используется для хранения имен активных потоков, чтобы показать, что только пять из них работают одновременно.
$ python threading_semaphore.py 2013-02-21 06:37:53,629 (0 ) Waiting to join the pool 2013-02-21 06:37:53,629 (1 ) Waiting to join the pool 2013-02-21 06:37:53,629 (0 ) Running: 2013-02-21 06:37:53,629 (2 ) Waiting to join the pool 2013-02-21 06:37:53,630 (3 ) Waiting to join the pool 2013-02-21 06:37:53,630 (1 ) Running: 2013-02-21 06:37:53,730 (0 ) Running: 2013-02-21 06:37:53,731 (2 ) Running: 2013-02-21 06:37:53,731 (1 ) Running: 2013-02-21 06:37:53,732 (3 ) Running: 2013-02-21 06:37:53,831 (2 ) Running: 2013-02-21 06:37:53,833 (3 ) Running: []
Python split examples
In the following examples, we cut strings into parts with the previously
mentioned methods.
splitting.py
#!/usr/bin/python
line = "sky, club, cpu, cloud, war, pot, rock, water"
words = line.split(',')
print(words)
words2 = line.split(', ')
print(words2)
words3 = line.split(',')
words4 =
print(words4)
In the example, we cut the line of words delimited with a comma into a list of
words.
words = line.split(',')
The string is cut by the comma character; however, the words have spaces.
words2 = line.split(', ')
One way to get rid of the spaces is to include a space character in the
separator parameter.
words3 = line.split(',')
words4 =
Another solution is to use the method.
$ ./splitting.py
With the parameter we can set how many splits will be
done.
maxsplit.py
#!/usr/bin/python
line = "sky, club, cpu, cloud, war, pot, rock, water"
words = line.split(', ', 3)
for word in words:
print(word)
print('-------------------------')
words2 = line.split(', ', 4)
for word in words2:
print(word)
The rest of the words forms one string.
$ ./maxsplit.py sky club cpu cloud, war, pot, rock, water ------------------------- sky club cpu cloud war, pot, rock, water
In the next example, we get words from the end of the string.
split_right.py
#!/usr/bin/python
line = "sky, club, cpu, cloud, war, pot, rock, water"
words = line.rsplit(', ', 3)
print(words)
Using the method, we get the last three words.
$ ./split_right.py
Переназначение строк
Обновить содержимое строк так же просто, как присвоить его новой строке. Строковый объект не поддерживает присвоение элемента, т. е. строка может быть заменена только новой строкой, поскольку ее содержимое не может быть частично заменено. Строки неизменяемы в Python.
Рассмотрим следующий пример.
Пример 1.
str = "HELLO" str = "h" print(str)
Выход:
Traceback (most recent call last):
File "12.py", line 2, in <module>
str = "h";
TypeError: 'str' object does not support item assignment
Однако в примере 1 строку str можно полностью присвоить новому содержимому, это указано в следующем примере.
Пример 2.
str = "HELLO" print(str) str = "hello" print(str)
Выход:
HELLO hello
Узнайте, какие встроенные методы Python используются в строковых последовательностях
Строка — это последовательность символов. Встроенный строковый класс в Python представлен строками, использующими универсальный набор символов Unicode. Строки реализуют часто встречающуюся последовательность операций в Python наряду с некоторыми дополнительными методами, которые больше нигде не встречаются. На картинке ниже показаны все эти методы:
 Встроенные строковые функции в Python
Встроенные строковые функции в Python
Давайте узнаем, какие используются чаще всего
Важно заметить, что все строковые методы всегда возвращают новые значения, не меняя исходную строку и не производя с ней никаких действий
Код для этой статьи можно взять из соответствующего репозитория Github Repository.
1. center( )
Метод выравнивает строку по центру. Выравнивание выполняется с помощью заданного символа (пробела по умолчанию).
Синтаксис
, где:
- length — это длина строки
- fillchar—это символ, задающий выравнивание
Пример

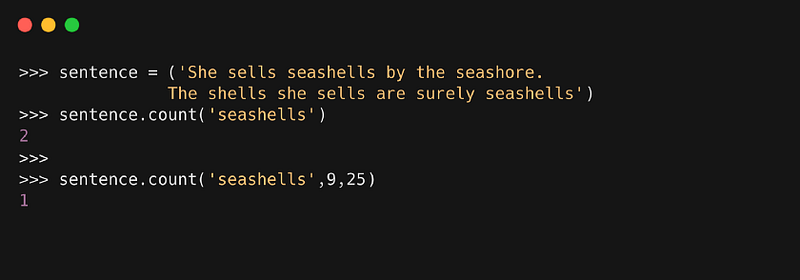
2. count( )
Метод возвращает счёт или число появлений в строке конкретного значения.
Синтаксис
, где:
- value — это подстрока, которая должна быть найдена в строке
- start — это начальное значение индекса в строке, где начинается поиск заданного значения
- end — это конечное значение индекса в строке, где завершается поиск заданного значения
Пример
3. find( )
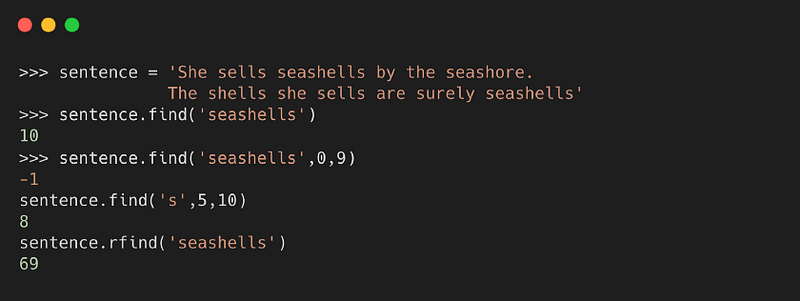
Метод возвращает наименьшее значение индекса конкретной подстроки в строке. Если подстрока не найдена, возвращается -1.
Синтаксис
, где:
- value или подстрока, которая должна быть найдена в строке
- start — это начальное значение индекса в строке, где начинается поиск заданного значения
- end — это конечное значение индекса в строке, где завершается поиск заданного значения
Пример
Метод возвращает копию строки, преобразуя все заглавные буквы в строчные, и наоборот.
Синтаксис
Пример

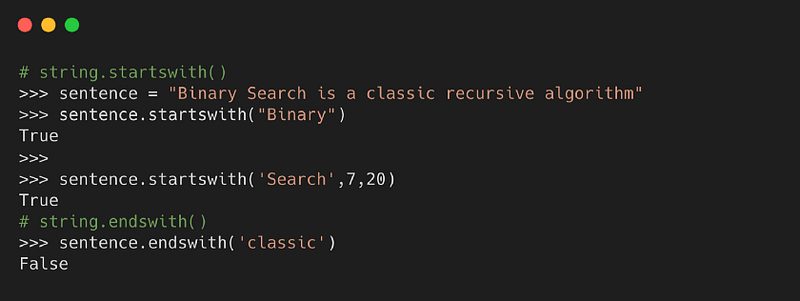
5. startswith( ) and endswith( )
Метод возвращает True, если строка начинается с заданного значения. В противном случае возвращает False.
С другой стороны, функция возвращает True, если строка заканчивается заданным значением. В противном случае возвращает False.
Синтаксис
- value — это искомая строка в строке
- start — это начальное значение индекса в строке, где начинается поиск заданного значения
- end — это конечное значение индекса в строке, где завершается поиск заданного значения
Пример
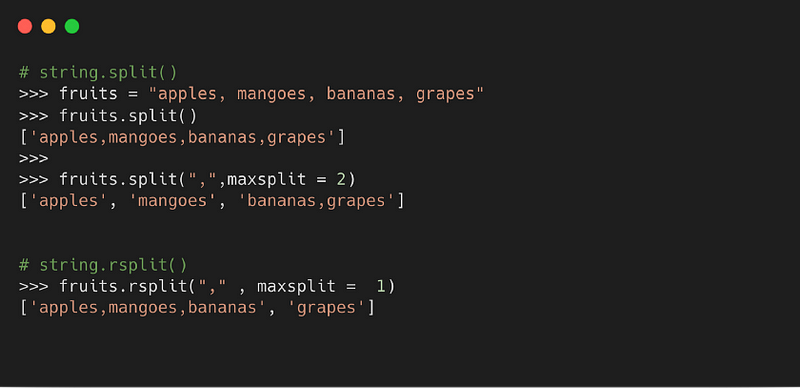
6. split( )
Метод возвращает список слов в строке, где разделителем по умолчанию является пробел.
Синтаксис
- sep: разделитель, используемый для разделения строки. Если не указано иное, разделителем по умолчанию является пробел
- maxsplit: обозначает количество разделений. Значение по умолчанию -1, что значит «все случаи»
Пример
7. Строка заглавными буквами
Синтаксис
Синтаксис
Синтаксис
Пример

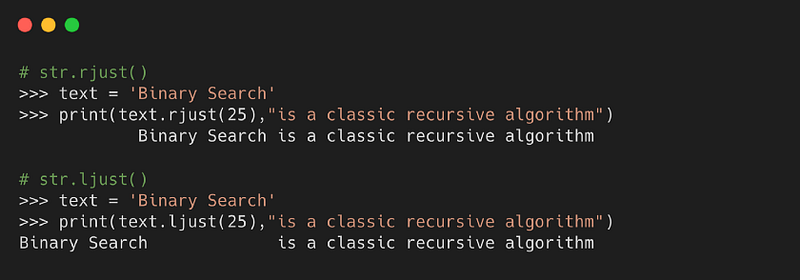
8. ljust( ) и rjust( )
С помощью заданного символа (по умолчанию пробел) метод возвращает вариант выбранной строки с левым выравниванием. Метод rjust() выравнивает строку вправо.
Синтаксис
- length: длина строки, которая должна быть возвращена
- character: символ для заполнения незанятого пространства, по умолчанию являющийся пробелом
Пример
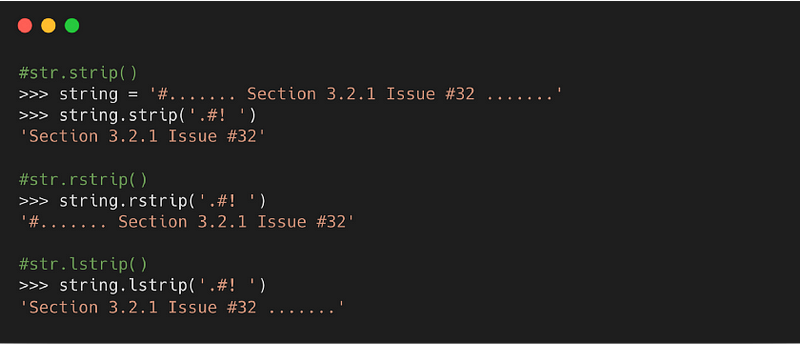
9. strip( )
Метод возвращает копию строки без первых и последних символов. Эти отсутствующие символы — по умолчанию пробелы.
Синтаксис
character: набор символов для удаления
- : удаляет символы с начала строки.
- : удаляет символы с конца строки.
10. zfill( )
Метод zfill() добавляет нули в начале строки. Длина возвращаемой строки зависит от заданной ширины.
Синтаксис
width: указывает длину возвращаемой строки. Нули не добавляются, если параметр ширины меньше длины первоначальной строки.
Пример

Заключение
В статье мы рассмотрели лишь некоторые встроенные строковые методы в Python. Есть и другие, не менее важные методы, с которыми при желании можно ознакомиться в соответствующей документации Python.
- PEG парсеры и Python
- Популярные лайфхаки для Python
- Овладей Python, создавая реальные приложения. Часть 1
Перевод статьи Parul PandeyUseful String Method
Синхронизация потоков
Другой способ синхронизации потоков – объект Condition. Поскольку Condition использует Lock, его можно привязать к общему ресурсу. Это позволяет потокам ожидать обновления ресурса.
В приведенном ниже примере поток consumer() будет ждать, пока не будет установлено Condition, прежде чем продолжить. Поток producer() отвечает за установку Condition и уведомление других потоков о том, что они могут продолжить выполнение.
import logging
import threading
import time
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s (%(threadName)-2s) %(message)s',
)
def consumer(cond):
"""wait for the condition and use the resource"""
logging.debug('Starting consumer thread')
t = threading.currentThread()
with cond:
cond.wait()
logging.debug('Resource is available to consumer')
def producer(cond):
"""set up the resource to be used by the consumer"""
logging.debug('Starting producer thread')
with cond:
logging.debug('Making resource available')
cond.notifyAll()
condition = threading.Condition()
c1 = threading.Thread(name='c1', target=consumer, args=(condition,))
c2 = threading.Thread(name='c2', target=consumer, args=(condition,))
p = threading.Thread(name='p', target=producer, args=(condition,))
c1.start()
time.sleep(2)
c2.start()
time.sleep(2)
p.start()
Потоки используют with для блокировки, связанной с Condition. Использование методов acquire() и release()в явном виде также работает.
$ python threading_condition.py 2013-02-21 06:37:49,549 (c1) Starting consumer thread 2013-02-21 06:37:51,550 (c2) Starting consumer thread 2013-02-21 06:37:53,551 (p ) Starting producer thread 2013-02-21 06:37:53,552 (p ) Making resource available 2013-02-21 06:37:53,552 (c2) Resource is available to consumer 2013-02-21 06:37:53,553 (c1) Resource is available to consumer
Индексация строк
Строка является упорядоченной последовательностью символов. Другими словами, она состоит из символов, стоящих в определённом порядке. Благодаря этому, к символу можно обратиться по его порядковому номеру. Для этого надо указать номер символа в квадратных скобках. Нумерация начинается с нуля (0 – это первый символ).
Копировать
Попытка обращения по индексу большему чем длина строки вызовет исключение IndexError:
Копировать
В качестве индекса может быть использовано отрицательное число. В этом случае индексирование начинается с конца строки: -1 относится к последнему символу, -2 к предпоследнему и так далее.
Копировать
Срезы строк
В Python существует механизм срезов коллекций. Срезы позволяют обратиться к подстроке используя индексы. Для этого надо в квадратных скобках указать: . Каждый из параметров является необязательным. Поскольку строка это коллекция, срезы применимы и к ней.
Копировать
Split Lists into Chunks Using a For-Loop
For-loops in Python are an incredibly useful tool to use. They make a lot of Python methods easy to implement, as well as easy to understand.
For this reason, let’s start off by using a for-loop to split our list into different chunks.
One of the ways you can split a list is into n different chunks. Let’s see how we can accomplish this by using a for loop:
# Split a Python List into Chunks using For Loops
our_list =
chunked_list = list()
chunk_size = 3
for i in range(0, len(our_list), chunk_size):
chunked_list.append(our_list)
print(chunked_list)
# Returns: , , , ]
Let’s take a look at what we’ve done here:
- We instantiate two lists: , which contains the items of our original list, and , which is empty
- We also declare a variable, , which we’ve set to three, to indicate that we want to split our list into chunks of size 3
- We then loop over our list using the range function. What we’ve done here is created items from 0, through to the size of our list, iterating at our chunk size. For example, our range function would read , meaning that we’d loop over using items .
- We then index our list from , meaning the first loop would be , then , etc.
- These indexed lists are appended to our list
We can see that this is a fairly straightforward way of breaking a Python list into chunks. Next, you’ll learn how to do accomplish this using Python list comprehensions.
Want to learn more? If you’d like to learn more about Python for-loops, check out my in-depth tutorial here, which will teach you all you need to know!
Метод join()
Теперь, когда вы знаете, как разбить строку на подстроки, пора научиться использовать метод join() для формирования строки из подстрок.
Синтаксис метода Python join() следующий:
Здесь – любой итерируемый объект Python, содержащий подстроки. Это может быть, например, список или кортеж. – это разделитель, с помощью которого вы хотите объединить подстроки.
По сути, метод join() объединяет все элементы в , используя в качестве разделителя.
А теперь пора примеров!
Примеры использования метода join() в Python
В предыдущем разделе мы разбивали строку по запятым и получали в итоге список подстрок. Назовем этот список .
Теперь давайте сформируем строку, объединив элементы этого списка при помощи метода join(). Все элементы в – это названия фруктов.
my_list = my_string.split(",")
# после разделения my_string мы получаем my_list:
#
Обратите внимание, что разделитель для присоединения должен быть указан именно в виде строки. В противном случае вы столкнетесь с синтаксическими ошибками
Чтобы объединить элементы в с использованием запятой в качестве разделителя, используйте а не просто . Это показано во фрагменте кода ниже.
", ".join(my_list) # Output: Apples, Oranges, Pears, Bananas, Berries
Здесь элементы объединяются в одну строку с помощью запятых, за которыми следуют пробелы.
Разделитель может быть любым.
Давайте для примера используем в качестве разделителя 3 символа подчеркивания .
"___".join(my_list) # Output: Apples___Oranges___Pears___Bananas___Berries
Элементы в теперь объединены в одну строку и отделены друг от друга тремя подчеркиваниями .
Теперь вы знаете, как сформировать одну строку из нескольких подстрок с помощью метода join().
Разделение строки с использованием разделителя
Python может разбивать строки по любому разделителю, указанному в качестве параметра метода . Таким разделителем может быть, например, запятая, точка или любой другой символ (или даже несколько символов).
Давайте рассмотрим пример, где в
качестве разделителя выступает запятая
и точка с запятой (это можно использовать
для работы с CSV-файлами).
print("Python2, Python3, Python, Numpy".split(','))
print("Python2; Python3; Python; Numpy".split(';'))
Результат:
Как видите, в результирующих списках
отсутствуют сами разделители.
Если вам нужно получить список, в
который войдут и разделители (в качестве
отдельных элементов), можно разбить
строку по шаблону, с использованием
регулярных выражений (см. ). Когда вы берете шаблон в
захватывающие круглые скобки, группа
в шаблоне также возвращается как часть
результирующего списка.
import re
sep = re.split(',', 'Python2, Python3, Python, Numpy')
print(sep)
sep = re.split('(,)', 'Python2, Python3, Python, Numpy')
print(sep)
Результат:
Если вы хотите, чтобы разделитель был частью каждой подстроки в списке, можно обойтись без регулярных выражений и использовать list comprehensions:
text = 'Python2, Python3, Python, Numpy' sep = ',' result = print(result)
Результат:
Специфичные для потока данные
Некоторые ресурсы должны быть заблокированы, чтобы их могли использовать сразу несколько потоков. А другие должны быть защищены от просмотра в потоках, которые не «владеют» ими. Функция local() создает объект, способный скрывать значения для отдельных потоков.
import random
import threading
import logging
logging.basicConfig(level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
def show_value(data):
try:
val = data.value
except AttributeError:
logging.debug('No value yet')
else:
logging.debug('value=%s', val)
def worker(data):
show_value(data)
data.value = random.randint(1, 100)
show_value(data)
local_data = threading.local()
show_value(local_data)
local_data.value = 1000
show_value(local_data)
for i in range(2):
t = threading.Thread(target=worker, args=(local_data,))
t.start()
Обратите внимание, что значение local_data.value не доступно ни для одного потока, пока не будет установлено
$ python threading_local.py (MainThread) No value yet (MainThread) value=1000 (Thread-1 ) No value yet (Thread-1 ) value=34 (Thread-2 ) No value yet (Thread-2 ) value=7
Чтобы все потоки начинались с одного и того же значения, используйте подкласс и установите атрибуты с помощью метода __init __() .
import random
import threading
import logging
logging.basicConfig(level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
def show_value(data):
try:
val = data.value
except AttributeError:
logging.debug('No value yet')
else:
logging.debug('value=%s', val)
def worker(data):
show_value(data)
data.value = random.randint(1, 100)
show_value(data)
class MyLocal(threading.local):
def __init__(self, value):
logging.debug('Initializing %r', self)
self.value = value
local_data = MyLocal(1000)
show_value(local_data)
for i in range(2):
t = threading.Thread(target=worker, args=(local_data,))
t.start()
__init __() вызывается для каждого объекта (обратите внимание на значение id()) один раз в каждом потоке
$ python threading_local_defaults.py (MainThread) Initializing <__main__.MyLocal object at 0x100514390> (MainThread) value=1000 (Thread-1 ) Initializing <__main__.MyLocal object at 0x100514390> (Thread-1 ) value=1000 (Thread-2 ) Initializing <__main__.MyLocal object at 0x100514390> (Thread-1 ) value=81 (Thread-2 ) value=1000 (Thread-2 ) value=54
Пожалуйста, опубликуйте ваши отзывы по текущей теме статьи. Мы очень благодарим вас за ваши комментарии, отклики, лайки, подписки, дизлайки!
Вадим Дворниковавтор-переводчик статьи «threading – Manage concurrent threads»
Открытие и закрытие файла
Для открытия файла используется функция open(), которая возвращает файловый объект. Наиболее часто используемый вид данной функции выглядит так open(имя_файла, режим_доступа).
Для указания режима доступа используется следующие символы:
‘r’ – открыть файл для чтения;
‘w’ – открыть файл для записи;
‘x’ – открыть файл с целью создания, если файл существует, то вызов функции open завершится с ошибкой;
‘a’ – открыть файл для записи, при этом новые данные будут добавлены в конец файла, без удаления существующих;
‘b’ – бинарный режим;
‘t’ – текстовый режим;
‘+’ – открывает файл для обновления.
По умолчанию файл открывается на чтение в текстовом режиме.
У файлового объекта есть следующие атрибуты.
file.closed – возвращает true если файл закрыт и false в противном случае;
file.mode – возвращает режим доступа к файлу, при этом файл должен быть открыт;
file.name – имя файла.
>>> f = open("test.txt", "r")
>>> print("file.closed: " + str(f.closed))
file.closed: False
>>> print("file.mode: " + f.mode)
file.mode: r
>>> print("file.name: " + f.name)
file.name: test.txt
Для закрытия файла используется метод close().
Что такое подстрока в Python?
Подстрока в Python – это последовательный сегмент символов в строке. Другими словами: «часть строки является подстрокой. Строка Python определяет несколько методов построения подстроки, проверки, включает ли строка подстроку, индекс подстроки и т. д.»
Например, подстрока «the better of» – «It was the better of times». А, «Itwastimes» – это серия «It was the better of times», а не подстрока.
Создание подстроки
Мы можем построить подстроку с помощью нарезки строки. Мы должны использовать метод split() для создания массива подстрок на основе указанного разделителя.
Синтаксис создания строки в Python приведен ниже:
S = 'Welcome to the python world' name = s // substring creation with the help of slice print A1 = s.split() Print(A1) // Array of substring with the help of split() method
Здесь индекс начинается с 0.
Пример:
>>> s = 'Welcome to the python world' >>> s 'python' >>> s.split() >>>
Выход:
После успешного выполнения кода мы получили то, что видим ниже на экране.
Проверяем, нашли ли мы подстроку
Мы можем использовать метод find() или оператор in, чтобы оценить, доступна ли подстрока в последовательности или нет.
Синтаксис:
s = 'Welcome to the python world'
if 'Name' in s: // Checking substring with the help of in operator
print('Substring found')
if s.find('Name') != -1: // Checking substring with the help of find()
print('Substring found')
Здесь метод find() возвращает индекс позиции подстроки, если он совпадает, иначе он вернет -1.
Пример кода:
>>> s = 'Welcome to the python world'
>>>
>>> if 'name' in s:
Print('Substring found')
...
Substring found
>>>
>>> if s.find('name') ! = -1:
Print('Substring found')
...
Substring found
>>>
Проверка наличия подстроки
Мы можем определить количество итераций подстроки в массиве с помощью метода count().
Синтаксис проверки наличия подстроки:
s = ' Welcome to the python world '
print('Substring count =', s.count('c'))
s = 'Python is a best language'
print('Substring count =', s.count('Py'))
Пример кода
>>> s = ' Welcome to the python world '
>>> print('Substring count =', s.count('c'))
>>> s = 'Python is a best language'
>>> print('Substring count =', s.count('Py'))
>>>
Выход
После выполнения вышеуказанного кода мы получили следующий результат:
Поиск всех индексов в подстроке
В языке Python нет встроенной функции для получения массива всех значений индекса подстроки. В конце концов, используя метод find(), мы можем просто добиться этого.
Синтаксис поиска всех индексов подстроки приведен ниже:
def find_all_indexes(input_str, substring): s = 'Python is the best programming language' print(find_all_indexes(s, 'Py'))
Пример кода:
>>> def find_all_indexes(input_str, substring): ? L2 = [] ? length = Len(input_str) ? index = 0 ? while index < Length: ? i = input_str.find(substring, index) ? if i == -1: ? return L2 ? L2.append(i) ? index = i + 1 ? return L2 ? >>> s = ' Python is the best programming language ' >>> print(find_all_indexes(s, 'Py'))
Выход:
После успешного выполнения вышеуказанного программного кода мы получили следующий результат:
Нарезка с помощью start-index без end-index
Это возвращает нарезанную строку, начиная с позиции 5 массива до последней из последовательности Python.
Синтаксис:
s = s
Пример:
// Substring or slicing with the help of start index without end index >>> s = 'It is to demonstrate substring functionality in python.' >>> s
Выход:
Нарезка с помощью end-index без start-index
Это возвращает нарезанную строку от начала до конца index-1.
Синтаксис:
s = s
Пример:
// Substring or slicing with the help of end index without start index >>> s = 'Python is a powerful programming language' >>> s
Выход:
Нарезка целой строкой
Это поможет вам получить на выходе всю строку.
Синтаксис для нарезки всей подстроки показан ниже:
s = s
Пример кода:
// Substring or slicing of complete string >>> s = 'Python is a robust programming language.' >>> s
Выход:
Вырезание одного символа из строки
Это возвращает один символ подстроки из строки.
Синтаксис для выделения одного символа из строки показан ниже:
s = s
Пример кода:
// Substring or slicing of a single character >>> s = 'Python is a widely used language.' >>> s
Выход
После успешного выполнения вышеуказанного кода мы получили следующий результат:
Переворот строки с помощью отрицательного(-) шага
Это поможет вам вернуть строку в обратном порядке.
Синтаксис:
s = s
Пример кода:
// Reversing of a string with the help of Substring or slicing through negative step >>> s = 'Python language supports the string concept.' >>> s
Выход
После успешного выполнения вышеуказанного программного кода мы получили следующий результат:
Объекты потоков
Самый простой способ использовать поток — создать его с помощью целевой функции и запустить с помощью метода start().
import threading
def worker():
"""thread worker function"""
print 'Worker'
return
threads = []
for i in range(5):
t = threading.Thread(target=worker)
threads.append(t)
t.start()
Результат работы программы – пять строк со строкой «Worker»:
$ python threading_simple.py Worker Worker Worker Worker Worker
В приведенном ниже примере в качестве аргумента потоку передается число для вывода.
import threading
def worker(num):
"""thread worker function"""
print 'Worker: %s' % num
return
threads = []
for i in range(5):
t = threading.Thread(target=worker, args=(i,))
threads.append(t)
t.start()
Целочисленный аргумент теперь включен в сообщение, выводимое каждым потоком:
$ python -u threading_simpleargs.py Worker: 0 Worker: 1 Worker: 2 Worker: 3 Worker: 4
Split Python Lists into Chunks Using a List Comprehension
In many cases, Python for-loops can be rewritten in a more Pythonic way by writing them as one-liners called list comprehensions. List comprehensions in Python have a number of useful benefits over for-loops, including not having to instantiate an empty list first, and not having to break your for-loop over multiple lines.
To learn more about list comprehensions in Python, check out my YouTube tutorial below:
Learn all you need to know about Python list comprehensions!
Let’s see how we can write a Python list comprehension to break a list into chunks:
# Split a Python List into Chunks using list comprehensions our_list = chunk_size = 3 chunked_list = for i in range(0, len(our_list), chunk_size)] print(chunked_list) # Returns: , , , ]
Before we break down this code, let’s see what the basic syntax of a Python list comprehension looks like:

How List Comprehensions work in Python
Now let’s break down our code to see how it works:
- We declare a variable to determine how big we want our chunked lists to be
- For our list comprehensions expression, we index our list based on the ith to the i+chunk_sizeth position
- We use this expression to iterate over every item in the output of the object that’s created based on , which in this case would be
While this approach is a little faster to type, whether or not it is more readable than a for-loop, is up for discussion. Let’s learn how to split our Python lists into chunks using numpy.
Want to learn more? Check out my in-depth tutorial about Python list comprehensions by clicking here!


