How to restore a website from the web archive
Содержание:
- Installation Method 1: The Easy Method
- Больше информации о Wayback Machine
- Best Internet Wayback Machine Alternative
- Which Sites Are Cataloged?
- Как использовать Wayback Machine
- Качаем сайт с web.archive.org
- Как избавиться от рекламы WAYBACK MACHINE в Chrome/Firefox/Internet Explorer/Edge?
- Инструкция по ручному удалению рекламного вируса WAYBACK MACHINE
- Origins, growth and storage
- Method 2: using FTP
- Reasons for using the Wayback Downloader
- Итак, приступим:
- И все же автоматика лучше!
- Как скачать все изменения страницы из веб-архива
- Installing the Latest Build
Installation Method 1: The Easy Method
- 1. Register the domain with your hosting company. If you have registered the domain elsewhere, then create an add-on domain in the cPanel of your hosting company. Here is a tutorial from GoDaddy, that explains how to create an add-on domain.
- 2. Login to cPanel and go to «File Manager», as shown in the picture below:
- 3. Browse to the root folder of your domain. Normally this is /public_html/example.com, as shown below. For this tutorial, we used the domain buy-searchengine.com. Then click on «Upload»:
- 4. Then upload the ZIP file, as shown in the picture below. This assumes that you have already downloaded the ZIP file from waybackmachinedownloader.com.
- 5. Extract the ZIP file:
- 6. That’s it! If you purchased the domain and the hosting from different companies, then you still have to change the name servers at your domain registrar, and change them with the name servers from your hosting company.
- 7. If you want to edit the front page, then go to the File Manager and edit the index.html file, using a text editor. You might find it easier to copy part of that file and edit it with an online HTML editor.
WordPress installation instructions
If you also ordered the WordPress conversion, then wait until one of our developers sends you a ZIP file with WordPress files. This might take up to 48 hours after the scraping has finished.
It might sound strange, but you can not use a «Managed WordPress» hosting package. It doesn’t provide enough rights to edit the database. However, any cheap shared hosting package works, as long as it uses Apache. You can get this from providers such as Godaddy or Hostgator. We recommend Namecheap because it’s good enough and costs only $35/year.
- 8. Upload and extract this ZIP file as described above in step 2-6, in the same way as you would do with a zip file with HTML files. In the ZIP file there is also a folder called «database». If you want to save some time, you can remove this folder from the ZIP file, because you do not need to upload it. You will need the folder later though.
- 9. Go to your cPanel and open «MySQL Databases». Create a new database. You can name it anything, but in our example we use the name of our domain. You will need this name later, so pick something easy.
- 10. Create a new user and password. The name can be anything, but you’ll need it later.
- 11. Add this user to the database. Give your new user access to all privileges.
- 12. On your own computer, unzip the folder called «database». For example, unzip this to your desktop.
- 13. Go to your cPanel and open «phpMyAdmin».
- 14. First select your database on the left panel, by clicking on it. Then click «import» and import the database. This is the .sql file in the folder called «database».
- 15. Go to File Manager and find the file called «wp-config.php». Open this file in a text editor.
-
16. In wp-config.php, edit the database name, database user name and database password. Use the values that you created in step 9 and 10.
With some hosts you also have to change the hostname, but with 95%+ of hosting companies, you can leave this as «localhost». For example with iPage it is «UsernameOfYourAccount.ipagemysql.com» - 17. That’s it! Your WordPress website should now work.
Больше информации о Wayback Machine
Страницы, отображаемые на Wayback Machine, отражают только те, которые были заархивированы службой, а не частоту обновления страницы. Другими словами, в то время как одна страница, которую вы посетили, могла обновляться один раз в день в течение целого месяца, Wayback Machine могла заархивировать ее только несколько раз или не делать вообще.
Не каждая существующая веб-страница архивируется Wayback Machine. Они не добавляют веб-сайты чата или электронной почты в свой архив и не могут включать веб-сайты, которые явно блокируют Wayback Machine, веб-сайты, которые скрыты за паролями, и другие частные сайты, которые не являются общедоступными.
Wayback Machine будет захватывать URL так часто, как каждые пять минут. Если вы попытаетесь заархивировать идентичную страницу раньше, вы получите ошибку.
Если у вас есть дополнительные вопросы о Wayback Machine, вы, скорее всего, сможете найти ответы на странице часто задаваемых вопросов Wayback Machine в Интернет-архиве .
Best Internet Wayback Machine Alternative
Let us begin…
Contents
ScreenShots is the another best alternative to the Wayback machine. As its name it works, screenshots just take a snapshot of the websites and save it to the database so you can only access the snapshot. You can not access the code and other things like its destination link and more.
Features:
- Captures screenshots instead of copying domain code
- Easy to use Interface
- Shows complete WHOIS record of the domain ID
Archive.is is one of the best Wayback machine alternatives. The archive comes with great functionality which can not offer others. The archive is getting so much popularity on the internet because of its function, user-friendly and easy navigation. When you visit Archive.is you find two search bar. Archive.is gives you the power to access the content of any websites and also the screenshots of that website.
Features:
- Archives the screenshot and code of a web page
- Has an enormous database
- Allows you to share & download results
- You can archive any website, anytime
iTools is also a certain website and provides you all the information of any domain name. This site accesses the Alexa database. It will also tell you the domain popularity, traffic, and competitors of the website.
iTools is a slightly different tool from other wayback machine tools in the list as it doesn’t provide any archive option on its homepage. However, you can access it in another way, and to do that, you first need to click the “Internet” tab from its homepage and then on “Website” you need to check the archive for. It also shows you everything important about your competitor to help boost your business.
Features:
- Shows up all information related to domain
- Used to boost your business
Features:
- Shows up detailed information of a domain
- Display transparent results related to your competitor
This site offers you lots of functionality; you can use this to extend your business. You can also use archive content of the website also, and this helps you see your competitors. Moreover, you do not need any special skills. You just need to sign in and get started.
Features:
- Has Online Marketing Tools
- Let’s you archive website content
Editor’s Recommended Alternatives
- Best Dropbox Alternative
- Best Free Game like Minecraft
- Best VLC Alternative
- Best Clash of Clans Alternatives Games
- Best Kindle Alternative eBook Readers
Conclusion
So, readers, These are the Best Wayback Machine Alternative Sites, totally trusted and working so you can use any of them. With the help of these sites, you can check the site history, content and how a website look in past or any deleted content also you can access. If you find any other site better than these, let’s know through comment section.
Edited By: Abhiyanshu Satvat
Which Sites Are Cataloged?
Many popular websites are automatically archived by the Wayback Machine. However, you can use the Wayback Machine to manually archive virtually any page. Websites are often abandoned or changed completely, so the Wayback machine acts as a way to preserve the culture of the Internet by keeping a digital “hard copy” of a website. Be aware that text and images are left intact; however, some outbound links and embedded items (e.g. videos) are not.
It is important to note that The Wayback Machine only scans and archives public sites. This means that password protected sites or ones located on private servers cannot be archived. In addition, if a website prohibits search engines from including it in search results, Wayback Machine will not be able to archive it.
Как использовать Wayback Machine
На Wayback Machine есть несколько различных функций, но наиболее выдающимся является инструмент поиска, позволяющий определить, как веб-сайт выглядел ранее.
СМОТРЕТЬ АРХИВ ВЕБ-СТРАНИЦЫ
-
Посетите Wayback Machine на веб-сайте интернет-архива.
-
Выполните поиск Wayback Machine, вставив или введя URL-адрес в текстовое поле.
-
Используйте график в верхней части календаря, чтобы выбрать год.
-
Наведите указатель мыши на любой из кругов в календаре на этот год, а затем выберите конкретное время, чтобы просмотреть снимок, сделанный в то время.
Только дни, выделенные кружком, содержат архив. Большие круги показывают, что в этот день было сделано больше снимков, чем дни, представленные меньшим кругом.
-
Просмотрите архивную веб-страницу, как если бы она была сегодня. Вы можете нормально переходить по ссылкам (если есть архивы для этих страниц), загружать файлы и т. Д.
-
Чтобы перейти к другому дню для того же URL-адреса, используйте временную шкалу вверху.
ПОСМОТРЕТЬ ИЗМЕНЕНИЯ МЕЖДУ ДВУМИ ДАТАМИ
Область « Изменения» веб-сайта, которую вы видите после использования инструмента поиска Wayback Machine, позволяет сравнивать две даты одного и того же веб-сайта, чтобы наглядно увидеть, что изменилось между датами.

СМОТРИТЕ РЕЗЮМЕ САЙТА
Wayback Machine включает в себя раздел « Сводка » для URL, который вы ищете, который детализирует различные документы на странице между двумя годами. Инструмент дает количество файлов HTML , изображений и других типов файлов.

Качаем сайт с web.archive.org
Процесс восстановления сайта из веб-архива я покажу на примере сайта 1mds.ru. Я не знаю что это за сайт, я всего лишь знаю что у него в архиве много страниц, а это значит что сайт не только существовал, но с ним работали.
Для того, что бы открыть архив нужного сайта, нам необходимо пройти по такой вот ссылке:
http://web.archive.org/web/*/1mds.ru
На 24 ноября 2018 года, при открытии этой ссылки я обнаружил вот такую картину:
Как видите на главной зафиксировались результаты экспериментов с программной частью. Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:
Кликаем левую стрелку ибо правая все равно не активна, и кликаем до тех пор, пока не увидим главную страницу сайта. Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Вот мы можем видеть что 2 мая 2018-го бот обнаружил сообщение о том, что домен направлен на другой сайт:
Классика жанра, регистрируешь домен и направляешь его на существующий дабы не тратить лимит тарифа на количество сайтов.
А до этого, 30 марта, там был вообще блог про шитье-вязание.
Долистал я до 23 октября 2017-го и вижу уже другое содержимое:
Тут мы видим уже материалы связанные с воспитанием ребенка. Листаем дальше, там вообще попадается период когда на домене была всего одна страница с рекламой:
А вот с 25 апреля 2011 по 10 сентября 2013-го там был сайт связанный с рекламой. В общем нам нужно определиться какой из этих периодов мы хотим восстановить. К примеру я хочу восстановить блог про шитье-вязание. Мне необходимо найти дату его появления и дату когда этот блог был замечен там последний раз.
Я нашел последнюю дату, когда блог был на домене и скопировал ссылку из адресной строки:
http://web.archive.org/web/20180330034350/http://1mds.ru:80/
Мне нужны цифры после web/, я их выделил красным цветом. Это временная метка, когда была сделана копия. Теперь мне нужно найти первую копию блога и также скопировать из URL временную метку. Теперь у нас есть две метки с которой и до которой нам нужна копия сайта. Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
- sudo apt install ruby
- sudo gem install wayback_machine_downloader
После чего останется запустить скачивание сайта. Делается это вот такой командой:
wayback_machine_downloader -f20171223224600 -t20180330034350 1mds.ru
Таким образом мы скачаем архив с 23/12/2017 по 30/03/2018. Файлы сайта будут сохранены в домашней директории в папке «websites/1mds.ru». Теперь остается закинуть файлы на хостинг и радоваться результату.
Как избавиться от рекламы WAYBACK MACHINE в Chrome/Firefox/Internet Explorer/Edge?
Я на этом деле конечно уже собаку съел, так что трудностей не возникло. Но прежде, чем закидывать вас инструкциями, давайте повторим сами себе, с чем имеем дело.
Это обычный рекламный вирус, коих стало пруд пруди. И имен у него много: может быть просто WAYBACK MACHINE, а может с дописанной строкой после имени домена WAYBACK MACHINE. В любом случае вирус закидывает вас рекламой, и про ваше любимое казино Вулкан не забывает. До кучи он заражает и свойства ярлыков браузеров.
Кроме того, вирус обожает создавать расписания для запуска самого себя, чтоб жизнь медом не казалась. В результате его деятельности вы вполне можете случайно кликнуть на нежелательную ссылку и скачать себе что-нибудь более серьезное.
Поэтому данный рекламный вирус следует удалять как можно быстрее. Ниже я приведу инструкции по избавлению от вируса WAYBACK MACHINE, но рекомендую использовать автоматизированный вариант.
Инструкция по ручному удалению рекламного вируса WAYBACK MACHINE
Для того, чтобы самостоятельно избавиться от рекламы WAYBACK MACHINE, вам необходимо последовательно выполнить все шаги, которые я привожу ниже:
- Поискать «WAYBACK MACHINE» в списке установленных программ и удалить ее.
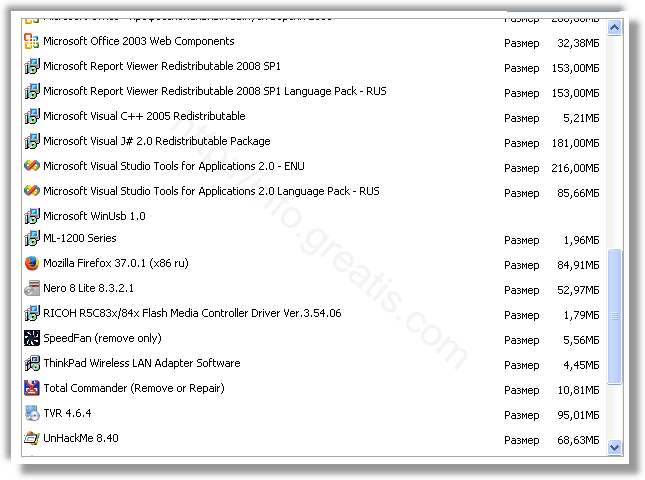
Открыть Диспетчер задач и закрыть программы, у которых в описании или имени есть слова «WAYBACK MACHINE». Заметьте, из какой папки происходит запуск этой программы. Удалите эти папки.
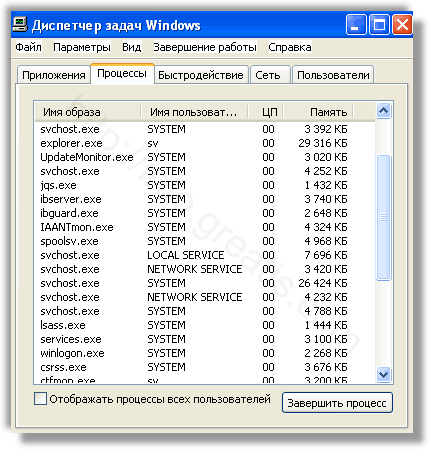
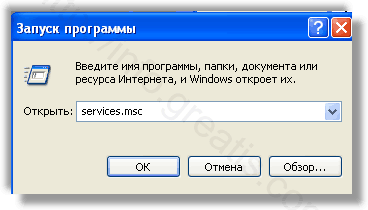
Запретить вредные службы с помощью консоли services.msc.
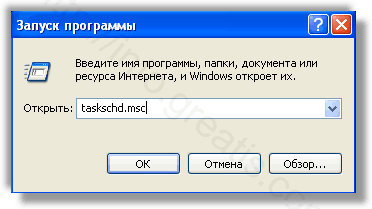
Удалить “Назначенные задания”, относящиеся к WAYBACK MACHINE, с помощью консоли taskschd.msc.
С помощью редактора реестра regedit.exe поискать ключи с названием или содержащим «WAYBACK MACHINE» в реестре.
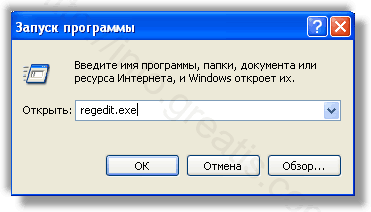
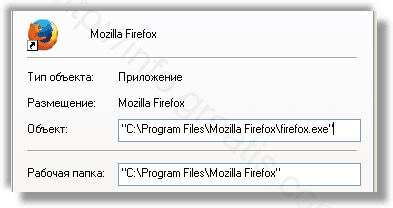
Проверить ярлыки для запуска браузеров на предмет наличия в конце командной строки дополнительных адресов Web сайтов и убедиться, что они указывают на подлинный браузер.
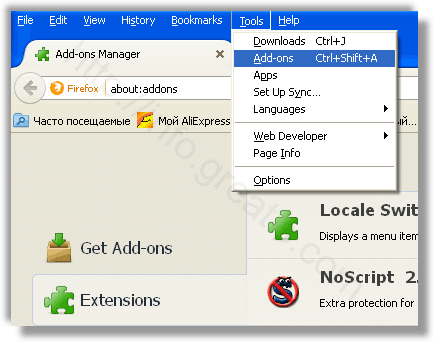
Проверить плагины всех установленных браузеров Internet Explorer, Chrome, Firefox и т.д.
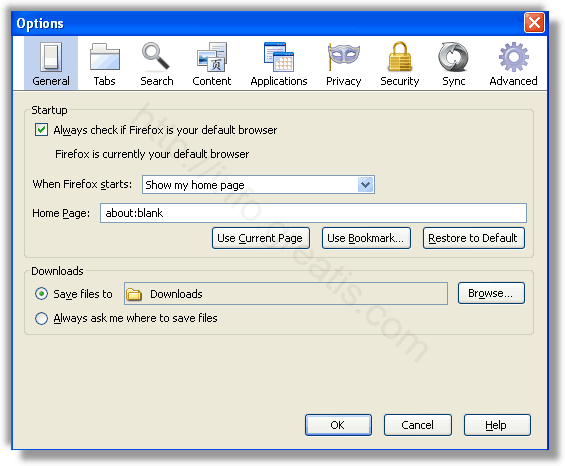
Проверить настройки поиска, домашней страницы. При необходимости сбросить настройки в начальное положение.
Очистить корзину, временные файлы, кэш браузеров.
Origins, growth and storage
In 1996, Brewster Kahle, with Bruce Gilliat, developed software to crawl and download all publicly accessible World Wide Web pages, the Gopher hierarchy, the Netnews bulletin board system, and downloadable software. The information collected by these «crawlers» does not collect all the information available on the Internet since much of the data is restricted by the publisher or stored in databases that are not accessible. These «crawlers» also respect the robots exclusion standard for websites wishing to opt-out of appearing in search results or being cached. To overcome inconsistencies in partially cached websites, Archive-It.org was developed in 2005 by the Internet Archive as a means of allowing institutions and content creators to voluntarily harvest and preserve collections of digital content, and create digital archives.
The digital library grew and grew and grew. But a lot of people knew about it. Information was kept on digital tape for five years, with Kahle occasionally allowing researchers and scientists to tap into the clunky database. When the archive reached its five-year anniversary, it was unveiled and opened to the public in a ceremony at the University of California-Berkeley.
Snapshots usually become available more than 6 months after they are archived, or in some cases, even later, 24 months or longer. The frequency of snapshots is variable, so not all tracked web site updates are recorded. Intervals of several weeks or years sometimes occur.
After August 2008 sites had to be listed on the Open Directory in order to be included. According to Jeff Kaplan of the Internet Archive in November 2010, other sites were still being archived, but more recent captures would only become visible after the next major indexing, an infrequent operation.
As of 2009 the Wayback Machine contained approximately three petabytes of data and was growing at a rate of 100 terabytes each month; the growth rate reported in 2003 was 12 terabytes/month. The data is stored on PetaBox rack systems manufactured by Capricorn Technologies.
In 2009 the Internet Archive migrated its customized storage architecture to Sun Open Storage, and hosts a new datacenter in a Sun Modular Datacenter on Sun Microsystems’ California campus.
In 2011 a new, improved version of the Wayback Machine, with an updated interface and fresher index of archived content, was made available for public testing.
In March 2011 it was said on the Wayback Machine forum that «The Beta of the new Wayback Machine has a more complete and up-to-date index of all crawled materials into 2010, and will continue to be updated regularly. The index driving the classic Wayback Machine only has a little bit of material past 2008, and no further index updates are planned, as it will be phased out this year.»
Method 2: using FTP
This Tutorial explains how you can recover a website from the Waybackmachine. It also explains exactly how you can upload the files with Cpanel and FTP.
- 1. Download the .zip file with all the HTML files. Extract the files (unzip) to a folder of your choice.
- 2. You need to transfer the files to the server using FTP software. If you don’t have an FTP client already, then we recommend FileZilla: https://filezilla-project.org/
-
3. If you don’t already have an FTP account at your hosting provider, then create one. If your host uses cPanel, then find the icon that says «FTP Accounts» (most hosting providers use cPanel: Hostgator, Godaddy, BlueHost : all of them use cPanel)
cPanel example:It’s usually easier to create an FTP account when adding a domain to your hosting:
- 4. Find the IP address of your server. In GoDaddy you can find your IP address on the hosting dashboard:
-
5. We use FileZilla for Windows in this guide, but you can also download it for Apple computers.
You should now have an FTP account and know your IP address. Open an FTP client. We use FileZilla in this guide.
— Fill in your username and password.
— The username should be
— Host should be the IP address of your server, that will host the Wayback files.
— Port can be blank.
— Press Quickconnect to connect. - 6. Now select all the files and move them to the remote site:
- 7. Your site should work now.
Reasons for using the Wayback Downloader
What possible reasons can you have to download sites from the Wayback Machine?
- Missed hosting payments. Let’s say you’re super responsible webmaster. You always update and keep fresh content. You do security updates. You’re on top of things. But one day, you visit your website and all your content is gone! It’s in this moment that you remember that you forgot to change that credit card that was linked to your hosting account. Now all your content is gone! Dashed away by one false move..or is it? Enter our web Archive download bot. With a few simple clicks, you can be on your way to restoring a whole website — exactly like it used to be.
- Nostalgia. Maybe you played a computer game as a teenager or you used to frequently visit some hobby website. Many of these websites change or go offline, but with an archive.org download order, you can recover all your nostalgic memories.Simply go to our wayback machine download site and create your own web.archive.org download. This includes your whole website, up to 10 levels deep, which means all pages that are 10 clicks away from the front page.
- Your site was hacked. What if a more sinister plot involving a hacker compromising the security of your site arises? He’s hijacked your site, and now all your content has been deleted and replaced with ads for his own benefit. Not to worry! We have you covered with a nice Wayback machine download of your website, as it was before disaster struck.
- Legal evidence. Should you ever find yourself embroiled in a legal battle over whatever the issue may be, The Wayback Downloader can help here too. Make a copy of the web archive data for use as evidence in lawsuits. For example, patent law and evidence of prior art. The Wayback Machine accepts removal requests, so it’s a good idea to have your own copy in case the website disappears from the web archive.
- Take content from bankrupt competitor. What if one of your biggest competitors has gone out of business, and with their exit from the business they also took down their website? Remember the URL? Voila! You’ve got yourself a ton of useable information to populate your new site with one less competitor to worry about. Basically, this can be for any site in your industry that was taken offline.
- For recovering expired content. Sometimes you have good expired content — perhaps you found it with our service or with software like the Expired Article Hunter. Let’s say you have a good PBN domain with high metrics, and you have another domain with good expired content. Now you can merge the two domains and rebuilding the expired content on the domain with high metrics. It’s one of the quickest and best methods to build a PBN
- Use it as an alternative to httrack. Httrack is software to scrape live websites, but it doesn’t do a very good job at scraping the internet archive. We rebuild websites as they once were, while httrack simply copies a complete site, including all the headers and archive URLs.
Итак, приступим:
Шаг 1. Установите UnHackMe (1 минута).
- Скачали софт, желательно последней версии. И не надо искать на всяких развалах, вполне возможно там вы нарветесь на пиратскую версию с вшитым очередным мусором. Оно вам надо? Идите на сайт производителя, тем более там есть бесплатный триал. Запустите установку программы.
Затем следует принять лицензионное соглашение.
И наконец указать папку для установки. На этом процесс инсталляции можно считать завершенным.
Шаг 2. Запустите поиск вредоносных программ в UnHackMe (1 минута).
- Итак, запускаем UnHackMe, и сразу стартуем тестирование, можно использовать быстрое, за 1 минуту. Но если время есть — рекомендую расширенное онлайн тестирование с использованием VirusTotal — это повысит вероятность обнаружения не только перенаправления на WAYBACK MACHINE, но и остальной нечисти.
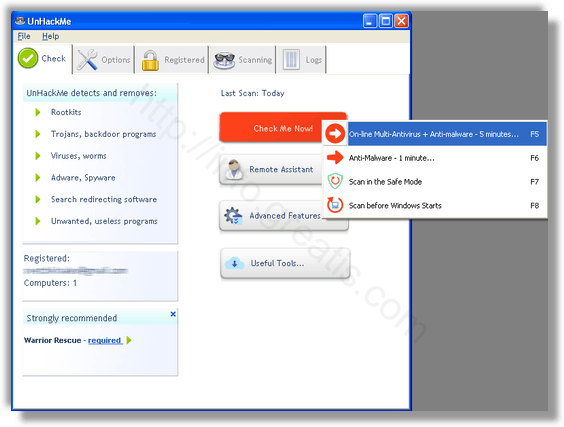
Мы увидим как начался процесс сканирования.
Шаг 3. Удалите вредоносные программы (3 минуты).
- Обнаруживаем что-то на очередном этапе. UnHackMe отличается тем, что показывает вообще все, и очень плохое, и подозрительное, и даже хорошее. Не будьте обезьяной с гранатой! Не уверены в объектах из разряда “подозрительный” или “нейтральный” — не трогайте их. А вот в опасное лучше поверить. Итак, нашли опасный элемент, он будет подсвечен красным. Что делаем, как думаете? Правильно — убить! Ну или в английской версии — Remove Checked. В общем, жмем красную кнопку.
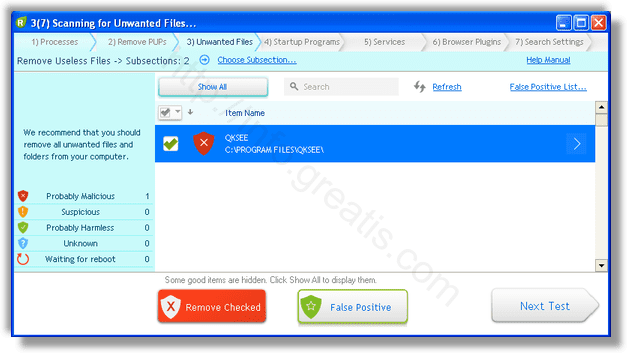
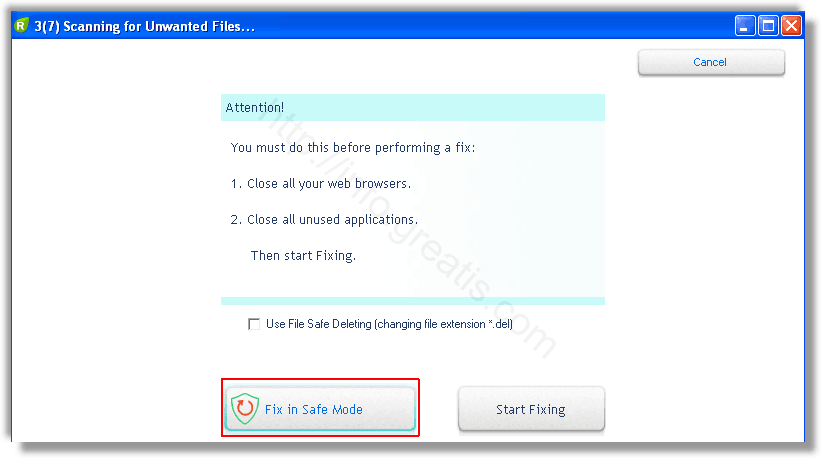
После этого вам возможно будет предложено подтверждение. И приглашение закрыть все браузеры. Стоит прислушаться, это поможет.
В случае, если понадобится удалить файл, или каталог, пожалуй лучше использовать опцию удаления в безопасном режиме. Да, понадобится перезагрузка, но это быстрее, чем начинать все сначала, поверьте.
Ну и в конце вы увидите результаты сканирования и лечения.
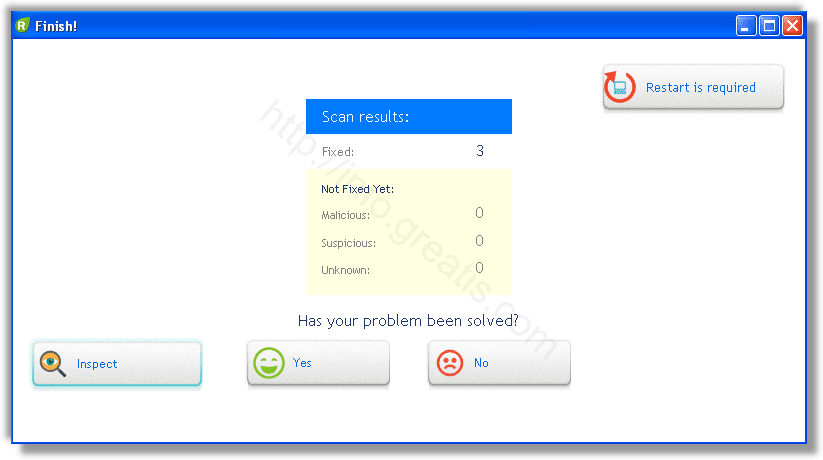
Итак, как вы наверное заметили, автоматизированное лечение значительно быстрее и проще! Лично у меня избавление от перенаправителя на WAYBACK MACHINE заняло 5 минут! Поэтому я настоятельно рекомендую использовать UnHackMe для лечения вашего компьютера от любых нежелательных программ!
И все же автоматика лучше!
Если ручной метод — не для вас, и хочется более легкий путь, существует множество специализированного ПО, которое сделает всю работу за вас. Я рекомендую воспользоваться UnHackMe от Greatis Software, выполнив все по пошаговой инструкции.
UnHackMe выполнит все указанные шаги, проверяя по своей базе, всего за одну минуту.
При этом UnHackMe скорее всего найдет и другие вредоносные программы, а не только редиректор на WAYBACK MACHINE.
При ручном удалении могут возникнуть проблемы с удалением открытых файлов. Закрываемые процессы могут немедленно запускаться вновь, либо могут сделать это после перезагрузки. Часто возникают ситуации, когда недостаточно прав для удалении ключа реестра или файла.
UnHackMe легко со всем справится и выполнит всю трудную работу во время перезагрузки.
И это еще не все. Если после удаления редиректа на WAYBACK MACHINE какие то проблемы остались, то в UnHackMe есть ручной режим, в котором можно самостоятельно определять вредоносные программы в списке всех программ.
Как скачать все изменения страницы из веб-архива
Если вас интересует не весь сайт, а определённая страница, но при этом вам нужно проследить все изменения на ней, то в этом случае используйте программу Waybackpack.
К примеру для скачивания всех копий главной страницы сайта suip.biz, начиная с даты (—to-date 2017), эти страницы должны быть помещены в папку (-d /home/mial/test), при этом программа должна следовать HTTP редиректам (—follow-redirects):
waybackpack suip.biz -d ./suip.biz-copy --to-date 2017 --follow-redirects
Структура директорий:
Чтобы для указанного сайта (hackware.ru) вывести список всех доступных копий в веб-архиве (—list):
waybackpack hackware.ru --list
Installing the Latest Build
First tap on the Code button, Download ZIP, unzip the file in a location where you can find on your computer, then follow the steps below for your browser.
Chrome
- Open Chrome and navigate to in your browser. You can also access this page by clicking on the 3 vertical dots menu on the top-right, hovering over More Tools, then selecting Extensions.
- Turn on the switch next to Developer mode.
- Click the Load unpacked button and select the directory that contains this code.
- Click on the Extensions puzzle-like icon in the toolbar.
- Now click on the Pin icon next to Wayback Machine to pin it.
- Click on the newly added icon.
- Read the terms, then Accept and Enable. Click on the icon again to use the extension.
Firefox
- Open Firefox and navigate to in the browser. You can also access this page by clicking on the hamburger menu on the top-right, select Add-ons, then the Gear Tools button on the top-right, then Debug Add-ons.
- Click This Firefox on the left.
- Click Load Temporary Add-on…
- Open the directory and select any file.
- Click on the newly added icon in the toolbar.
- Read the terms, then Accept and Enable. Click on the icon again to use the extension.
Edge
- Open Edge and navigate to in your browser. You can also access this page by clicking on the 3 horizontal dots menu on the top-right, then clicking Extensions.
- Turn on the switch next to Developer mode.
- Click the Load unpacked button and select the directory that contains this code.
- Click on the newly added icon in the toolbar.
- Read the terms, then Accept and Enable. Click on the icon again to use the extension.
Safari 14+
This will require Xcode to compile from source.
- Open Safari.
- If Develop menu is hidden, go to Preferences > Advanced > check «Show Develop menu in menu bar».
- Then Develop menu > Allow Unsigned Extensions (enter password).
- Open the project file in Xcode. Click Play to run.
- Follow directions in splash window:
- Safari menu > Preferences > Extensions tab.
- Check to activate Wayback Machine.
- Select «Always Allow on Every Website…» button and confirm.
- Click on the newly added icon in the toolbar.
- Read the terms, then Accept and Enable. Click on the icon again to use the extension.


